

了解一下Golang中的unsafe包

在一些底层的库中, 经常会看到使用 unsafe 包的地方。本篇文章就来带大家了解一下Golang中的unsafe包,介绍一下unsafe 包的作用和Pointer的使用方式,希望对大家有所帮助!

unsafe 包提供了一些操作可以绕过 go 的类型安全检查, 从而直接操作内存地址, 做一些 tricky 操作。示例代码运行环境是
go version go1.18 darwin/amd64
内存对齐
unsafe 包提供了 Sizeof 方法获取变量占用内存大小「不包含指针指向变量的内存大小」, Alignof 获取内存对齐系数, 具体内存对齐规则可以自行 google.
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
type demo3 struct { // 64 位操作系统, 字长 8
a *demo1 // 8
b *demo2 // 8
}
func MemAlign() {
fmt.Println(unsafe.Sizeof(demo1{}), unsafe.Alignof(demo1{}), unsafe.Alignof(demo1{}.a), unsafe.Alignof(demo1{}.b), unsafe.Alignof(demo1{}.c)) // 16,8,1,4,8
fmt.Println(unsafe.Sizeof(demo2{}), unsafe.Alignof(demo2{}), unsafe.Alignof(demo2{}.a), unsafe.Alignof(demo2{}.b), unsafe.Alignof(demo2{}.c)) // 24,8,1,4,8
fmt.Println(unsafe.Sizeof(demo3{})) // 16
} // 16}复制代码从上面 case 可以看到 demo1 和 demo2 包含相同的属性, 只是定义的属性顺序不同, 却导致变量的内存大小不同。这里是因为发生了内存对齐。
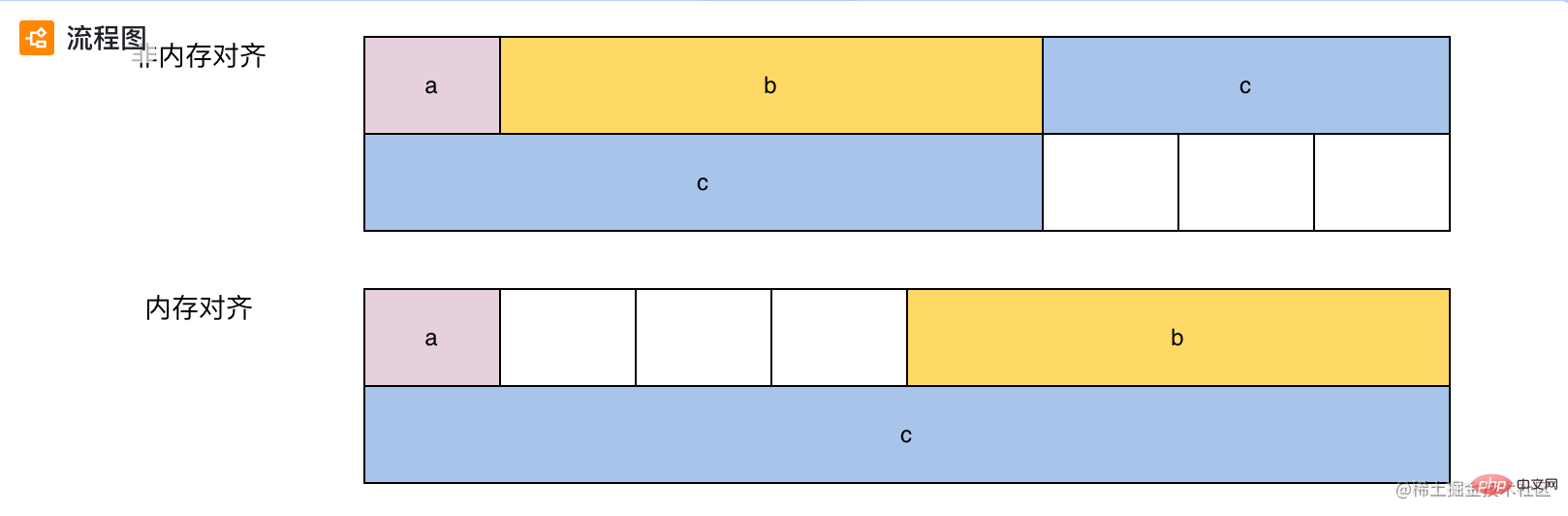
计算机在处理任务时, 会按照特定的字长「例如:32 位操作系统, 字长为 4; 64 位操作系统, 字长为 8」为单位处理数据。那么, 在读取数据的时候也是按照字长为单位。例如: 对于 64 位操作系统, 程序一次读取的字节数为 8 的倍数。下面是 demo1 在非内存对齐和内存对齐下的布局:
非内存对齐:
变量 c 会被放在不同的字长里面, cpu 在读取的时候需要同时读取两次, 同时对两次的结果做处理, 才能拿到 c 的值。这种方式虽然节省了内存空间, 但是会增加处理时间。
