

Python怎么多线程并发下载图片


有时候,下载大量图像需要几个小时——让我们来解决这个问题
我明白了——你已经厌倦了等待你的程序下载图像。有时我必须下载数千张图像需要几个小时,而且你不可能一直等待你的程序完成下载这些愚蠢的图像。你有很多重要的事情要做。
让我们构建一个简单的图像下载器脚本,它将读取一个文本文件并以超快的速度下载一个文件夹中列出的所有图像。
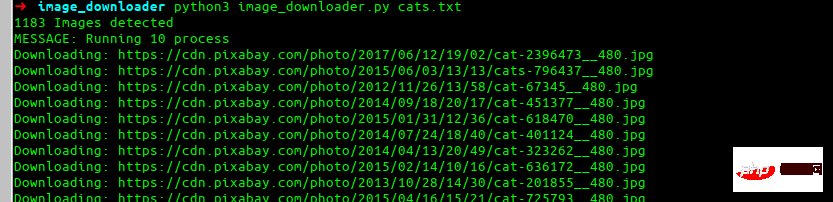
最终效果
这就是我们最终要构建的效果。

安装依赖项
让我们安装每个人最喜欢的 requests 库。
pip install requests
现在,我们将看到一些用于下载单个 URL 并尝试自动查找图像名称以及如何使用重试的基本代码。
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1在这里,我们重试下载图像五次,以防失败。现在,让我们尝试自动找到图像的名称并保存它。
import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]解释
假设我们要下载的 URL 是:
instagram.fktm7-1.fna.fbcdn.net/vp...
好吧,这是一团糟。让我们分解一下代码对 URL 的作用。我们首先使用 rfind 找到最后一个正斜杠(/),然后选择之后的所有内容。这是结果:
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
现在我们的第二部分找到一个 ?,然后只取它前面的任何东西。
这是我们最终的图像名称:
65872070_1200425330158967_6201268309743367902_n.jpg
这个结果非常好,适用于大多数用例。
现在我们已经下载了图像名称和图像,我们将保存它。
i = Image.open(io.BytesIO(res.content)) i.save(image_name)
如果你在想,「我到底应该怎么使用上面的代码?」那么你的想法是正确的。这是一个漂亮的函数,我们在上面所做的一切都被扁平处理了。在这里,我们还测试了下载的类型是否为图像,以防找不到图像名称。
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = 'cats'
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'现在,你可能会问:「这个人所说的多处理在哪里?」。
这很简单。我们将简单地定义我们的池并将我们的函数和图像 URL 传递给它。
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)让我们把它放在一个函数中:
def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)再一次,你可能会说,「这一切都很好,但我想立即开始下载我的 1000 张图像列表。我不想复制和粘贴所有这些代码并试图弄清楚如何合并所有内容。」
这是一个完整的脚本。它执行以下操作:
以图像列表文本文件和进程号作为输入
按照您想要的速度下载它们
打印下载文件的总时间
还有一些不错的函数可以帮助我们读取文件名并处理错误和其他东西
完整的脚本
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通过读取终端中作为参数提供的 txt 文件返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
输入选项:
参数: img_url str (Image url)
尝试下载图像 url 并使用标题中提供的名称。否则它会随机选择一个名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = get_download_location()
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'
def run_downloader(process:int, images_url:list):
"""
输入项:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)
try:
num_process = int(sys.argv[2])
except:
num_process = 10
images_url = get_urls()
run_downloader(num_process, images_url)
end = time.time()
print('Time taken to download {}'.format(len(get_urls())))
print(end - start)将其保存到 Python 文件中,然后运行它。
python3 image_downloader.py cats.txt
这是 GitHub 存储库的链接。
用法
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process>
这将读取文本文件中的所有 URL,并将它们下载到名称与文件名相同的文件夹中。
num_of_process 是可选的(默认情况下,它使用 10 个进程)。
例子
python3 image_downloader.py cats.txt

我很乐意就如何进一步改进这一点做出任何回应。
英文原文地址:https://betterprogramming.pub/building-an-imagedownloader-with-multiprocessing-in-python-44aee36e0424
【相关推荐:Python3视频教程 】
以上是Python怎么多线程并发下载图片的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:轻量级、高水平可扩展的Python数据库HadiDB(hadidb)是一个用Python编写的轻量级数据库,具备高度水平的可扩展性。安装HadiDB使用pip安装:pipinstallhadidb用户管理创建用户:createuser()方法创建一个新用户。authentication()方法验证用户身份。fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 2小时的Python计划:一种现实的方法
Apr 11, 2025 am 12:04 AM
2小时的Python计划:一种现实的方法
Apr 11, 2025 am 12:04 AM
2小时内可以学会Python的基本编程概念和技能。1.学习变量和数据类型,2.掌握控制流(条件语句和循环),3.理解函数的定义和使用,4.通过简单示例和代码片段快速上手Python编程。
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
 Python:探索其主要应用程序
Apr 10, 2025 am 09:41 AM
Python:探索其主要应用程序
Apr 10, 2025 am 09:41 AM
Python在web开发、数据科学、机器学习、自动化和脚本编写等领域有广泛应用。1)在web开发中,Django和Flask框架简化了开发过程。2)数据科学和机器学习领域,NumPy、Pandas、Scikit-learn和TensorFlow库提供了强大支持。3)自动化和脚本编写方面,Python适用于自动化测试和系统管理等任务。
 如何将 AWS Glue 爬网程序与 Amazon Athena 结合使用
Apr 09, 2025 pm 03:09 PM
如何将 AWS Glue 爬网程序与 Amazon Athena 结合使用
Apr 09, 2025 pm 03:09 PM
作为数据专业人员,您需要处理来自各种来源的大量数据。这可能会给数据管理和分析带来挑战。幸运的是,两项 AWS 服务可以提供帮助:AWS Glue 和 Amazon Athena。
 mysql 可以连接到 sql 服务器吗
Apr 08, 2025 pm 05:54 PM
mysql 可以连接到 sql 服务器吗
Apr 08, 2025 pm 05:54 PM
否,MySQL 无法直接连接到 SQL Server。但可以使用以下方法实现数据交互:使用中间件:将数据从 MySQL 导出到中间格式,然后通过中间件导入到 SQL Server。使用数据库链接器:商业工具可提供更友好的界面和高级功能,本质上仍通过中间件方式实现。
 redis怎么启动服务器
Apr 10, 2025 pm 08:12 PM
redis怎么启动服务器
Apr 10, 2025 pm 08:12 PM
启动 Redis 服务器的步骤包括:根据操作系统安装 Redis。通过 redis-server(Linux/macOS)或 redis-server.exe(Windows)启动 Redis 服务。使用 redis-cli ping(Linux/macOS)或 redis-cli.exe ping(Windows)命令检查服务状态。使用 Redis 客户端,如 redis-cli、Python 或 Node.js,访问服务器。
