

浅谈Redis变慢的原因及排查方法


推荐学习:Redis视频教程
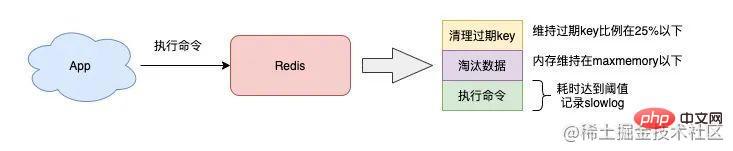
原因1:实例内存达到上限
排查思路
如果你的 Redis 实例设置了内存上限 maxmemory,那么也有可能导致 Redis 变慢。
当我们把 Redis 当做纯缓存使用时,通常会给这个实例设置一个内存上限 maxmemory,然后设置一个数据淘汰策略。而当实例的内存达到了 maxmemory 后,你可能会发现,在此之后每次写入新数据,操作延迟变大了。
导致变慢的原因
当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
这个踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于你配置的淘汰策略:
- allkeys-lru:不管 key 是否设置了过期,淘汰最近最少访问的 key
- volatile-lru:只淘汰最近最少访问、并设置了过期时间的 key
- allkeys-random:不管 key 是否设置了过期,随机淘汰 key
- volatile-random:只随机淘汰设置了过期时间的 key
- allkeys-ttl:不管 key 是否设置了过期,淘汰即将过期的 key
- noeviction:不淘汰任何 key,实例内存达到 maxmeory 后,再写入新数据直接返回错误
- allkeys-lfu:不管 key 是否设置了过期,淘汰访问频率最低的 key(4.0+版本支持)
- volatile-lfu:只淘汰访问频率最低、并设置了过期时间 key(4.0+版本支持)
具体使用哪种策略,我们需要根据具体的业务场景来配置。一般最常使用的是 allkeys-lru / volatile-lru 淘汰策略,它们的处理逻辑是,每次从实例中随机取出一批 key(这个数量可配置),然后淘汰一个最少访问的 key,之后把剩下的 key 暂存到一个池子中,继续随机取一批 key,并与之前池子中的 key 比较,再淘汰一个最少访问的 key。以此往复,直到实例内存降到 maxmemory 之下。
需要注意的是,Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,而且,写 OPS 越高,延迟也会越明显。
另外,如果此时你的 Redis 实例中还存储了 bigkey,那么在淘汰删除 bigkey 释放内存时,也会耗时比较久。
看到了么?bigkey 的危害到处都是,这也是前面我提醒你尽量不存储 bigkey 的原因。
解决方案
- 避免存储 bigkey,降低释放内存的耗时
- 淘汰策略改为随机淘汰,随机淘汰比 LRU 要快很多(视业务情况调整)
- 拆分实例,把淘汰 key 的压力分摊到多个实例上
- 如果使用的是 Redis 4.0 以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行(配置 lazyfree-lazy-eviction = yes)