内存对齐:
内存对齐采用了一种方案, 可以避免同一个非内存对齐的这种情况, 但是会额外占用一些空间「空间换时间」。具体内存对齐规则可以自行 google。
Unsafe Pointer
在 go 中可以声明一个指针类型, 这里的类型是 safe pointer, 即要明确指针指向的类型, 如果类型不匹配将会在编译时报错。如下面的示例, 编译器会认为 MyString 和 string 是不同的类型, 无法进行赋值。
func main() {
type MyString string
s := "test"
var ms MyString = s // Cannot use 's' (type string) as the type MyString
fmt.Println(ms)
}那有没有一种类型, 可以指向任意类型的变量呢?可以使用 unsfe.Pointer, 它可以指向任意类型的变量。通过Pointer 的声明, 可以知道它是一个指针类型, 指向变量所在的地址。具体的地址对应的值可以通过 uinptr 进行转换。Pointer 有以下四种特殊的操作:
- 任意类型的指针都可以转换成 Pointer 类型
- Pointer 类型的变量可以转换成任意类型的指针
- uintptr 类型的变量可以转换成 Pointer 类型
- Pointer 类型的变量可以转换成 uintprt 类型
type Pointer *ArbitraryType
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d) // 任意类型的指针可以转换为 Pointer 类型
pa := (*demo1)(p) // Pointer 类型变量可以转换成 demo1 类型的指针
up := uintptr(p) // Pointer 类型的变量可以转换成 uintprt 类型
pu := unsafe.Pointer(up) // uintptr 类型的变量可以转换成 Pointer 类型; 当 GC 时, d 的地址可能会发生变更, 因此, 这里的 up 可能会失效
fmt.Println(d.a, pa.a, (*demo1)(pu).a) // true true true
}Pointer 的六种使用方式
在官方文档中给出了 Pointer 的六种使用姿势。
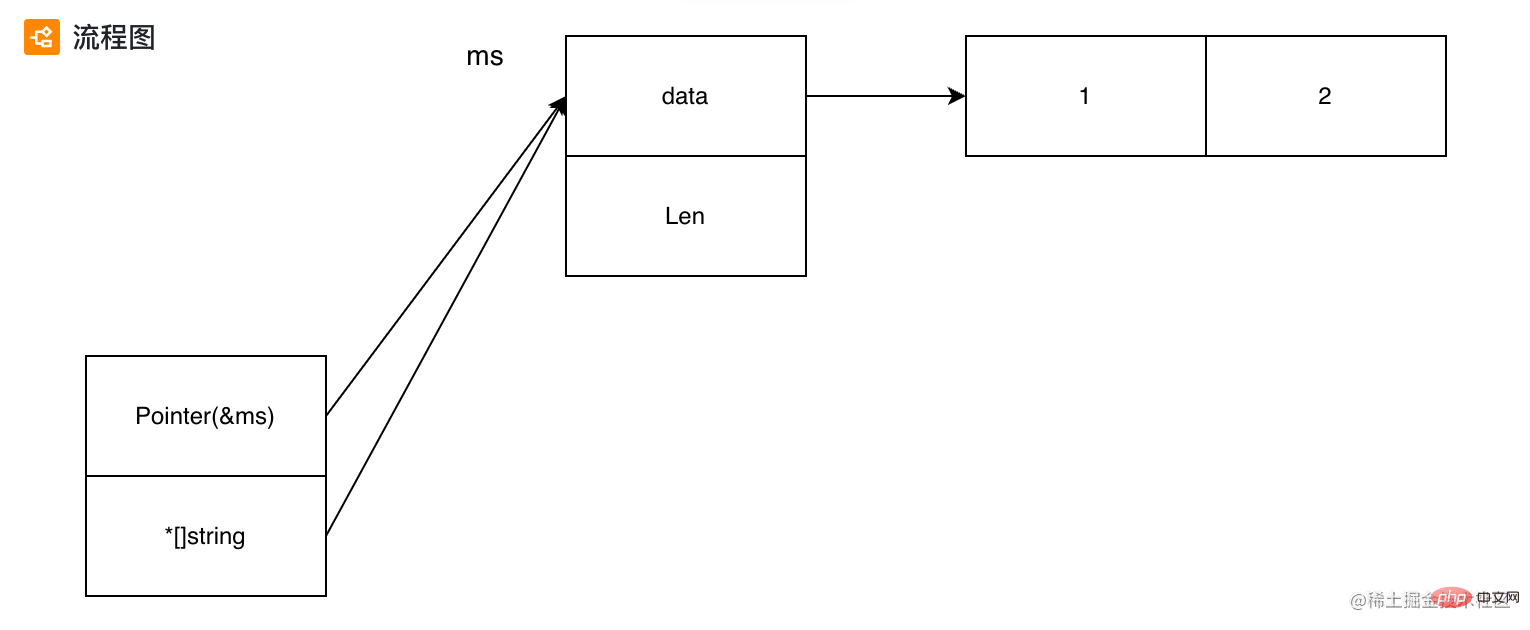
通过 Pointer 将 *T1 转换为 *T2
Pointer 直接指向一块内存, 因此可以将这块内存地址转为任意类型。这里需要注意, T1 和 T2 需要有相同的内存布局, 会有异常数据。
func main() {
