

SQL Server统计信息维护策略的选择_MySQL

问题描述:
在对OLTP系统的一个上千万的表做归档后,循环分批删除源表数据时,业务应用收到超时告警,如下:
V1.1.1.1: ****Process - QueryTransactionFor****: 23075129
Timeout expired.
The timeout period elapsed prior to completion of the operation or the server is not responding.
This failure occured while attempting to connect to the Principle server.
查询当前活跃进程,发现一个极慢的StatMan查询:
SELECT StatMan([SC0], [SC1], [SB0000]) FROM (SELECT TOP 100 PERCENT [SC0], [SC1], step_direction([SC0]) over (order by NULL) AS [SB0000] FROM (SELECT [TransactionID] AS [SC0], [ID] AS [SC1] FROM [dbo].[Product] TABLESAMPLE SYSTEM (8.340078e-001 PERCENT) WITH (READUNCOMMITTED) ) AS MS_UPDSTATS_TBL_HELPER ORDER BY [SC0], [SC1], [SB0000] ) AS MS_UPDSTATS_TBL OPTION (MAXDOP 1)
这是一个统计信息维护任务,来看看该表所有的统计信息。
EXEC sp_autostats 'dbo.Product';
GO
将结果集根据时间降序排列显示,如下:
[IX_Product_TransactinID] ON 2015-11-12 14:15:14 [IX_Product_CreateTime] ON 2015-11-12 10:17:50 [IX_Product_Number] ON 2015-10-23 12:10:51 [PK_Product] ON 2015-08-14 20:03:41 [_WA_Sys_0000000E_693CA210] ON 2015-07-03 10:39:36 [_WA_Sys_00000025_693CA210] ON 2014-12-05 16:22:20 [_WA_Sys_0000002A_693CA210] ON 2014-12-05 14:54:53 [_WA_Sys_0000000B_693CA210] ON 2014-07-01 10:52:54 [_WA_Sys_00000018_693CA210] ON 2013-01-24 02:16:11 [_WA_Sys_00000023_693CA210] ON 2012-12-20 13:17:27 [_WA_Sys_00000026_693CA210] ON 2012-12-20 13:17:26 [_WA_Sys_00000004_693CA210] ON 2012-12-20 13:17:25 [_WA_Sys_00000006_693CA210] ON 2012-12-20 13:17:24 [_WA_Sys_00000022_693CA210] ON 2012-12-20 13:17:23 [_WA_Sys_0000001B_693CA210] ON 2012-12-20 13:17:22 [_WA_Sys_0000001D_693CA210] ON 2012-12-20 13:17:21 [_WA_Sys_0000000F_693CA210] ON 2012-12-20 13:17:20 [_WA_Sys_00000013_693CA210] ON 2012-12-20 13:17:18
看到在当前时间点,索引[IX_Product_TransactinID]在更新统计信息。
在监控到StatMan进程的同时,也看到导致业务告警的一个查询极慢。
SELECT
p.[ID]
,p.[Name]
,p.[Price]
,p.[Amount]
,p.[TransactionID]
,t.[Action]
,t.[TransactionStatus]
,t.[TransactionResult]
FROM [Product] AS p LEFT JOIN [TransactionInfo] AS t ON p.[TransactionID] = t.[ID]
WHERE [TransactionID] = @transactionId
可以明确是因为删除Product表的数据,使得[TransactionID]列索引[IX_Product_TransactinID]达到了要更新统计信息的阈值,触发了索引维护。
问题处理:
为了让问题查询得到尽快恢复,我新建了一个[TransactionID]列索引,将[IX_Product_TransactinID]禁用,问题得到临时解决。
原理分析:
统计信息维护策略
当SQL Server需要去估算某个操作的复杂度时,它必定要试图去寻找相应的统计信息做支持。数据库管理员无法预估SQL Server会运行什么样的操作,所以也无法预估SQL Server可能会需要什么样的统计信息。如果靠人力来建立和维护统计信息,那将是一个非常复杂的工程。好在SQL Server不是这样设计的。在绝大多数情况下,SQL Server自己会很好地维护和更新统计信息,用户基本没有感觉,数据库管理员也没有额外的负担。
