

我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下

今天这篇文章的重点是使用 ChatGPT API 创建私人语音 Chatbot Web 应用程序。目的是探索和发现人工智能的更多潜在用例和商业机会。我将逐步指导您完成开发过程,以确保您理解并可以复制自己的过程。
为什么需要
- 不是每个人都欢迎基于打字的服务,想象一下仍在学习写作技巧的孩子或无法在屏幕上正确看到单词的老年人。基于语音的 AI Chatbot 是解决这个问题的方法,就像它如何帮助我的孩子要求他的语音 Chatbot 给他读睡前故事一样。
- 鉴于现有可用的助手选项,例如,苹果的 Siri 和亚马逊的 Alexa,在 GPT 模型中加入语音交互可以开辟更广泛的可能性。ChatGPT API 具有创建连贯且与上下文相关的响应的卓越能力的优势,结合基于语音的智能家居连接的想法,可能会提供大量的商机。我们在本文中创建的语音助手将作为入口。
足够的理论,让我们开始吧。
1.框图
在这个应用程序中,我们按处理顺序分为三个关键模块:
- Bokeh 和 Web Speech API 的语音转文本
- 通过 OpenAI GPT-3.5 API 完成聊天
- gTTS 文本转语音
Web框架由Streamlit构建。
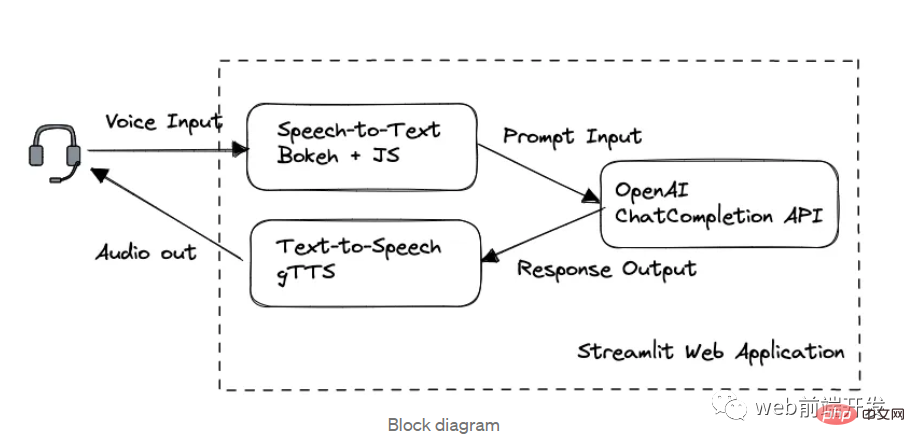
如果您已经知道如何使用 GPT 3.5 模型下的 OpenAI API 以及如何使用 Streamlit 设计 Web 应用程序,建议您跳过第 1 部分和第 2 部分以节省阅读时间。
2. OpenAI GPT API
获取您的 API 密钥
如果您已经拥有一个 OpenAI API 密钥,请坚持使用它而不是创建一个新密钥。但是,如果您是 OpenAI 新手,请注册一个新帐户并在您的帐户菜单中找到以下页面:
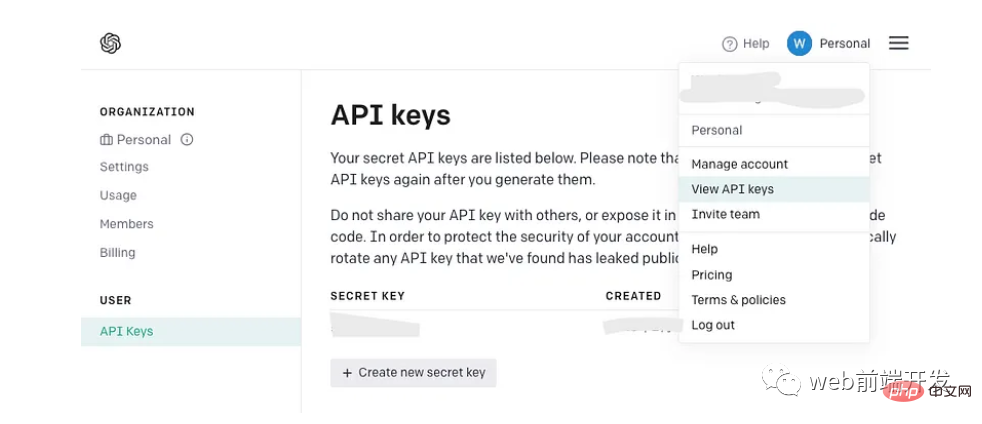
生成 API 密钥后,请记住它只会显示一次,因此请确保将其复制到安全的地方以备将来使用。
ChatCompletion API 的使用
目前GPT-4.0刚刚发布,该模型的API还没有完全发布,所以我将介绍开发仍然是GPT 3.5模型,它足以完成我们的AI语音Chatbot演示。
现在让我们看一下来自 OpenAI 的最简单的演示,以了解 ChatCompletion API(或称为 gpt-3.5 API 或 ChatGPT API)的基本定义:
安装包:
!pip install opena
如果您之前从 OpenAI 开发了一些遗留 GPT 模型,您可能必须通过 pip 升级您的包:
!pip install --upgrade openai
创建并发送提示:
import openai
complete = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)接收文本响应:
message=complete.choices[0].message.content
因为 GPT 3.5 API 是基于聊天的文本完成 API,所以请确保 ChatCompletion 请求的消息正文包含对话历史记录作为上下文,您希望模型参考更上下文相关的响应来响应您的当前请求。
为了实现此功能,消息体的列表对象应按以下顺序组织:
- 系统消息定义为通过在消息列表顶部的内容中添加指令来设置聊天机器人的行为。如介绍中所述,目前此功能尚未在 gpt-3.5-turbo-0301 中完全释放。
- 用户消息表示用户的输入或查询,而助手消息是指来自 GPT-3.5 API 的相应响应。这样的成对对话为有关上下文的模型提供了参考。
- 最后一条用户消息是指当前时刻请求的提示。
3. 网页开发
我们将继续使用强大的 Streamlit 库来构建 Web 应用程序。
Streamlit 是一个开源框架,它使数据科学家和开发人员能够快速构建和共享用于机器学习和数据科学项目的交互式 Web 应用程序。它还提供了一堆小部件,只需要一行 python 代码即可创建,如 st.table(...)。
如果您不太擅长 Web 开发并且不愿意像我一样构建大型商业应用程序,Streamlit 始终是您的最佳选择之一,因为它几乎不需要 HTML 方面的专业知识。
让我们看一个构建 Streamlit Web 应用程序的快速示例:
安装包:
!pip install streamlit
创建一个 Python 文件“demo.py”:
import streamlit as st
st.write("""
# My First App
Hello *world!*