type myStr string
ms := []myStr{"1", "2"}
//ss := ([]string)(ms) Cannot convert an expression of the type '[]myStr' to the type '[]string'
ss := *(*[]string)(unsafe.Pointer(&ms)) // 将 pointer 指向的内存地址直接转换成 *[]string
fmt.Println(ms, ss)
}
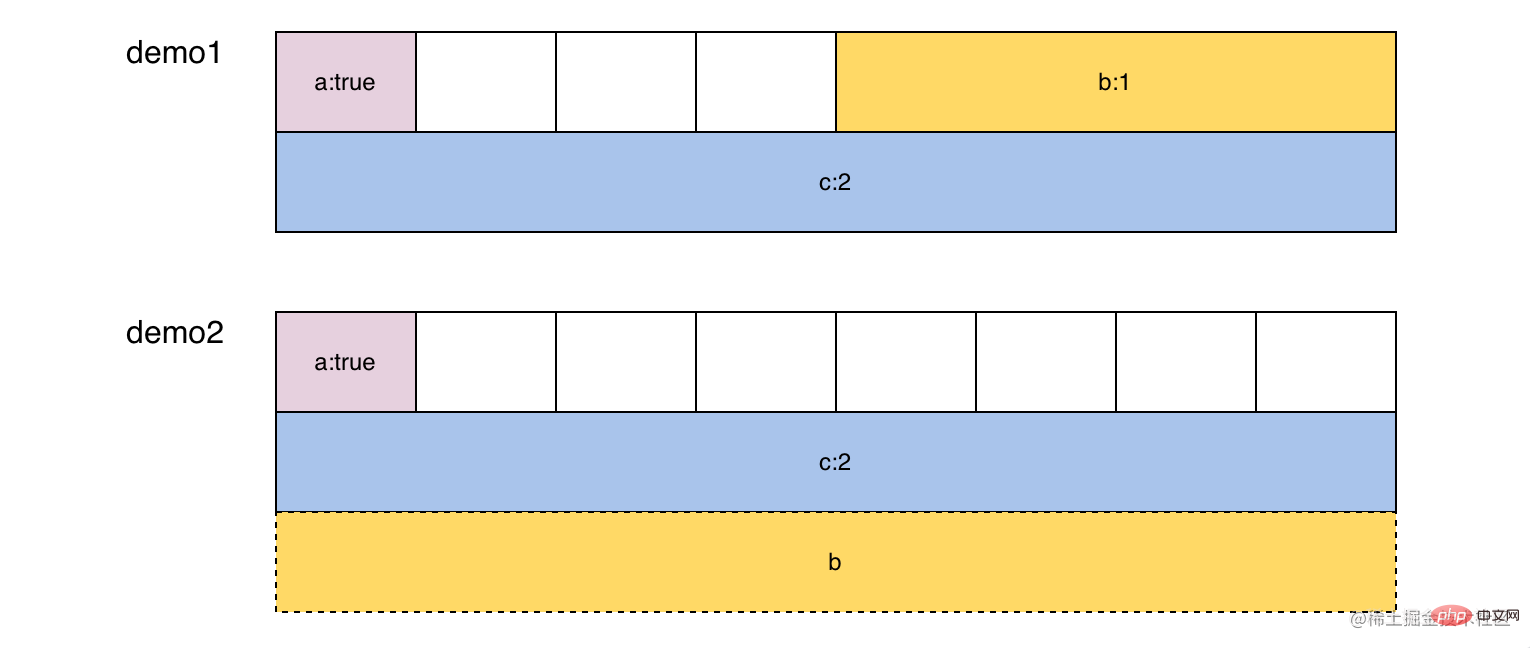
如果 T1 和 T2 的内存布局不同, 会发生什么呢?在下面的示例子中, demo1 和 demo2 虽然包含相同的结构体, 由于内存对齐, 导致两者是不同的内存布局。将 Pointer 转换时, 会从 demo1 的地址开始读取 24「sizeof」 个字节, 按照demo2 内存对齐规则进行转换, 将第一个字节转换为 a:true, 8-16 个字节转换为 c:2, 16-24 个字节超出了 demo1 的范围, 但仍可以直接读取, 获取了非预期的值 b:17368000。
type demo1 struct {
a bool // 1
b int32 // 4
c int64 // 8
}
type demo2 struct {
a bool // 1
c int64 // 8
b int32 // 4
}
func main() {
d := demo1{true, 1, 2}
pa := (*demo2)(unsafe.Pointer(&d)) // Pointer 类型变量可以转换成 demo2 类型的指针
fmt.Println(pa.a, pa.b, pa.c) // true, 17368000, 2,
}
将 Pointer 类型转换为 uintptr 类型「不应该将 uinptr 转为 Pointer」
Pointer 是一个指针类型, 可以指向任意变量, 可以通过将 Pointer 转换为 uintptr 来打印 Pointer 指向变量的地址。此外:不应该将 uintptr 转换为 Pointer。如下面的例子: 当发生 GC 时, d 的地址可能会发生变更, 那么 up 由于未同步更新而指向错误的内存。
func main() {
d := demo1{true, 1, 2}
p := unsafe.Pointer(&d)
up := uintptr(p)
fmt.Printf("uintptr: %x, ptr: %p \n", up, &d) // uintptr: c00010c010, ptr: 0xc00010c010
