

工具分享:实现前端埋点的自动化管理


埋点一直是 H5 项目中的重要一环,埋点数据更是后期改善业务和技术优化的重要基础。【推荐学习:web前端、编程教学】
在日常的工作中,经常会有产品或者业务的同学来问,“这个项目现在有哪些埋点?”,“这个埋点用在哪些地方?”像这样的问题基本上都是问一次查一次代码,效率很低。

这也许跟埋点本身的性质有关系。埋点属于相对独立的功能,随着迭代的进行,开发者很难记住埋点的用途。开发者出于自测验证的需要,也得对项目中的埋点数据加以整理。因此结合当前的场景,可以实现一个工具:通过对代码进行扫描,分析埋点相关的代码,并对之加以处理,转化成特定的数据,供后续在其他的管理平台中使用。
实现思路
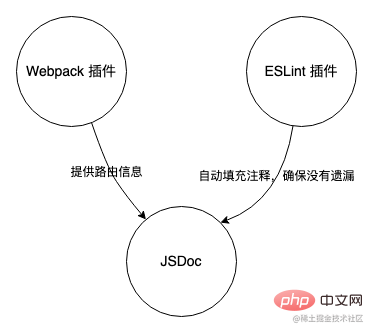
这个工具大致可以分成三个部分,JSDoc 提取埋点、路由依赖分析和 ESLint 插件。
- JSDoc 是根据 JavaScript 中的注释信息,生成 API 文档的一个工具。结合 JSDoc 的这一个特性,这个埋点工具把 JSDoc 作为核心部分,用于输出代码中的埋点数据。
- Webpack 插件作为辅助,为 JSDoc 提供路由信息。
- ESLint 插件则作为最后的检验,确保文件中的埋点代码都有对应的 JSDoc 注释。
自定义 JSDoc 标记埋点
我们知道,JSDoc 可以根据代码中的注释输出一份文档。首先我们自定义一个 JSDoc 的 tag 来标注这是一个埋点的注释,这样后续处理时可以过滤掉其他注释的干扰。结合具体项目中使用的代码可以画出这样一个流程图:

下面是具体的代码实现的过程。
编写 JSDoc 插件,自定义一个 tag:
// jsdoc.plugin.js
// 自定义一个 @log,含有 @log 才是埋点的注释
exports.defineTags = function (dictionary) {
dictionary.defineTag('log', {
canHaveName: true,
onTagged: function (doclet, tag) {
doclet.meta.log = tag.text;
},
});
};解析 .ts 和 .vue 文件。
// jsdoc.plugin.js
exports.handlers = {
beforeParse: function (e) {
// 对文件预处理
if (/.vue/.test(e.filename)) {
// 解析 vue 文件
const component = compiler.parseComponent(e.source);
// 获取 vue 文件的 script 代码
const ast = parse.parse(component.script.content, {
// ...
});
}
if (/.ts/.test(e.filename)) {
// ts 转 js
}
},
};自定义 JSDoc 模版。
// publish.js
exports.publish = function (taffyData, opts, tutorials) {
// ...
data().each(function (doclet) {
// 有 log 这个 tag 的才是埋点注释
if (doclet.meta && doclet.meta.log) {
doclet.tags?.forEach((item) => {
// 获取对应的路由地址
});
// 拿到埋点数据
logData.push({});
}
});
// 输出 md 文档
fs.writeFileSync(outpath, mdContent, 'utf8');
};到这里,已经可以完整地输出代码中的所有埋点了。此时再来看下目前这个工具的能力:
- 自动提取埋点信息,生成埋点文档:✅
- 自动给埋点注释添加自定义 tag(@log):❌
- 自动给埋点注释添加上报的埋点信息:❌
- 自动给埋点注释添加路由信息:❌
- 自动给埋点注释添加埋点描述信息:❌
- 自动提示没有注释的埋点代码:❌
通过上面的梳理我们可以看出:
- 需要手动给每个埋点加上注释
- 需要手动去查每个埋点所对应的路由
- 如果忘了给埋点加注释怎么办?