这主要是因为在SQL Server数据库属性里,有两个默认打开的设置:Auto Create Statistics和Auto Update Statistics。它们能够让SQL Server在需要的时候,自动建立要用到的统计信息,也能在发
现统计信息过时的时候,自动去更新它。
SQL Server会在什么情形下创建统计信息呢?主要有3种情况:
1.在索引创建时,SQL Server会自动地在索引所在的列上创建统计信息
所以从某种角度讲,索引的作用是双重的,它自己能够帮助SQL Server快速找到数据。而它上面的统计信息,也能够告诉SQL Server数据的分布情况。
2.管理员也可以通过CREATE STATISTICS之类的语句手动创建他认为需要的统计信息
如果打开了Auto Create Statistics,一般来讲很少需要手动创建。
3.当SQL Server想要使用某些列上的统计信息,发现没有的时候,“Auto Create Statistics”会让SQL Server自动创建统计信息。
例如,当语句要在某个(或者某几个)字段上做过滤,或者要拿它(们)和另外一张表做连接(Join),SQL Server要估算最后从这张表会返回多少条记录,这时候就需要一个统计信息的支持。如果没有,SQL Server会自动创建一个。
我们可以在SalesOrderHeader_test上试试。
sp_helpstats SalesOrderHeader_test
go
-- 返回表格没有statistics(索引上的除外)
select count(*) from
dbo.SalesOrderHeader_test
where OrderDate = '2004-06-11 00:00:00.000'
go
-- 运行一句在OrderDate上有过滤条件的查询
sp_helpstats SalesOrderHeader_test
go
-- 返回表格已经有了一个新的统计信息
statistics_name statistics_keys
------------------------------------------ ---------------
_WA_Sys_00000003_1A34DF26 OrderDate
因此,在打开Auto Create Statistics的数据库上,一般不需要担心SQL Server没有足够的统计信息来选择执行计划,这一点完全交给SQL Server管理就可以了。
SQL Server不仅要建立合适的统计信息,还要及时更新它们,使它们能够反映表格里数据的变化,数据的插入、删除、修改都可能会引起统计信息的更新。但是,更新统计信息本身也是一件消耗资源的事情,尤其是对比较大的表格。如果有一点点小的修改SQL Server都要去更新统计信息,可能SQL Server就得光忙活这个,来不及做其他事了。SQL Server还是要在统计信息的准确度和资源合理消耗之间做一个平衡。触发统计信息自动更新的条件是:
1.如果统计信息是定义在普通表格上的,那么当发生下面变化之一后,统计信息就被认为是过时的了,下次使用到时,会自动触发一个更新动作
(1)表格从没有数据变成有大于等于1条数据。
(2)对于数据量小于500行的表格,当统计信息的第一个字段数据累计变化量大于500以后。
(3)对于数据量大于500行的表格,当统计信息的第一个字段数据累计变化量大于500 + (20%×表格数据总量)以后。
所以对于比较大的表,只有1/5以上的数据发生变化后,SQL Server才会去重算统计信息。
2.临时表(Temp Table)上可以有统计信息,其维护策略基本和普通表格一致,但是表变量(Table Variable)上不能建统计信息
这样的维护策略能够保证花费比较小的代价,确保统计信息基本正确。本案例,反映这个维护策略在数据分布特殊的表格上,也有可能造成一些负面的影响,只需定期手工(或者做一个任务)更新表的统计信息即可。
在SQL Server 2005以后,数据库属性多了一个“Auto Update Statistics Asynchronously”。当SQL Server发现某个统计信息过时时,它会用老的统计信息继续现在的查询编译,但是会在后台启动一个任务,更新这个统计信息。这样下一次统计信息被使用到时,就已经是一个更新过的版本。这样做的缺点是不能保证当前这句查询的执行计划准确性,凡事有利有弊,数据库管理员可以根据实际情况做选择。
当然,的确有一些例外情况。由于数据的特殊性,会使得SQL Server这种Auto Update Statistics的算法不能满足确保执行计划准确性的需求,在实际使用中,有时候数据库的性能会突然之间慢下来。
有经验的管理员会安排做一次索引重建的任务,常常对性能会有所帮助。通常人们会解释为,因为索引重建消除了数据碎片,而提高了性能,其实索引重建还做了另外一件很重要的工作,它使用full scan的方式,重新更新了表上的统计信息,使得统计信息非常精确。这对性能帮助作用也会很大。
跟踪标记 2371
SQL Server 2008 R2 SP1介绍了一个非常好的特性,可以修改自动统计算法(auto stats algorithm),从默认的20%+500行到一个范围值(sliding scale)。该属性只能通过打开跟踪标记2371打开,而并不是默认打开的。