fmt.Println(*(*demo1)(unsafe.Pointer(up))) // 不允许
}通过算数计算将 Pointer 转换为 uinptr 再转换回 Pointer
当 Piointer 指向一个结构体时, 可以通过此方式获取到结构体内部特定属性的 Pointer。
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
fmt.Println(pb)
}当调用 syscall.Syscall 的时候, 可以讲 Pointer 转换为 uintptr
前面说过, 由于 GC 会导致变量的地址发生变更, 因此不可以直接处理 uintptr。但是, 在调用 syscall.Syscall 时候可以允许传递一个 uintptr, 这里可以简单理解为是编译器做了特殊处理, 来保证 uintptr 是安全的。
- 调用方式:
- syscall.Syscall(SYS_READ, uintptr( fd ), uintptr(unsafe.Pointer(p)), uintptr(n))
下面这种方式是不允许的:
u := uintptr(unsafe.Pointer(p)) // 不应该保存到一个变量上 syscall.Syscall(SYS_READ, uintptr( fd ), u, uintptr(n))
可以将 reflect.Value.Pointer 或 reflect.Value.UnsafeAddr 的结果「uintptr」转换为 Pointer
在 reflect 包中的 Value.Pointer 和 Value.UnsafeAddr 直接返回了地址对应的值「uintptr」, 可以直接将其结果转为 Pointer
func main() {
d := demo1{true, 1, 2}
// 等同于 unsafe.Pointer(&d.b); unsafe.Add(unsafe.Pointer(&d), unsafe.Offsetof(d.b))
pb := unsafe.Pointer(uintptr(unsafe.Pointer(&d)) + unsafe.Offsetof(d.b))
// up := reflect.ValueOf(&d.b).Pointer(), pc := unsafe.Pointer(up); 不安全, 不应存储到变量中
pc := unsafe.Pointer(reflect.ValueOf(&d.b).Pointer())
fmt.Println(pb, pc)
}可以将 reflect.SliceHeader 或者 reflect.StringHeader 的 Data 字段与 Pointer 相互转换