做这个工具的初衷,就是为省去一些重复繁琐的工作,如果为了能自动从代码中输入一份文档而增加了其他一些工作量,这未免有点得不偿失。通过对这些问题的分析,可以得出以下的解决方案:
- 需要手动给每个埋点加上注释 -> 自动填充代码 -> ESLint fix 功能 / VSCode 插件
- 需要手动去查每个埋点所对应的路由 -> 自动找到组件所对应的路由 -> Webpack 依赖分析
- 如果忘了给埋点加注释怎么办?-> 忘写注释有提示 -> ESLint 插件
到这一步解决问题的方法就已经变得明朗了。接下来让看一下 webpack 插件与 ESLint 插件的实现过程。
路由依赖分析
webpack 本身自带依赖分析,轻松就能拿到组件间的父子关系。
compiler.hooks.normalModuleFactory.tap('routeAnalysePlugin', (nmf) => {
nmf.hooks.afterResolve.tapAsync('routeAnalysePlugin', (result, callback) => {
const { resourceResolveData } = result;
// 子组件
const path = resourceResolveData.path;
// 父组件
const fatherPath = resourceResolveData.context.issuer;
// 只获取 vue 文件的依赖关系
if (/.vue/.test(path) && /.vue/.test(fatherPath)) {
// 将组件间的父子关系存到变量中
}
});
});把组件之间的依赖关系拼成我们想要的数据格式
[
{
"path": "src/views/register-v2/index.vue",
"deps": [
{
"path": "src/components/landing-banner/index.vue",
"deps": []
}
]
}
// ...
]组件之间的依赖关系有了,接下来就是找到组件和路由的对应关系,这里我们用 AST 来解析路由文件,获取路由和组件的对应关系。
// 遍历路由文件
for (let i = 0; i < this.routePaths.length; i++) {
// ...
traverse(ast, {
enter(path) {
// 找出组件和路由的对应关系
path.node.properties.forEach((item) => {
// 组件
if (item.key.name === 'component') {
}
// 路由地址
if (item.key.name === 'path') {
}
});
},
});
}同样地,把组件与路由的映射关系拼成合适的数据格式。
{
"src/views/register-v3/index.vue": "/register"
// ...
}再将路由的映射关系和组件间的依赖关系整合到一起,得出每个组件与路由的对应关系。
{
"src/components/landing-banner/index.vue": [
"/register_v2",
"/register"
//...
]
// ...