如果按自动统计算法一切运行良好,没有性能问题需要担心。现在只需要考虑到表基数太大像50000行或1000000时的阈值。在这种情况下,对于高基数的表,这些阈值可能不够好。例如,我有一个表基数为50000的表。我插入了20%(10000)新行。根据之前的标准阈值,这些20%的新插入的行不满足触发自动更新统计信息。这可能就是你的情况中性能问题的原因之一。如果你面对同样的问题,不需要担心,因为微软提供了跟踪标记2371.通过使用该标记,SQL Server对于自动更新超过25000行的表上的统计信息,将会决定动态的阈值。对于自动更新统计信息,更高的行基数将会使用更低的阈值。
2371:SQL根据需要自动修改统计信息更新的阀值,而不按照默认算法
http://www.sqlservergeeks.com/sql-server-trace-flag-2371/
策略选择
在大数据库上开启该跟踪标记,很明显是为了使用自动统计,因此需要打开自动统计。此外,我们需要对于拥有超级大表的数据库打开“Auto Update Statistics Asynchronously”。开启异步更新统计信息特性的原因是,当自动统计触发的时候,你不想看到查询超时。
我们知道自动统计当表中实际的行数改变时会更新统计信息。当超级大表触发了自动统计运行时,如果花费超过30秒运行更新统计信息命令,触发自动统计的查询语句将会超时,导致了事务回滚,意味着自动统计命令也回滚。因此下一个查询也会触发自动统计信息更新,并且这个过程将重复循环。
你会在SQL Server中随机看到查询超时,即使执行计划看起来总体正常。你也会看到存储该数据库的磁盘上产生了大量的IO,因为自动统计统计做了大量的表查询,并且自动统计不断循环运行。
当在数据库上开启异步自动更新统计信息,当自动统计被SQL Server触发时,查询不会等待更新统计信息命令去完成。而更新统计信息命令会在后台运行,让查询继续正常运行。现在查询将会使用旧的也许可用的统计信息运行,在这种情况下,它们在2秒之前可用,因此如果它们用于数秒也没有什么大不了。
不推荐在每个数据库上开启异步更新统计信息设置。所有的小数据库都会在超时时间内很好的更新统计信息。
对于需要开启异步更新统计信息的表,可以定时手动更新同步信息。
设置异步更新统计信息
SELECT name, is_auto_update_stats_on, is_auto_update_stats_async_on
FROM sys.databases
ALTER DATABASE YourDBName SET AUTO_UPDATE_STATISTICS_ASYNC ON
ALTER DATABASE YourDBName SET AUTO_UPDATE_STATISTICS ON
开启跟踪标记2371
USE master
GO
--以下示例以全局方式打开跟踪标记 2371。
DBCC TRACEON (2371 ,-1)
GO
DBCC TRACESTATUS (2371,-1)
GO
其他操作参考如下:
UPDATE STATISTICS
https://msdn.microsoft.com/zh-cn/library/ms187348%28v=sql.105%29.aspx
sp_updatestats
https://msdn.microsoft.com/zh-cn/library/ms173804%28v=sql.105%29.aspx
sp_autostats
https://msdn.microsoft.com/en-us/library/ms188775.aspx
DBCC SHOW_STATISTICS
https://msdn.microsoft.com/en-us/library/ms174384.aspx
STATS_DATE
https://msdn.microsoft.com/zh-cn/library/ms190330%28v=sql.105%29.aspx
后续处理:
修改统计信息更新策略为AUTO_UPDATE_STATISTICS_ASYNC
执行归档删除
执行更新归档表统计信息
将统计信息更新策略修改为同步更新
开启跟踪标记2371
考虑到该库的实时性、业务准确性要求极高,在归档删除完成后,将策略改为同步更新,并开启跟踪标记2371让SQL Server动态决定更小的更新阈值。
若该库没有这么高的要求,可以考虑对拥有超级大表的库设置异步更新,归档删除后,更新该表统计信息,并创建维护作业定时更新该表统计信息。

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何在Microsoft Word中删除作者和上次修改的信息
Apr 15, 2023 am 11:43 AM
如何在Microsoft Word中删除作者和上次修改的信息
Apr 15, 2023 am 11:43 AM
Microsoft Word文档在保存时包含一些元数据。这些详细信息用于在文档上识别,例如创建时间、作者是谁、修改日期等。它还具有其他信息,例如字符数,字数,段落数等等。如果您可能想要删除作者或上次修改的信息或任何其他信息,以便其他人不知道这些值,那么有一种方法。在本文中,让我们看看如何删除文档的作者和上次修改的信息。删除微软Word文档中的作者和最后修改的信息步骤 1 –转到