""")在本地机器或远程服务器上运行:
!python -m streamlit run demo.py
打印此输出后,您可以通过列出的地址和端口访问您的网站:
You can now view your Streamlit app in your browser. Network URL: http://xxx.xxx.xxx.xxx:8501 External URL: http://xxx.xxx.xxx.xxx:8501

Streamlit 提供的所有小部件的用法可以在其文档页面中找到:https://docs.streamlit.io/library/api-reference
4.语音转文字的实现
此 AI 语音聊天机器人的主要功能之一是它能够识别用户语音并生成我们的 ChatCompletion API 可用作输入的适当文本。
OpenAI 的 Whisper API 提供的高质量语音识别是一个很好的选择,但它是有代价的。或者,来自 Javascript 的免费 Web Speech API 提供可靠的多语言支持和令人印象深刻的性能。
虽然开发 Python 项目似乎与定制的 Javascript 不兼容,但不要害怕!在下一部分中,我将介绍一种在 Python 程序中调用 Javascript 代码的简单技术。
不管怎样,让我们看看如何使用 Web Speech API 快速开发语音转文本演示。您可以找到它的文档(地址:https://wicg.github.io/speech-api/)。
语音识别的实现可以很容易地完成,如下所示。
var recognition = new webkitSpeechRecognition(); recognition.continuous = false; recognition.interimResults = true; recognition.lang = 'en'; recognition.start();
通过方法 webkitSpeechRecognition() 初始化识别对象后,需要定义一些有用的属性。continuous 属性表示您是否希望 SpeechRecognition 函数在语音输入的一种模式处理成功完成后继续工作。
我将其设置为 false,因为我希望语音聊天机器人能够以稳定的速度根据用户语音输入生成每个答案。
设置为 true 的 interimResults 属性将在用户语音期间生成一些中间结果,以便用户可以看到从他们的语音输入输出的动态消息。
lang 属性将设置请求识别的语言。请注意,如果它在代码中是未设置,则默认语言将来自 HTML 文档根元素和关联的层次结构,因此在其系统中使用不同语言设置的用户可能会有不同的体验。
识别对象有多个事件,我们使用 .onresult 回调来处理来自中间结果和最终结果的文本生成结果。
recognition.onresult = function (e) {
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
}5.引入Bokeh库
从用户界面的定义来看,我们想设计一个按钮来启动我们在上一节中已经用 Javascript 实现的语音识别。

Streamlit 库不支持自定义 JS 代码,所以我们引入了 Bokeh。Bokeh 库是另一个强大的 Python 数据可视化工具。可以支持我们的演示的最佳部分之一是嵌入自定义 Javascript 代码,这意味着我们可以在 Bokeh 的按钮小部件下运行我们的语音识别脚本。
为此,我们应该安装 Bokeh 包。为了兼容后面会提到的streamlit-bokeh-events库,Bokeh的版本应该是2.4.2:
!pip install bokeh==2.4.2
导入按钮和 CustomJS:
from bokeh.models.widgets import Button from bokeh.models import CustomJS
创建按钮小部件:
spk_button = Button(label='SPEAK', button_type='success')
定义按钮点击事件:
spk_button.js_on_event("button_click", CustomJS(code="""
...js code...
"""))定义了.js_on_event()方法来注册spk_button的事件。
在这种情况下,我们注册了“button_click”事件,该事件将在用户单击后触发由 CustomJS() 方法嵌入的 JS 代码块…js 代码…的执行。
Streamlit_bokeh_event