原因2:开启内存大页
排查思路
- 我们都知道,应用程序向操作系统申请内存时,是按内存页进行申请的,而常规的内存页大小是 4KB。
- Linux 内核从 2.6.38 开始,支持了内存大页机制,该机制允许应用程序以 2MB 大小为单位,向操作系统申请内存。
- 应用程序每次向操作系统申请的内存单位变大了,但这也意味着申请内存的耗时变长。
导致变慢的原因
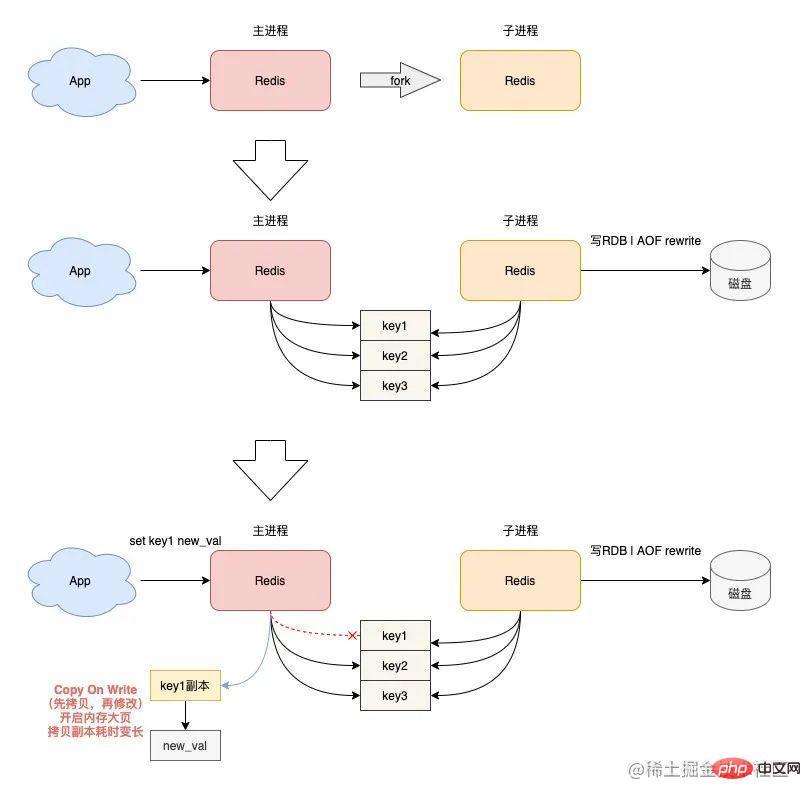
- 当 Redis 在执行后台 RDB 和 AOF rewrite 时,采用 fork 子进程的方式来处理。但主进程 fork 子进程后,此时的主进程依旧是可以接收写请求的,而进来的写请求,会采用 Copy On Write(写时复制)的方式操作内存数据。
- 也就是说,主进程一旦有数据需要修改,Redis 并不会直接修改现有内存中的数据,而是先将这块内存数据拷贝出来,再修改这块新内存的数据,这就是所谓的「写时复制」。
- 写时复制你也可以理解成,谁需要发生写操作,谁就需要先拷贝,再修改。
- 这样做的好处是,父进程有任何写操作,并不会影响子进程的数据持久化(子进程只持久化 fork 这一瞬间整个实例中的所有数据即可,不关心新的数据变更,因为子进程只需要一份内存快照,然后持久化到磁盘上)。
- 但是请注意,主进程在拷贝内存数据时,这个阶段就涉及到新内存的申请,如果此时操作系统开启了内存大页,那么在此期间,客户端即便只修改 10B 的数据,Redis 在申请内存时也会以 2MB 为单位向操作系统申请,申请内存的耗时变长,进而导致每个写请求的延迟增加,影响到 Redis 性能。
- 同样地,如果这个写请求操作的是一个 bigkey,那主进程在拷贝这个 bigkey 内存块时,一次申请的内存会更大,时间也会更久。可见,bigkey 在这里又一次影响到了性能。
解决方案
关闭内存大页机制。
首先,你需要查看 Redis 机器是否开启了内存大页:
$ cat /sys/kernel/mm/transparent_hugepage/enabled [always] madvise never
如果输出选项是 always,就表示目前开启了内存大页机制,我们需要关掉它:
$ echo never > /sys/kernel/mm/transparent_hugepage/enabled
其实,操作系统提供的内存大页机制,其优势是,可以在一定程序上降低应用程序申请内存的次数。
但是对于 Redis 这种对性能和延迟极其敏感的数据库来说,我们希望 Redis 在每次申请内存时,耗时尽量短,所以我不建议你在 Redis 机器上开启这个机制。
原因3:使用Swap
排查思路
如果你发现 Redis 突然变得非常慢,每次的操作耗时都达到了几百毫秒甚至秒级,那此时你就需要检查 Redis 是否使用到了 Swap,在这种情况下 Redis 基本上已经无法提供高性能的服务了。
导致变慢的原因
什么是 Swap?为什么使用 Swap 会导致 Redis 的性能下降?