 如何与NameDrop共享联系人详细信息:iOS 17的操作指南
Sep 16, 2023 pm 06:09 PM
如何与NameDrop共享联系人详细信息:iOS 17的操作指南
Sep 16, 2023 pm 06:09 PM
在iOS17中,有一个新的AirDrop功能,让你通过触摸两部iPhone来与某人交换联系信息。它被称为NameDrop,这是它的工作原理。NameDrop允许您简单地将iPhone放在他们的iPhone附近以交换联系方式,而不是输入新人的号码来给他们打电话或发短信,以便他们拥有您的号码。将两个设备放在一起将自动弹出联系人共享界面。点击弹出窗口会显示一个人的联系信息及其联系人海报(您可以自定义和编辑自己的照片,也是iOS17的新功能)。该屏幕还包括“仅接收”或共享您自己的联系信息作为响应的选项。
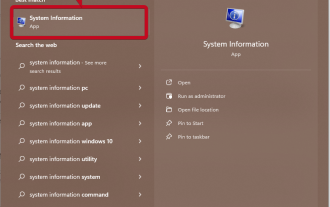 获取 Windows 11 中 GPU 的方法及显卡详细信息检查
Nov 07, 2023 am 11:21 AM
获取 Windows 11 中 GPU 的方法及显卡详细信息检查
Nov 07, 2023 am 11:21 AM
使用系统信息单击“开始”,然后输入“系统信息”。只需单击程序,如下图所示。在这里,您可以找到大多数系统信息,而显卡信息也是您可以找到的一件事。在“系统信息”程序中,展开“组件”,然后单击“显示”。让程序收集所有必要的信息,一旦准备就绪,您就可以在系统上找到特定于显卡的名称和其他信息。即使您有多个显卡,您也可以从这里找到与连接到计算机的专用和集成显卡相关的大多数内容。使用设备管理器Windows11就像大多数其他版本的Windows一样,您也可以从设备管理器中找到计算机上的显卡。单击“开始”,然后
 PHP秒杀系统中的价格策略和促销活动设计要点
Sep 19, 2023 pm 02:18 PM
PHP秒杀系统中的价格策略和促销活动设计要点
Sep 19, 2023 pm 02:18 PM
PHP秒杀系统中的价格策略和促销活动设计要点在一个秒杀系统中,价格策略和促销活动设计是非常重要的一部分。合理的价格策略和精心设计的促销活动可以吸引用户参与秒杀活动,提升系统的用户体验和盈利能力。下面将详细介绍PHP秒杀系统中的价格策略和促销活动设计要点,并提供具体的代码示例。一、价格策略设计要点确定基准价格:在秒杀系统中,基准价格是指商品正常销售时的价格。在
 exe转php:实现功能扩展的有效策略
Mar 04, 2024 pm 09:36 PM
exe转php:实现功能扩展的有效策略
Mar 04, 2024 pm 09:36 PM
EXE转PHP:实现功能扩展的有效策略随着互联网的发展,越来越多的应用程序开始向web化迁移,以实现更大范围的用户访问和更便捷的操作。在这个过程中,将原本以EXE(执行文件)方式运行的功能转化为PHP脚本的需求也在逐渐增加。本文将探讨如何将EXE转换为PHP来实现功能扩展,同时给出具体的代码示例。为什么将EXE转换为PHP跨平台性:PHP是一种跨平台的语言
 利用多光照信息的单视角NeRF算法S^3-NeRF,可恢复场景几何与材质信息
Apr 13, 2023 am 10:58 AM
利用多光照信息的单视角NeRF算法S^3-NeRF,可恢复场景几何与材质信息
Apr 13, 2023 am 10:58 AM
目前图像 3D 重建工作通常采用恒定自然光照条件下从多个视点(multi-view)捕获目标场景的多视图立体重建方法(Multi-view Stereo)。然而,这些方法通常假设朗伯表面,并且难以恢复高频细节。另一种场景重建方法是利用固定视点但不同点光源下捕获的图像。例如光度立体 (Photometric Stereo) 方法就采用这种设置并利用其 shading 信息来重建非朗伯物体的表面细节。然而,现有的单视图方法通常采用法线贴图(normal map)或深度图(depth map)来表征可
 NameDrop 如何在 iPhone 上工作(以及如何禁用它)
Nov 30, 2023 am 11:53 AM
NameDrop 如何在 iPhone 上工作(以及如何禁用它)
Nov 30, 2023 am 11:53 AM
在iOS17中,有一项新的AirDrop功能,可让您通过同时触摸两部iPhone来与某人交换联系信息。它被称为NameDrop,这是它的实际工作原理。NameDrop无需输入新人的号码来给他们打电话或发短信,以便他们拥有您的号码,您只需将iPhone靠近他们的iPhone即可交换联系方式。将两台设备放在一起会自动弹出联系人共享界面。点击弹出窗口会显示一个人的联系信息和他们的联系人海报(您可以自定义和编辑的您自己的照片,也是iOS17的新功能)。该屏幕还包括“仅接收”或共享您自己的联系信息作为响应
 微信收到信息延迟是怎么回事
Sep 19, 2023 pm 03:02 PM
微信收到信息延迟是怎么回事
Sep 19, 2023 pm 03:02 PM
微信收到信息延迟的原因可能是网络问题、服务器负载、版本问题、设备问题、消息发送问题或其他因素等。详细介绍:1、网络问题,微信收到信息的延迟可能与网络连接有关,如果网络连接不稳定或信号弱,可能导致信息传输延迟,请确保手机已经连接到稳定的网络,并且网络信号强度良好;2、服务器负载,当微信服务器负载较高时,可能会导致信息传输的延迟,特别是在繁忙的时间段或大量用户同时使用微信时等等。