speak 按钮及其回调方法实现后,下一步是将 Bokeh 事件输出(识别的文本)连接到其他功能块,以便将提示文本发送到 ChatGPT API。
幸运的是,有一个名为“Streamlit Bokeh Events”的开源项目专为此目的而设计,它提供与 Bokeh 小部件的双向通信。你可以在这里找到它的 GitHub 页面。
这个库的使用非常简单。首先安装包:
!pip install streamlit-bokeh-events
通过 streamlit_bokeh_events 方法创建结果对象。
result = streamlit_bokeh_events( bokeh_plot = spk_button, events="GET_TEXT,GET_ONREC,GET_INTRM", key="listen", refresh_on_update=False, override_height=75, debounce_time=0)
使用 bokeh_plot 属性来注册我们在上一节中创建的 spk_button。使用 events 属性来标记多个自定义的 HTML 文档事件
- GET_TEXT 接收最终识别文本
- GET_INTRM 接收临时识别文本
- GET_ONREC 接收语音处理阶段
我们可以使用 JS 函数 document.dispatchEvent(new CustomEvent(…)) 来生成事件,例如 GET_TEXT 和 GET_INTRM 事件:
spk_button.js_on_event("button_click", CustomJS(code="""
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
var value, value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
recognition.start();
}
"""))并且,检查事件 GET_INTRM 处理的 result.get() 方法,例如:
tr = st.empty()
if result:
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", result.get("GET_INTRM"))这两个代码片段表明,当用户正在讲话时,任何临时识别文本都将显示在 Streamlit text_area 小部件上:
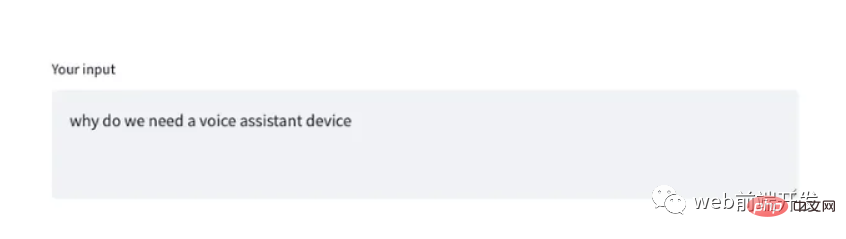
6. 文字转语音实现
提示请求完成,GPT-3.5模型通过ChatGPT API生成响应后,我们通过Streamlit st.write()方法将响应文本直接显示在网页上。

但是,我们需要将文本转换为语音,这样我们的 AI 语音 Chatbot 的双向功能才能完全完成。
有一个名为“gTTS”的流行 Python 库能够完美地完成这项工作。在与谷歌翻译的文本转语音 API 接口后,它支持多种格式的语音数据输出,包括 mp3 或 stdout。你可以在这里找到它的 GitHub 页面。
只需几行代码即可完成转换。首先安装包:
!pip install gTTS
在这个演示中,我们不想将语音数据保存到文件中,所以我们可以调用 BytesIO() 来临时存储语音数据:
sound = BytesIO() tts = gTTS(output, lang='en', tld='com') tts.write_to_fp(sound)
输出的是要转换的文本字符串,你可以根据自己的喜好,通过tld从不同的google域中选择不同的语言by lang。例如,您可以设置 tld='co.uk' 以生成英式英语口音。
然后,通过 Streamlit 小部件创建一个像样的音频播放器:
st.audio(sound)
全语音聊天机器人
要整合上述所有模块,我们应该完成完整的功能:
- 已完成与 ChatCompletion API 的交互,并在用户和助手消息块中定义了附加的历史对话。使用 Streamlit 的 st.session_state 来存储运行变量。
- 考虑到 .onspeechstart()、.onsoundend() 和 .onerror() 等多个事件以及识别过程,在 SPEAK 按钮的 CustomJS 中完成了事件生成。
- 完成事件“GET_TEXT、GET_ONREC、GET_INTRM”的事件处理,以在网络界面上显示适当的信息,并管理用户讲话时的文本显示和组装。
- 所有必要的 Streamit 小部件
请找到完整的演示代码供您参考:
import streamlit as st