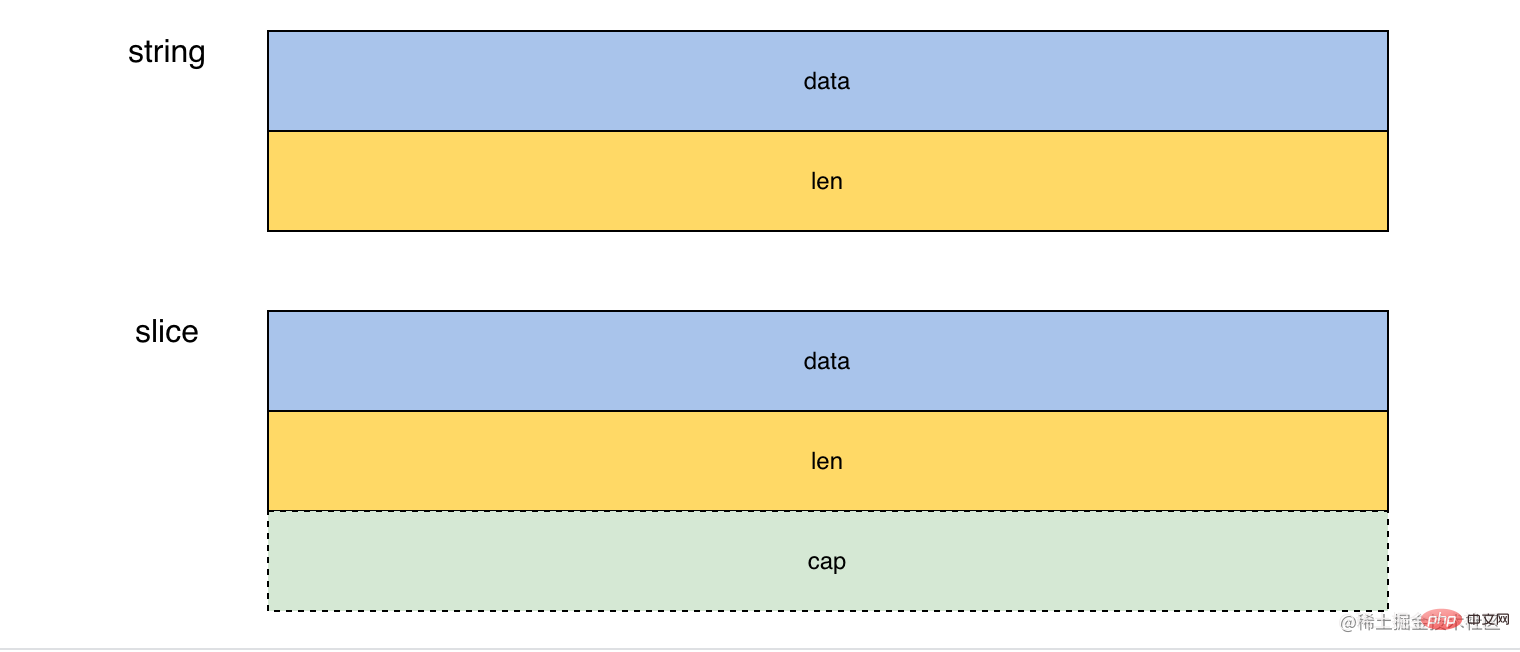
SliceHeader 和 StringHeader 其实是 slice 和 string 的内部实现, 里面都包含了一个字段 Data「uintptr」, 存储的是指向 []T 的地址, 这里之所以使用 uinptr 是为了不依赖 unsafe 包。
func main() {
s := "a"
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // *string to *StringHeader
fmt.Println(*(*[1]byte)(unsafe.Pointer(hdr.Data))) // 底层存储的是 utf 编码后的 byte 数组
arr := [1]byte{65}
hdr.Data = uintptr(unsafe.Pointer(&arr))
hdr.Len = len(arr)
ss := *(*string)(unsafe.Pointer(hdr))
fmt.Println(ss) // A
arr[0] = 66
fmt.Println(ss) //B
}应用
string、byte 转换
在业务上, 经常遇到 string 和 []byte 的相互转换。我们知道, string 底层其实也是存储的一个 byte 数组, 可以通过 reflect 直接获取 string 指向的 byte 数组, 赋值给 byte 切片, 避免内存拷贝。
func StrToByte(str string) []byte {
return []byte(str)
}
func StrToByteV2(str string) (b []byte) {
bh := (*reflect.SliceHeader)(unsafe.Pointer(&b))
sh := (*reflect.StringHeader)(unsafe.Pointer(&str))
bh.Data = sh.Data
bh.Cap = sh.Len
bh.Len = sh.Len
return b
}
// go test -bench .
func BenchmarkStrToArr(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByte(`{"f": "v"}`)
}
}
func BenchmarkStrToArrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
StrToByteV2(`{"f": "v"}`)