}因为使用 AST 遍历的方式来解析路由文件,目前支持的解析的路由文件写法有以下四种,基本上满足了当前的场景:
const page1 = (resolve) => {
require.ensure(
[],
() => {
resolve(require('page1.vue'));
},
'page1',
);
};
const page2 = () =>
import(
/* webpackChunkName: "page2" */
'page2.vue'
);
export default [
{ path: '/page1', component: page1 },
{ path: '/page2', component: page2 },
{
path: '/page3',
component: (resolve) => {
require.ensure(
[],
() => {
resolve(require('page3.vue'));
},
'page3',
);
},
},
{
path: '/page4',
component: () =>
import(
/* webpackChunkName: "page4" */
'page4.vue'
),
},
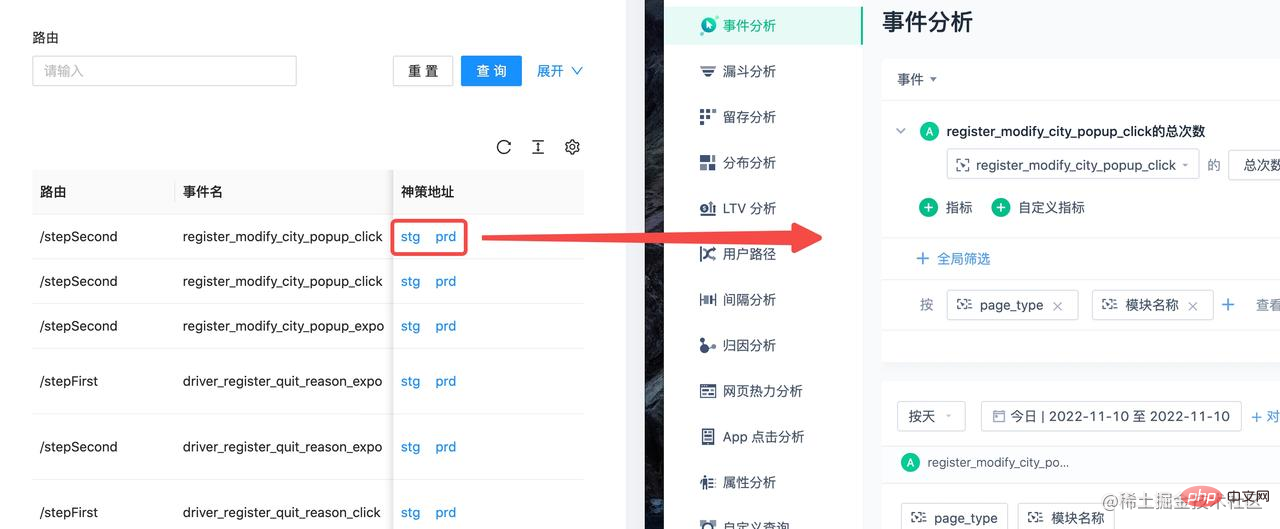
];再得到了上面的对应关系之后,可以把埋点数据放到传到埋点管理平台上,从而实现一键查询:
编写 ESLint 插件
先来看看代码中埋点上报的三种方式:
// 神策 sdk
sensors.track('xxx', {});
// 挂载到 Vue 实例中
this.$sa.track('xxx', {});
// 装饰器
@SensorTrack('xxx', {})观察上面三种方式,可以知道埋点上报是通过 track 函数和 SensorTrack 函数,所以我们的 ESLint 插件对这两个函数进行校验。
function create(context) {
// 调用 track 函数的对象
const checkList = ['sensor', 'sensors', '$sa', 'sa'];
return {
Literal: function (node) {
// ...
// 调用埋点函数而缺少注释时
if (
isNoComment &&
((isTrack && isSensor) || (is$Track && isThisExpression))
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
// 使用修饰器但没有注释时
if (
callee.name === 'SensorTrack' &&
sourceCode.getCommentsBefore(node).length === 0
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
},
};
}看下完成后的效果:
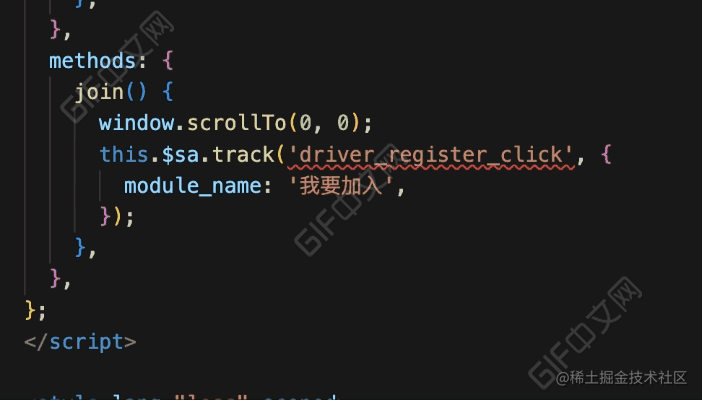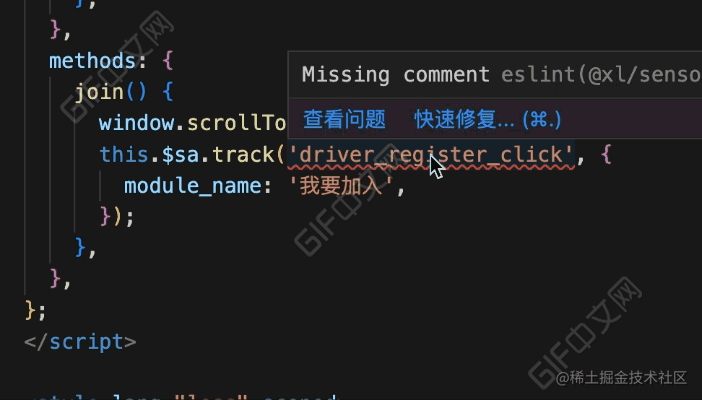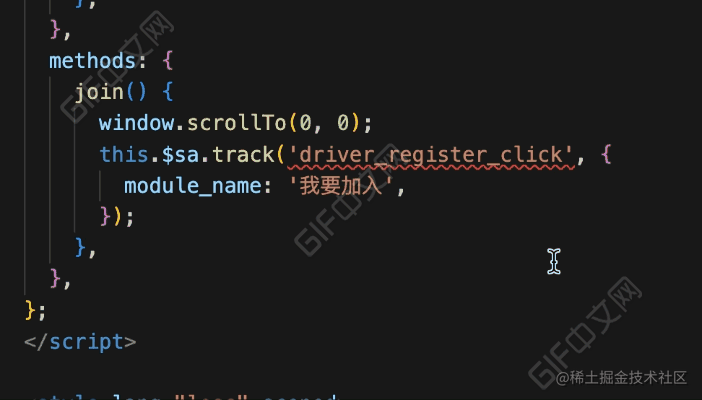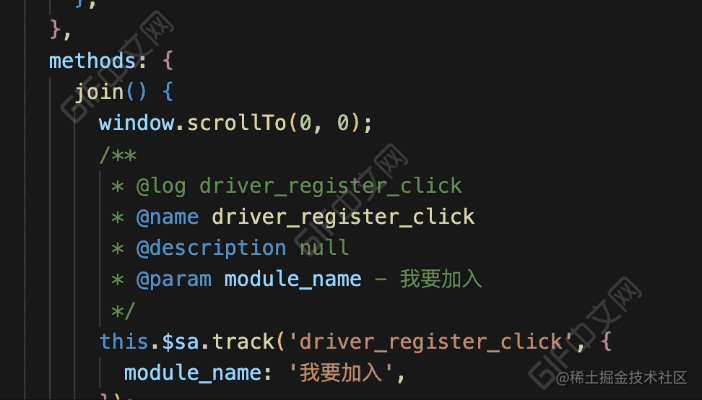