from bokeh.models.widgets import Button
from bokeh.models import CustomJS
from streamlit_bokeh_events import streamlit_bokeh_events
from gtts import gTTS
from io import BytesIO
import openai
openai.api_key = '{Your API Key}'
if 'prompts' not in st.session_state:
st.session_state['prompts'] = [{"role": "system", "content": "You are a helpful assistant. Answer as concisely as possible with a little humor expression."}]
def generate_response(prompt):
st.session_state['prompts'].append({"role": "user", "content":prompt})
completinotallow=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages = st.session_state['prompts']
)
message=completion.choices[0].message.content
return message
sound = BytesIO()
placeholder = st.container()
placeholder.title("Yeyu's Voice ChatBot")
stt_button = Button(label='SPEAK', button_type='success', margin = (5, 5, 5, 5), width=200)
stt_button.js_on_event("button_click", CustomJS(code="""
var value = "";
var rand = 0;
var recognition = new webkitSpeechRecognition();
recognition.continuous = false;
recognition.interimResults = true;
recognition.lang = 'en';
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'start'}));
recognition.onspeechstart = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'running'}));
}
recognition.onsoundend = function () {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.onresult = function (e) {
var value2 = "";
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
value += e.results[i][0].transcript;
rand = Math.random();
} else {
value2 += e.results[i][0].transcript;
}
}
document.dispatchEvent(new CustomEvent("GET_TEXT", {detail: {t:value, s:rand}}));
document.dispatchEvent(new CustomEvent("GET_INTRM", {detail: value2}));
}
recognition.onerror = function(e) {
document.dispatchEvent(new CustomEvent("GET_ONREC", {detail: 'stop'}));
}
recognition.start();
"""))
result = streamlit_bokeh_events(
bokeh_plot = stt_button,
events="GET_TEXT,GET_ONREC,GET_INTRM",
key="listen",
refresh_on_update=False,
override_height=75,
debounce_time=0)
tr = st.empty()
