

python解析之namedtuple函数的用法


【相关推荐:Python3视频教程 】
源码解释:
def namedtuple(typename, field_names, *, rename=False, defaults=None, module=None):
"""Returns a new subclass of tuple with named fields.
>>> Point = namedtuple('Point', ['x', 'y'])
>>> Point.__doc__ # docstring for the new class
'Point(x, y)'
>>> p = Point(11, y=22) # instantiate with positional args or keywords
>>> p[0] + p[1] # indexable like a plain tuple
33
>>> x, y = p # unpack like a regular tuple
>>> x, y
(11, 22)
>>> p.x + p.y # fields also accessible by name
33
>>> d = p._asdict() # convert to a dictionary
>>> d['x']
11
>>> Point(**d) # convert from a dictionary
Point(x=11, y=22)
>>> p._replace(x=100) # _replace() is like str.replace() but targets named fields
Point(x=100, y=22)
"""语法结构:
namedtuple(typename, field_names, *, rename=False, defaults=None, module=None)
- typename: 代表新建的一个元组的名字。
- field_names: 是元组的内容,是一个类似list的[‘x’,‘y’]
命名元组,使得元组可像列表一样使用key访问(同时可以使用索引访问)。
collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类.
创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。
存放在对应字段里的数据要以一串参数的形式传入到构造函数中(注意,元组的构造函数却只接受单一的可迭代对象)。
命名元组还有一些自己专有的属性。最有用的:类属性_fields、类方法 _make(iterable)和实例方法_asdict()。
示例代码1:
from collections import namedtuple # 定义一个命名元祖city,City类,有name/country/population/coordinates四个字段 city = namedtuple('City', 'name country population coordinates') tokyo = city('Tokyo', 'JP', 36.933, (35.689, 139.69)) print(tokyo) # _fields 类属性,返回一个包含这个类所有字段名称的元组 print(city._fields) # 定义一个命名元祖latLong,LatLong类,有lat/long两个字段 latLong = namedtuple('LatLong', 'lat long') delhi_data = ('Delhi NCR', 'IN', 21.935, latLong(28.618, 77.208)) # 用 _make() 通过接受一个可迭代对象来生成这个类的一个实例,作用跟City(*delhi_data)相同 delhi = city._make(delhi_data) # _asdict() 把具名元组以 collections.OrderedDict 的形式返回,可以利用它来把元组里的信息友好地呈现出来。 print(delhi._asdict())
运行结果:

示例代码2:
from collections import namedtuple Person = namedtuple('Person', ['age', 'height', 'name']) data2 = [Person(10, 1.4, 'xiaoming'), Person(12, 1.5, 'xiaohong')] print(data2) res = data2[0].age print(res) res2 = data2[1].name print(res2)
运行结果:

示例代码3:
from collections import namedtuple
card = namedtuple('Card', ['rank', 'suit']) # 定义一个命名元祖card,Card类,有rank和suit两个字段
class FrenchDeck(object):
ranks = [str(n) for n in range(2, 5)] + list('XYZ')
suits = 'AA BB CC DD'.split() # 生成一个列表,用空格将字符串分隔成列表
def __init__(self):
# 生成一个命名元组组成的列表,将suits、ranks两个列表的元素分别作为命名元组rank、suit的值。
self._cards = [card(rank, suit) for suit in self.suits for rank in self.ranks]
print(self._cards)
# 获取列表的长度
def __len__(self):
return len(self._cards)
# 根据索引取值
def __getitem__(self, item):
return self._cards[item]
f = FrenchDeck()
print(f.__len__())
print(f.__getitem__(3))运行结果:

示例代码4:
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) p1 = person('san', 'zhang') print(p1) print('first item is:', (p1.first_name, p1[0])) print('second item is', (p1.last_name, p1[1]))
运行结果:

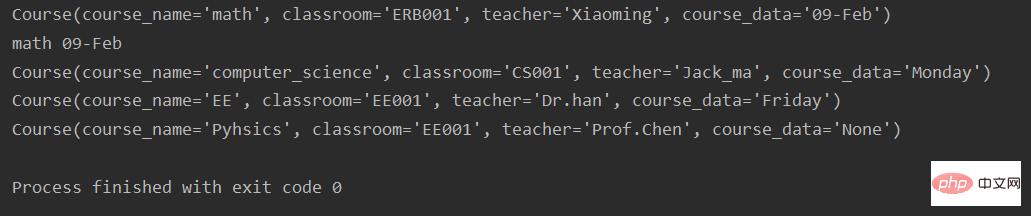
示例代码5: 【_make 从存在的序列或迭代创建实例】
from collections import namedtuple
course = namedtuple('Course', ['course_name', 'classroom', 'teacher', 'course_data'])
math = course('math', 'ERB001', 'Xiaoming', '09-Feb')
print(math)
print(math.course_name, math.course_data)
course_list = [
('computer_science', 'CS001', 'Jack_ma', 'Monday'),
('EE', 'EE001', 'Dr.han', 'Friday'),
('Pyhsics', 'EE001', 'Prof.Chen', 'None')
]
for k in course_list:
course_i = course._make(k)
print(course_i)运行结果:
示例代码6: 【_asdict 返回一个新的ordereddict,将字段名称映射到对应的值】
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) zhang_san = ('Zhang', 'San') p = person._make(zhang_san) print(p) # 返回的类型不是dict,而是orderedDict print(p._asdict())
运行结果:

示例代码7: 【_replace 返回一个新的实例,并将指定域替换为新的值】
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) zhang_san = ('Zhang', 'San') p = person._make(zhang_san) print(p) p_replace = p._replace(first_name='Wang') print(p_replace) print(p) p_replace2 = p_replace._replace(first_name='Dong') print(p_replace2)
运行结果:

示例代码8: 【_fields 返回字段名】
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) zhang_san = ('Zhang', 'San') p = person._make(zhang_san) print(p) print(p._fields)
运行结果:

示例代码9: 【利用fields可以将两个namedtuple组合在一起】
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name']) print(person._fields) degree = namedtuple('Degree', 'major degree_class') print(degree._fields) person_with_degree = namedtuple('person_with_degree', person._fields + degree._fields) print(person_with_degree._fields) zhang_san = person_with_degree('san', 'zhang', 'cs', 'master') print(zhang_san)
运行结果:

示例代码10: 【field_defaults】
from collections import namedtuple person = namedtuple('Person', ['first_name', 'last_name'], defaults=['san']) print(person._fields) print(person._field_defaults) print(person('zhang')) print(person('Li', 'si'))
运行结果:

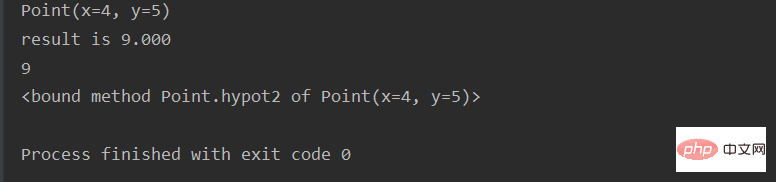
示例代码11: 【namedtuple是一个类,所以可以通过子类更改功能】
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(4, 5)
print(p)
class Point(namedtuple('Point', ['x', 'y'])):
__slots__ = ()
@property
def hypot(self):
return self.x + self.y
def hypot2(self):
return self.x + self.y
def __str__(self):
return 'result is %.3f' % (self.x + self.y)
aa = Point(4, 5)
print(aa)
print(aa.hypot)
print(aa.hypot2)运行结果:
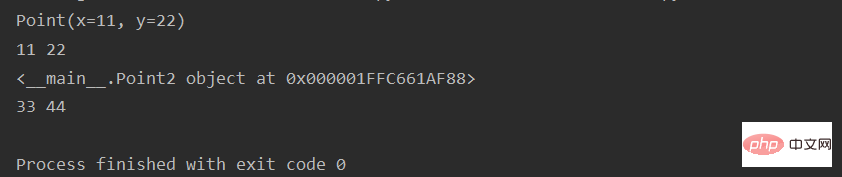
示例代码12: 【注意观察两种写法的不同】
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
p = Point(11, 22)
print(p)
print(p.x, p.y)
# namedtuple本质上等于下面写法
class Point2(object):
def __init__(self, x, y):
self.x = x
self.y = y
o = Point2(33, 44)
print(o)
print(o.x, o.y)运行结果:
【相关推荐:Python3视频教程 】
以上是python解析之namedtuple函数的用法的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
MySQL 有免费的社区版和收费的企业版。社区版可免费使用和修改,但支持有限,适合稳定性要求不高、技术能力强的应用。企业版提供全面商业支持,适合需要稳定可靠、高性能数据库且愿意为支持买单的应用。选择版本时考虑的因素包括应用关键性、预算和技术技能。没有完美的选项,只有最合适的方案,需根据具体情况谨慎选择。
 HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:轻量级、高水平可扩展的Python数据库HadiDB(hadidb)是一个用Python编写的轻量级数据库,具备高度水平的可扩展性。安装HadiDB使用pip安装:pipinstallhadidb用户管理创建用户:createuser()方法创建一个新用户。authentication()方法验证用户身份。fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 mysql workbench 可以连接到 mariadb 吗
Apr 08, 2025 pm 02:33 PM
mysql workbench 可以连接到 mariadb 吗
Apr 08, 2025 pm 02:33 PM
MySQL Workbench 可以连接 MariaDB,前提是配置正确。首先选择 "MariaDB" 作为连接器类型。在连接配置中,正确设置 HOST、PORT、USER、PASSWORD 和 DATABASE。测试连接时,检查 MariaDB 服务是否启动,用户名和密码是否正确,端口号是否正确,防火墙是否允许连接,以及数据库是否存在。高级用法中,使用连接池技术优化性能。常见错误包括权限不足、网络连接问题等,调试错误时仔细分析错误信息和使用调试工具。优化网络配置可以提升性能
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 mysql 无法连接到本地主机怎么解决
Apr 08, 2025 pm 02:24 PM
mysql 无法连接到本地主机怎么解决
Apr 08, 2025 pm 02:24 PM
无法连接 MySQL 可能是由于以下原因:MySQL 服务未启动、防火墙拦截连接、端口号错误、用户名或密码错误、my.cnf 中的监听地址配置不当等。排查步骤包括:1. 检查 MySQL 服务是否正在运行;2. 调整防火墙设置以允许 MySQL 监听 3306 端口;3. 确认端口号与实际端口号一致;4. 检查用户名和密码是否正确;5. 确保 my.cnf 中的 bind-address 设置正确。
 mysql 需要互联网吗
Apr 08, 2025 pm 02:18 PM
mysql 需要互联网吗
Apr 08, 2025 pm 02:18 PM
MySQL 可在无需网络连接的情况下运行,进行基本的数据存储和管理。但是,对于与其他系统交互、远程访问或使用高级功能(如复制和集群)的情况,则需要网络连接。此外,安全措施(如防火墙)、性能优化(选择合适的网络连接)和数据备份对于连接到互联网的 MySQL 数据库至关重要。
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
 如何将 AWS Glue 爬网程序与 Amazon Athena 结合使用
Apr 09, 2025 pm 03:09 PM
如何将 AWS Glue 爬网程序与 Amazon Athena 结合使用
Apr 09, 2025 pm 03:09 PM
作为数据专业人员,您需要处理来自各种来源的大量数据。这可能会给数据管理和分析带来挑战。幸运的是,两项 AWS 服务可以提供帮助:AWS Glue 和 Amazon Athena。
