
AI面试机器人通过利用灵犀智能语音语义平台的人机语音对话能力模拟招聘者与求职者进行多轮语音沟通,达到在线化面试的效果。本文详细描述了AI面试机器人的后端架构组成、对话引擎设计、资源需求预估策略、服务性能优化方法。AI面试机器人上线一年多来,累积接待了 百万 次面试请求,极大地提升了招聘者招聘效率、求职者面试体验。
58同城生活服务平台包括房产、汽车、招聘、本地服务(黄页)四大老牌业务,平台连接着海量的C端用户和B端商家,B端商家可以在平台上发布房源、车源、职位、生活服务等各类信息(我们称之为“帖子”),平台将这些帖子分发给C端用户供其浏览从而帮助他们获取自己所需要的信息,帮助B端商家分发传播信息从而获取目标客户,为了提升B端商家获取目标客户效率,提升C端用户体验,平台在个性化推荐、智能化连接等方面持续地在进行着产品创新。
以招聘为例,受2020年疫情的影响,传统的线下招聘面试方式受到了较大的冲击,平台上求职者通过微聊、视频等在线化面试请求量急增,由于一位招聘者在同一时刻只能与一位求职者建立在线化的视频面试渠道,导致求职者、招聘者两端链接成功率较低。为了提升求职者用户体验、提高招聘者面试效率,58同城TEG AI Lab与招聘业务线等多个部门协同打造了一款智能化招聘面试工具:神奇面试间。该产品主要由三大部分组成:客户端、音视频通信、AI面试机器人(参见: 人物|李忠:AI面试机器人打造智能化招聘 )。
本文将主要聚焦在AI面试机器人上,AI面试机器人通过利用灵犀智能语音语义平台的人机语音对话的能力模拟招聘者与求职者进行多轮语音沟通,达到在线化面试的效果。一方面可解决一位招聘者只能响应一位求职者的在线化面试请求,提升招聘者作业效率;另一方面能满足求职者不限时间、地点进行视频面试,同时将个人简历从传统的文字描述介绍转换成更加直观生动的视频化自我展示。本文详细描述了AI面试机器人的后端架构组成、人机语音对话引擎设计、如何预估资源需求应对流量扩容、如何优化服务性能来保证整体AI面试机器人服务的稳定性、可用性。
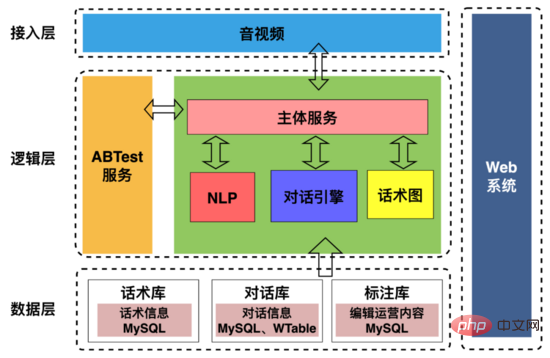
AI面试机器人架构如上图所示,包括:
1、接入层:主要用来处理与上下游的交互,包括与音视频端约定通信协议;提取面试中用户画像、抽取机器人用户交互时间轴信息下发招聘部门。
2、逻辑层:主要是用来处理机器人和用户的对话交互,包括将机器人的问题文本合成为语音数据发送给用户,对用户进行提问,让机器人可以“ 说得出 ”;用户回复后,将用户回复语音数据通过VAD(Voice Activity Detection)断句,流式语音识别为文本,让机器人“ 听得见 ”;对话引擎根据用户的回复文本和话术图决定回复内容然后合成语音发送给用户,从而实现机器人和用户的“ 沟通交流 ”。
3、数据层:存放话术图、对话记录、标注信息等基础数据。
4、web系统:可视化配置话术结构、对话策略、标注面试对话数据。