如果你对操作系统有些了解,就会知道操作系统为了缓解内存不足对应用程序的影响,允许把一部分内存中的数据换到磁盘上,以达到应用程序对内存使用的缓冲,这些内存数据被换到磁盘上的区域,就是 Swap。
问题就在于,当内存中的数据被换到磁盘上后,Redis 再访问这些数据时,就需要从磁盘上读取,访问磁盘的速度要比访问内存慢几百倍!尤其是针对 Redis 这种对性能要求极高、性能极其敏感的数据库来说,这个操作延时是无法接受的。
此时,你需要检查 Redis 机器的内存使用情况,确认是否存在使用了 Swap。你可以通过以下方式来查看 Redis 进程是否使用到了 Swap:
# 先找到 Redis 的进程 ID $ ps -aux | grep redis-server # 查看 Redis Swap 使用情况 $ cat /proc/$pid/smaps | egrep '^(Swap|Size)'
输出结果如下
Size: 1256 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 63488 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 65404 kB
Swap: 0 kB
Size: 1921024 kB
Swap: 0 kB
...
这个结果会列出 Redis 进程的内存使用情况。
每一行 Size 表示 Redis 所用的一块内存大小,Size 下面的 Swap 就表示这块 Size 大小的内存,有多少数据已经被换到磁盘上了,如果这两个值相等,说明这块内存的数据都已经完全被换到磁盘上了。
如果只是少量数据被换到磁盘上,例如每一块 Swap 占对应 Size 的比例很小,那影响并不是很大。如果是几百兆甚至上 GB 的内存被换到了磁盘上,那么你就需要警惕了,这种情况 Redis 的性能肯定会急剧下降。
解决方案
- 增加机器的内存,让 Redis 有足够的内存可以使用
- 整理内存空间,释放出足够的内存供 Redis 使用,然后释放 Redis 的 Swap,让 Redis 重新使用内存
释放 Redis 的 Swap 过程通常要重启实例,为了避免重启实例对业务的影响,一般会先进行主从切换,然后释放旧主节点的 Swap,重启旧主节点实例,待从库数据同步完成后,再进行主从切换即可。
可见,当 Redis 使用到 Swap 后,此时的 Redis 性能基本已达不到高性能的要求(你可以理解为武功被废),所以你也需要提前预防这种情况。
预防的办法就是,你需要对 Redis 机器的内存和 Swap 使用情况进行监控,在内存不足或使用到 Swap 时报警出来,及时处理。
原因4:网络带宽过载
排查思路
如果以上产生性能问题的场景,你都规避掉了,而且 Redis 也稳定运行了很长时间,但在某个时间点之后开始,操作 Redis 突然开始变慢了,而且一直持续下去,这种情况又是什么原因导致?
此时你需要排查一下 Redis 机器的网络带宽是否过载,是否存在某个实例把整个机器的网路带宽占满的情况。
导致变慢的原因
网络带宽过载的情况下,服务器在 TCP 层和网络层就会出现数据包发送延迟、丢包等情况。
Redis 的高性能,除了操作内存之外,就在于网络 IO 了,如果网络 IO 存在瓶颈,那么也会严重影响 Redis 的性能。
解决方案
- 及时确认占满网络带宽 Redis 实例,如果属于正常的业务访问,那就需要及时扩容或迁移实例了,避免因为这个实例流量过大,影响这个机器的其他实例。
- 运维层面,你需要对 Redis 机器的各项指标增加监控,包括网络流量,在网络流量达到一定阈值时提前报警,及时确认和扩容。
原因5:其他原因
1) 频繁短连接
你的业务应用,应该使用长连接操作 Redis,避免频繁的短连接。
频繁的短连接会导致 Redis 大量时间耗费在连接的建立和释放上,TCP 的三次握手和四次挥手同样也会增加访问延迟。
2) 运维监控
前面我也提到了,要想提前预知 Redis 变慢的情况发生,必不可少的就是做好完善的监控。
监控其实就是对采集 Redis 的各项运行时指标,通常的做法是监控程序定时采集 Redis 的 INFO 信息,然后根据 INFO 信息中的状态数据做数据展示和报警。
这里我需要提醒你的是,在写一些监控脚本,或使用开源的监控组件时,也不能掉以轻心。
在写监控脚本访问 Redis 时,尽量采用长连接的方式采集状态信息,避免频繁短连接。同时,你还要注意控制访问 Redis 的频率,避免影响到业务请求。
在使用一些开源的监控组件时,最好了解一下这些组件的实现原理,以及正确配置这些组件,防止出现监控组件发生 Bug,导致短时大量操作 Redis,影响 Redis 性能的情况发生。