效果对比
我们再来对比下优化前后的区别:
| 优化前 | 优化后 | |
|---|---|---|
| 自动提取埋点信息,生成埋点文档 | ✅ | ✅ |
| 自动给埋点注释添加自定义 tag(@log) | ❌ | ✅ |
| 自动给埋点注释添加上报的埋点信息 | ❌ | ✅ |
| 自动给埋点注释添加路由信息 | ❌ | ✅ |
| 自动给埋点注释添加埋点描述信息 | ❌ | ❌ |
| 自动提示没有注释的埋点代码 | ❌ | ✅ |
优化之后除了整个流程基本都由工具自动完成,剩下一个埋点描述信息。因为埋点的描述信息只是为了让我们更好地理解这个埋点,本身并不在上报的代码中,所以工具没有办法自动生成,但是我们可以直接在产品提供的埋点文档中拷贝过来完成这一步。
总结
在项目中接入这个工具之后,可以快速地知道项目的埋点有哪些以及各个埋点所在的页面,也方便我们对埋点的梳理,同时利用导出的埋点数据开发后台应用,有效地提升了开发者效率。
这个工具的实现是在 JSDoc、webpack 和 ESLint 插件的加持下水到渠成的,说是水到渠成是因为一开始的想法只是做到第一步,先有个一键查询功能和能够输出一份文档用着先。但是第一版出来后发现要手动去处理这些埋点注释还是比较繁琐,恰巧平常开发中常见的 webpack 插件和 ESLint 插件可以很好地解决这些问题,于是便有路由依赖分析和 ESLint 插件。像是《牧羊少年奇幻之旅》中所说的,“如果你下定决心要做一件事情,整个宇宙都会合力帮助你。”
以上是工具分享:实现前端埋点的自动化管理的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 PHP与Vue:完美搭档的前端开发利器
Mar 16, 2024 pm 12:09 PM
PHP与Vue:完美搭档的前端开发利器
Mar 16, 2024 pm 12:09 PM
PHP与Vue:完美搭档的前端开发利器在当今互联网高速发展的时代,前端开发变得愈发重要。随着用户对网站和应用的体验要求越来越高,前端开发人员需要使用更加高效和灵活的工具来创建响应式和交互式的界面。PHP和Vue.js作为前端开发领域的两个重要技术,搭配起来可以称得上是完美的利器。本文将探讨PHP和Vue的结合,以及详细的代码示例,帮助读者更好地理解和应用这两
 C#开发经验分享:前端与后端协同开发技巧
Nov 23, 2023 am 10:13 AM
C#开发经验分享:前端与后端协同开发技巧
Nov 23, 2023 am 10:13 AM
作为一名C#开发者,我们的开发工作通常包括前端和后端的开发,而随着技术的发展和项目的复杂性提高,前端与后端协同开发也变得越来越重要和复杂。本文将分享一些前端与后端协同开发的技巧,以帮助C#开发者更高效地完成开发工作。确定好接口规范前后端的协同开发离不开API接口的交互。要保证前后端协同开发顺利进行,最重要的是定义好接口规范。接口规范涉及到接口的命
 前端面试官常问的问题
Mar 19, 2024 pm 02:24 PM
前端面试官常问的问题
Mar 19, 2024 pm 02:24 PM