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkStrToArr-12 264733503 4.311 ns/op
//BenchmarkStrToArrV2-12 1000000000 0.2528 ns/op通过观察 string 和 byte 的内存布局我们可以知道, 无法直接将 string 转为 []byte 「确实 cap 字段」, 但是可以直接将 []byte 转为 string
func ByteToStr(b []byte) string {
return string(b)
}
func ByteToStrV2(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
// go test -bench .
func BenchmarkArrToStr(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStr([]byte{65})
}
}
func BenchmarkArrToStrV2(b *testing.B) {
for i := 0; i < b.N; i++ {
ByteToStrV2([]byte{65})
}
}
//goos: darwin
//goarch: amd64
//pkg: github.com/demo/lsafe
//cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
//BenchmarkArrToStr-12 536188455 2.180 ns/op
//BenchmarkArrToStrV2-12 1000000000 0.2526 ns/op总结
本文介绍了如何使用 unsafe 包绕过类型检查, 直接操作内存。正如 go 作者对包的命名一样, 它是 unsafe 的, 随着 go 版本的迭代, 有些机制可能会发生变更。如无必要, 不应使用这个包。如果要使用 unsafe 包, 一定要理解清楚Pointer、uinptr、对齐系数等概念。
推荐学习:Golang教程
以上是了解一下Golang中的unsafe包的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 深入理解 Golang 函数生命周期与变量作用域
Apr 19, 2024 am 11:42 AM
深入理解 Golang 函数生命周期与变量作用域
Apr 19, 2024 am 11:42 AM
在Go中,函数生命周期包括定义、加载、链接、初始化、调用和返回;变量作用域分为函数级和块级,函数内的变量在内部可见,而块内的变量仅在块内可见。
 如何在 Go 中使用正则表达式匹配时间戳?