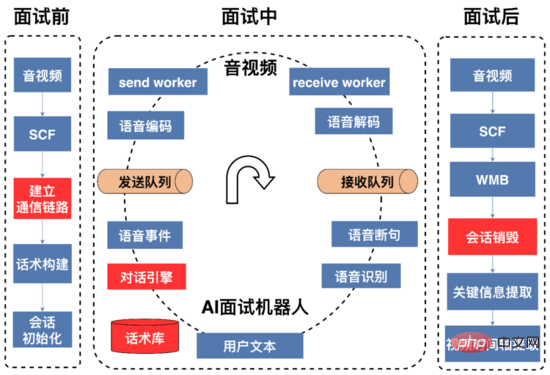
一次完整的AI面试流程如上图所示,可以被划分为面试前、面试中、面试后三阶段。
面试前: 主要是建立通信链路以及资源初始化,AI面试机器人与音视频端的语音信号是通过 UDP 进行传输的,音视频与AI面试机器人通信所需的 IP 和 端口 是需要动态维护。音视频端通过SCF(SCF是58自主研发的RPC框架)接口发起面试请求,该请求一方面从AI面试机器人处实时动态获取IP与端口资源用于音视频后续将此次面试过程的采集到的语音信号发到AI机器人,另一方面告诉AI机器人需要将响应用户的语音信号所需要发送的IP与端口,由于SCF支持负载均衡,所以音视频端发起的面试请求会随机打到AI面试机器人服务集群上某台机器,这个时候这台机器上的AI面试机器人通过SCF透传的参数获取到音视频端的ip和端口,接下来AI面试机器人服务首先尝试从 可用端口队列 (服务初始化的时候创建的该队列,以队列的数据结构存放可用的端口对)中poll第一个可用端口对(发送端口和接收端口组成的pair),如果获取成功,服务会把这台机器的IP和端口通过SCF面试请求接口返回给音视频端,后续双方就可以进行UDP通信了,面试完成后,服务会把端口对push到可用端口队列中。如果获取端口对失败,服务会通过SCF接口返回给音视频端建立通信失败代码,音视频端可以重试或者放弃此次面试请求。
建立通信流程:
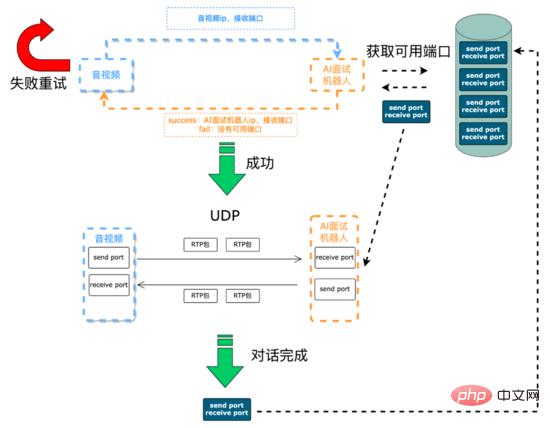
在语音信号传输过程,在系统中我们采用了RTP协议作为音频媒体协议。 RTP协议 即实时传输协议(Real-time Transport Protocol),为ip网上语音、图像、传真等多种需要实时传输的多媒体数据提供 端到端 的实时传输服务。RTP报文由两部分组成:报头和有效载荷。
RTP报头:
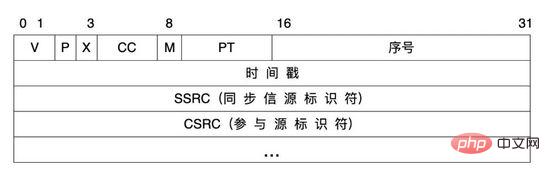
属性解释:
属性 |
解释 |
V |
RTP 协议版本的 版本号 ,占 2 位,当前协议版本号为 2 |
P |
填充标志 ,占 1 位,如果 P=1 ,那么该报文的尾部填充一个或多个额外的 8 位数组,它们不是有效载荷的一部分 |
X |
扩展标志 ,占 1 位,如果 X=1 ,则在 RTP 报头后面跟着一个扩展报头 |
CC |
参与源数, CSRC 计数器,占 4 位,指示 CSRC 标识符的个数 |
M |
标记,占 1 位,不同载荷有不同的含义,对于视频,标记一帧的结束;对于音频,标记会话的开始。 |
PT |
有效载荷类型,占 7 位,用于说明 RTP 报文中有效载荷的类型,如音频、图像等,在流媒体中大部分是用来区分音频流和视频流的,便于客户端解析。 |
序号 |
占 16 位,用来标识发送者所发送 RTP 报文的序列号, 每发送一个报文 ,序列号增加 1 。这个字段当下层的承载协议用 UDP 的时候,网络情况不好的时候可以用来 检查丢包 。同时网络出现抖动可以用来对数据进行重新排序。 |