在前端开发面试中,常见问题涵盖广泛,包括HTML/CSS基础、JavaScript基础、框架和库、项目经验、算法和数据结构、性能优化、跨域请求、前端工程化、设计模式以及新技术和趋势。面试官的问题旨在评估候选人的技术技能、项目经验以及对行业趋势的理解。因此,应试者应充分准备这些方面,以展现自己的能力和专业知识。
 Django是前端还是后端?一探究竟!
Jan 19, 2024 am 08:37 AM
Django是前端还是后端?一探究竟!
Jan 19, 2024 am 08:37 AM
Django是一个Python编写的web应用框架,它强调快速开发和干净方法。尽管Django是一个web框架,但是要回答Django是前端还是后端这个问题,需要深入理解前后端的概念。前端是指用户直接和交互的界面,后端是指服务器端的程序,他们通过HTTP协议进行数据的交互。在前端和后端分离的情况下,前后端程序可以独立开发,分别实现业务逻辑和交互效果,数据的交
 Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言作为一种快速、高效的编程语言,在后端开发领域广受欢迎。然而,很少有人将Go语言与前端开发联系起来。事实上,使用Go语言进行前端开发不仅可以提高效率,还能为开发者带来全新的视野。本文将探讨使用Go语言进行前端开发的可能性,并提供具体的代码示例,帮助读者更好地了解这一领域。在传统的前端开发中,通常会使用JavaScript、HTML和CSS来构建用户界面
 前端怎么实现即时通讯
Oct 09, 2023 pm 02:47 PM
前端怎么实现即时通讯
Oct 09, 2023 pm 02:47 PM
实现即时通讯的方法有WebSocket、Long Polling、Server-Sent Events、WebRTC等等。详细介绍:1、WebSocket,它可以在客户端和服务器之间建立持久连接,实现实时的双向通信,前端可以使用 WebSocket API来创建WebSocket连接,并通过发送和接收消息来实现即时通讯;2、Long Polling,是一种模拟实时通信的技术等等
 web标准默认的端口有哪些
Sep 20, 2023 pm 04:05 PM
web标准默认的端口有哪些
Sep 20, 2023 pm 04:05 PM
web标准默认的端口有:1、HTTP,默认端口号为80;2、HTTPS,默认端口号为443;3、FTP,默认端口号为21;4、SSH,默认端口号为22;5、Telnet,默认端口号为23;6、SMTP,默认端口号为25;7、POP3,默认端口号为110;8、IMAP,默认端口号为143;9、DNS,默认端口号为53;10、RDP,默认端口号为3389等等。
 web标准有哪些好处
Sep 20, 2023 pm 03:34 PM
web标准有哪些好处
Sep 20, 2023 pm 03:34 PM
web标准的好处有提供更好的跨平台兼容性、可访问性、性能、搜索引擎排名、开发和维护成本、用户体验以及代码的可维护性和可重用性。详细说明:1、跨平台兼容性,确保网站在不同的操作系统、浏览器和设备上都能正确显示和运行;2、提高可访问性,可以确保网站对所有用户都是可访问的;3、加快网站加载速度,用户可以更快地访问和浏览网站,提供更好的用户体验;4、提高搜索引擎排名等等。