Jun 02, 2024 am 09:00 AM
如何在 Go 中使用正则表达式匹配时间戳?
Jun 02, 2024 am 09:00 AM
在Go中,可以使用正则表达式匹配时间戳:编译正则表达式字符串,例如用于匹配ISO8601时间戳的表达式:^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$。使用regexp.MatchString函数检查字符串是否与正则表达式匹配。
 Go WebSocket 消息如何发送?
Jun 03, 2024 pm 04:53 PM
Go WebSocket 消息如何发送?
Jun 03, 2024 pm 04:53 PM
在Go中,可以使用gorilla/websocket包发送WebSocket消息。具体步骤:建立WebSocket连接。发送文本消息:调用WriteMessage(websocket.TextMessage,[]byte("消息"))。发送二进制消息:调用WriteMessage(websocket.BinaryMessage,[]byte{1,2,3})。
 Golang 与 Go 语言的区别
May 31, 2024 pm 08:10 PM
Golang 与 Go 语言的区别
May 31, 2024 pm 08:10 PM
Go和Go语言是不同的实体,具有不同的特性。Go(又称Golang)以其并发性、编译速度快、内存管理和跨平台优点而闻名。Go语言的缺点包括生态系统不如其他语言丰富、语法更严格以及缺乏动态类型。
 Golang 技术性能优化中如何避免内存泄漏?
Jun 04, 2024 pm 12:27 PM
Golang 技术性能优化中如何避免内存泄漏?
Jun 04, 2024 pm 12:27 PM
内存泄漏会导致Go程序内存不断增加,可通过:关闭不再使用的资源,如文件、网络连接和数据库连接。使用弱引用防止内存泄漏,当对象不再被强引用时将其作为垃圾回收目标。利用go协程,协程栈内存会在退出时自动释放,避免内存泄漏。
 如何在 IDE 中查看 Golang 函数文档?
Apr 18, 2024 pm 03:06 PM
如何在 IDE 中查看 Golang 函数文档?
Apr 18, 2024 pm 03:06 PM
使用IDE查看Go函数文档:将光标悬停在函数名称上。按下热键(GoLand:Ctrl+Q;VSCode:安装GoExtensionPack后,F1并选择"Go:ShowDocumentation")。
 如何使用 Golang 的错误包装器?
Jun 03, 2024 pm 04:08 PM
如何使用 Golang 的错误包装器?
Jun 03, 2024 pm 04:08 PM
在Golang中,错误包装器允许你在原始错误上追加上下文信息,从而创建新错误。这可用于统一不同库或组件抛出的错误类型,简化调试和错误处理。步骤如下:使用errors.Wrap函数将原有错误包装成新错误。新错误包含原始错误的上下文信息。使用fmt.Printf输出包装后的错误,提供更多上下文和可操作性。在处理不同类型的错误时,使用errors.Wrap函数统一错误类型。
 Go 并发函数的单元测试指南
May 03, 2024 am 10:54 AM
Go 并发函数的单元测试指南
May 03, 2024 am 10:54 AM
对并发函数进行单元测试至关重要,因为这有助于确保其在并发环境中的正确行为。测试并发函数时必须考虑互斥、同步和隔离等基本原理。可以通过模拟、测试竞争条件和验证结果等方法对并发函数进行单元测试。