if 'input' not in st.session_state:
st.session_state['input'] = dict(text='', sessinotallow=0)
tr.text_area("**Your input**", value=st.session_state['input']['text'])
if result:
if "GET_TEXT" in result:
if result.get("GET_TEXT")["t"] != '' and result.get("GET_TEXT")["s"] != st.session_state['input']['session'] :
st.session_state['input']['text'] = result.get("GET_TEXT")["t"]
tr.text_area("**Your input**", value=st.session_state['input']['text'])
st.session_state['input']['session'] = result.get("GET_TEXT")["s"]
if "GET_INTRM" in result:
if result.get("GET_INTRM") != '':
tr.text_area("**Your input**", value=st.session_state['input']['text']+' '+result.get("GET_INTRM"))
if "GET_ONREC" in result:
if result.get("GET_ONREC") == 'start':
placeholder.image("recon.gif")
st.session_state['input']['text'] = ''
elif result.get("GET_ONREC") == 'running':
placeholder.image("recon.gif")
elif result.get("GET_ONREC") == 'stop':
placeholder.image("recon.jpg")
if st.session_state['input']['text'] != '':
input = st.session_state['input']['text']
output = generate_response(input)
st.write("**ChatBot:**")
st.write(output)
st.session_state['input']['text'] = ''
tts = gTTS(output, lang='en', tld='com')
tts.write_to_fp(sound)
st.audio(sound)
st.session_state['prompts'].append({"role": "user", "content":input})
st.session_state['prompts'].append({"role": "assistant", "content":output})输入后:
!python -m streamlit run demo_voice.py
您最终会在网络浏览器上看到一个简单但智能的语音聊天机器人。
请注意:不要忘记在弹出请求时允许网页访问您的麦克风和扬声器。
就是这样,一个简单聊天机器人就完成了。
最后,希望您能在本文中找到有用的东西,感谢您的阅读!
以上是我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 于 2023 年 9 月正式推出,是比其前身大幅改进的型号。它被认为是迄今为止最好的人工智能图像生成器之一,能够创建具有复杂细节的图像。然而,在推出时,它不包括
 字节跳动剪映推出 SVIP 超级会员:连续包年 499 元,提供多种 AI 功能
Jun 28, 2024 am 03:51 AM
字节跳动剪映推出 SVIP 超级会员:连续包年 499 元,提供多种 AI 功能
Jun 28, 2024 am 03:51 AM
本站6月27日消息,剪映是由字节跳动旗下脸萌科技开发的一款视频剪辑软件,依托于抖音平台且基本面向该平台用户制作短视频内容,并兼容iOS、安卓、Windows、MacOS等操作系统。剪映官方宣布会员体系升级,推出全新SVIP,包含多种AI黑科技,例如智能翻译、智能划重点、智能包装、数字人合成等。价格方面,剪映SVIP月费79元,年费599元(本站注:折合每月49.9元),连续包月则为59元每月,连续包年为499元每年(折合每月41.6元)。此外,剪映官方还表示,为提升用户体验,向已订阅了原版VIP