我们当时就发生过,DBA 在使用一些开源组件时,因为配置和使用问题,导致监控程序频繁地与 Redis 建立和断开连接,导致 Redis 响应变慢。
3)其它程序争抢资源
最后需要提醒你的是,你的 Redis 机器最好专项专用,只用来部署 Redis 实例,不要部署其他应用程序,尽量给 Redis 提供一个相对「安静」的环境,避免其它程序占用 CPU、内存、磁盘资源,导致分配给 Redis 的资源不足而受到影响。
推荐学习:Redis视频教程
以上是浅谈Redis变慢的原因及排查方法的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通过分片将Redis实例部署到多个服务器,提高可扩展性和可用性。搭建步骤如下:创建奇数个Redis实例,端口不同;创建3个sentinel实例,监控Redis实例并进行故障转移;配置sentinel配置文件,添加监控Redis实例信息和故障转移设置;配置Redis实例配置文件,启用集群模式并指定集群信息文件路径;创建nodes.conf文件,包含各Redis实例的信息;启动集群,执行create命令创建集群并指定副本数量;登录集群执行CLUSTER INFO命令验证集群状态;使
 redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 数据:使用 FLUSHALL 命令清除所有键值。使用 FLUSHDB 命令清除当前选定数据库的键值。使用 SELECT 切换数据库,再使用 FLUSHDB 清除多个数据库。使用 DEL 命令删除特定键。使用 redis-cli 工具清空数据。
 redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
要从 Redis 读取队列,需要获取队列名称、使用 LPOP 命令读取元素,并处理空队列。具体步骤如下:获取队列名称:以 "queue:" 前缀命名,如 "queue:my-queue"。使用 LPOP 命令:从队列头部弹出元素并返回其值,如 LPOP queue:my-queue。处理空队列:如果队列为空,LPOP 返回 nil,可先检查队列是否存在再读取元素。
 redis指令怎么用
Apr 10, 2025 pm 08:45 PM
redis指令怎么用
Apr 10, 2025 pm 08:45 PM
使用 Redis 指令需要以下步骤:打开 Redis 客户端。输入指令(动词 键 值)。提供所需参数(因指令而异)。按 Enter 执行指令。Redis 返回响应,指示操作结果(通常为 OK 或 -ERR)。
 redis怎么使用锁
Apr 10, 2025 pm 08:39 PM
redis怎么使用锁
Apr 10, 2025 pm 08:39 PM
使用Redis进行锁操作需要通过SETNX命令获取锁,然后使用EXPIRE命令设置过期时间。具体步骤为:(1) 使用SETNX命令尝试设置一个键值对;(2) 使用EXPIRE命令为锁设置过期时间;(3) 当不再需要锁时,使用DEL命令删除该锁。
 redis怎么读源码
Apr 10, 2025 pm 08:27 PM
redis怎么读源码
Apr 10, 2025 pm 08:27 PM
理解 Redis 源码的最佳方法是逐步进行:熟悉 Redis 基础知识。选择一个特定的模块或功能作为起点。从模块或功能的入口点开始,逐行查看代码。通过函数调用链查看代码。熟悉 Redis 使用的底层数据结构。识别 Redis 使用的算法。
 redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通过以下步骤管理和操作 Redis:连接到服务器,指定地址和端口。使用命令名称和参数向服务器发送命令。使用 HELP 命令查看特定命令的帮助信息。使用 QUIT 命令退出命令行工具。
 centos redis如何配置Lua脚本执行时间
Apr 14, 2025 pm 02:12 PM
centos redis如何配置Lua脚本执行时间
Apr 14, 2025 pm 02:12 PM
在CentOS系统上,您可以通过修改Redis配置文件或使用Redis命令来限制Lua脚本的执行时间,从而防止恶意脚本占用过多资源。方法一:修改Redis配置文件定位Redis配置文件:Redis配置文件通常位于/etc/redis/redis.conf。编辑配置文件:使用文本编辑器(例如vi或nano)打开配置文件:sudovi/etc/redis/redis.conf设置Lua脚本执行时间限制:在配置文件中添加或修改以下行,设置Lua脚本的最大执行时间(单位:毫秒)