 微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉
Jun 11, 2024 pm 03:57 PM
微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉
Jun 11, 2024 pm 03:57 PM
大型语言模型(LLM)是在巨大的文本数据库上训练的,在那里它们获得了大量的实际知识。这些知识嵌入到它们的参数中,然后可以在需要时使用。这些模型的知识在训练结束时被“具体化”。在预训练结束时,模型实际上停止学习。对模型进行对齐或进行指令调优,让模型学习如何充分利用这些知识,以及如何更自然地响应用户的问题。但是有时模型知识是不够的,尽管模型可以通过RAG访问外部内容,但通过微调使用模型适应新的领域被认为是有益的。这种微调是使用人工标注者或其他llm创建的输入进行的,模型会遇到额外的实际知识并将其整合
 为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
编辑|ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choicequestions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答
 SOTA性能,厦大多模态蛋白质-配体亲和力预测AI方法,首次结合分子表面信息
Jul 17, 2024 pm 06:37 PM
SOTA性能,厦大多模态蛋白质-配体亲和力预测AI方法,首次结合分子表面信息
Jul 17, 2024 pm 06:37 PM
编辑|KX在药物研发领域,准确有效地预测蛋白质与配体的结合亲和力对于药物筛选和优化至关重要。然而,目前的研究没有考虑到分子表面信息在蛋白质-配体相互作用中的重要作用。基于此,来自厦门大学的研究人员提出了一种新颖的多模态特征提取(MFE)框架,该框架首次结合了蛋白质表面、3D结构和序列的信息,并使用交叉注意机制进行不同模态之间的特征对齐。实验结果表明,该方法在预测蛋白质-配体结合亲和力方面取得了最先进的性能。此外,消融研究证明了该框架内蛋白质表面信息和多模态特征对齐的有效性和必要性。相关研究以「S
 布局 AI 等市场,格芯收购泰戈尔科技氮化镓技术和相关团队
Jul 15, 2024 pm 12:21 PM
布局 AI 等市场,格芯收购泰戈尔科技氮化镓技术和相关团队
Jul 15, 2024 pm 12:21 PM
本站7月5日消息,格芯(GlobalFoundries)于今年7月1日发布新闻稿,宣布收购泰戈尔科技(TagoreTechnology)的功率氮化镓(GaN)技术及知识产权组合,希望在汽车、物联网和人工智能数据中心应用领域探索更高的效率和更好的性能。随着生成式人工智能(GenerativeAI)等技术在数字世界的不断发展,氮化镓(GaN)已成为可持续高效电源管理(尤其是在数据中心)的关键解决方案。本站援引官方公告内容,在本次收购过程中,泰戈尔科技公司工程师团队将加入格芯,进一步开发氮化镓技术。G
 SK 海力士 8 月 6 日将展示 AI 相关新品:12 层 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
SK 海力士 8 月 6 日将展示 AI 相关新品:12 层 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
本站8月1日消息,SK海力士今天(8月1日)发布博文,宣布将出席8月6日至8日,在美国加利福尼亚州圣克拉拉举行的全球半导体存储器峰会FMS2024,展示诸多新一代产品。未来存储器和存储峰会(FutureMemoryandStorage)简介前身是主要面向NAND供应商的闪存峰会(FlashMemorySummit),在人工智能技术日益受到关注的背景下,今年重新命名为未来存储器和存储峰会(FutureMemoryandStorage),以邀请DRAM和存储供应商等更多参与者。新产品SK海力士去年在
 SearchGPT:开放人工智能用自己的人工智能搜索引擎挑战谷歌
Jul 30, 2024 am 09:58 AM
SearchGPT:开放人工智能用自己的人工智能搜索引擎挑战谷歌
Jul 30, 2024 am 09:58 AM
开放人工智能终于进军搜索领域。这家旧金山公司最近宣布了一款具有搜索功能的新人工智能工具。 The Information 于今年 2 月首次报道,该新工具被恰当地称为 SearchGPT,并具有 c