时间戳 |
占 32 位,反应了该 RTP 报文的 第一个八位组的采样时刻 ,接收者可以用时间戳来计算延迟和延迟抖动,并进行同步控制。 |
SSRC |
用于标识同步信源 ,该标识可以随机选择,参加同一个视频会议两个同步信源不能有相同的 SSRC |
CSRC |
每个 CSRC 标识符占 32 位,可以有 0 ~ 15 个。每个 CSRC 标识了包含在该 RTP 报文有效载荷中的所有特约信源。 |
面试中: 在此过程中,AI面试机器人首先发送开场白,开场白文本通过tts(Text To Speech)合成为语音数据,语音数据经过编码,进行压缩,发送到约定好的音视频端的IP和端口,用户根据听到的问题进行相关回复;AI面试机器人将接收到的用户语音流进行解码,通过vad断句、流式语音识别为文本,对话引擎根据用户回复文本和话术结构状态图决定回复内容,AI面试机器人和用户不断对话交互,直到话术结束或者用户挂断面试。
面试后: 一旦AI面试机器人收到音视频关于面试结束的请求,AI面试机器人将回收面试准备阶段申请的资源如端口、线程等;构建用户的画像(涉及到用户最快到岗时间、是否从事过该工作、年龄等信息)提供给招聘方,方便商家进行筛选,以及对面试对话进行录音存储。
录音方案:
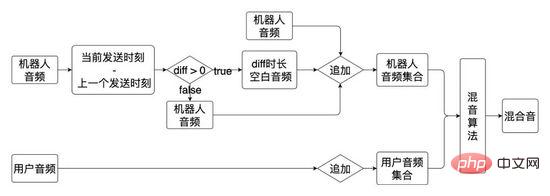
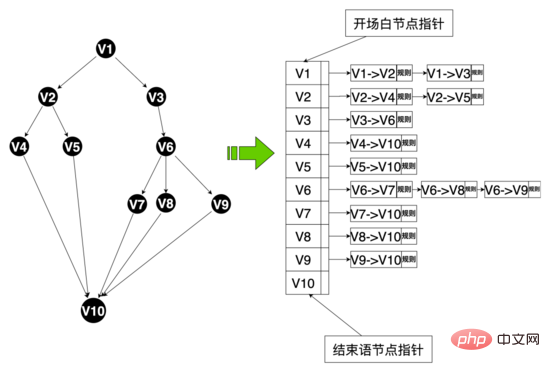
在整个面试流程中AI面试机器人和用户交互是由 对话引擎基于话术流程 驱动的,其中话术是一个有向无环图,最初话术图是两分支话术(所有节点的边
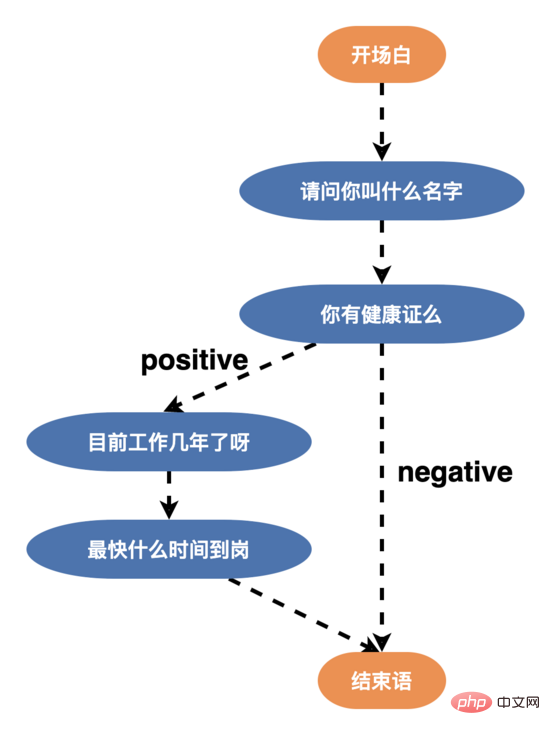
因此为了提高用户的对话意愿,提升机器人的智能对话能力,我们重构了话术结构,设计了多分支话术(某个节点的边 >= 3),如下所示,用户可以根据年龄、学历、性格个性化地回复用户不同的话术,新话术结构上线后,面试完成率超过了 50% 。
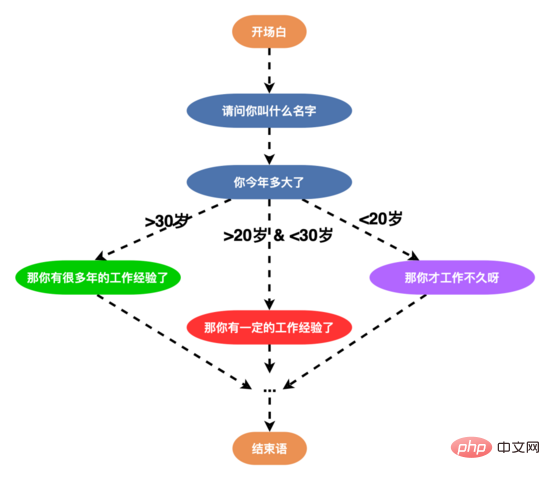
同时为了更加细粒度地设计对话策略,我们在策略链上设计了 节点级 的策略链,可以为单个节点定制个性化的对话策略,满足个性化的对话需求。
数据层面: 为了实现多分支话术,我们重新设计了话术相关的数据结构,抽象出一些数据实体包括:话术表、话术节点、话术边等。话术节点通过话术编号绑定到话术上,同时维护话术文本等属性,话术边维护节点之间的拓扑关系,有开始节点、结束节点,话术边通过边编号绑定着这个边上的命中正则、语料等规则,同时可以使用边id为这个边定制自己的规则。策略链通过策略链编号绑定不同的策略,话术、节点通过策略链编号绑定不同的策略链。
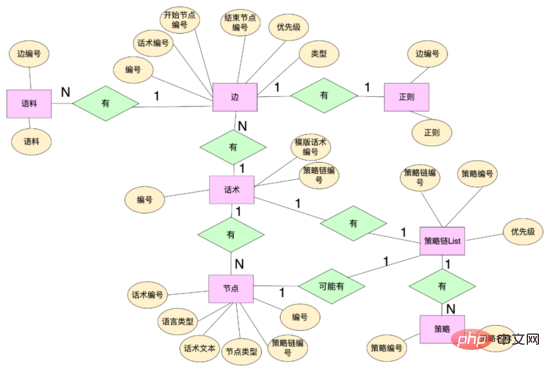
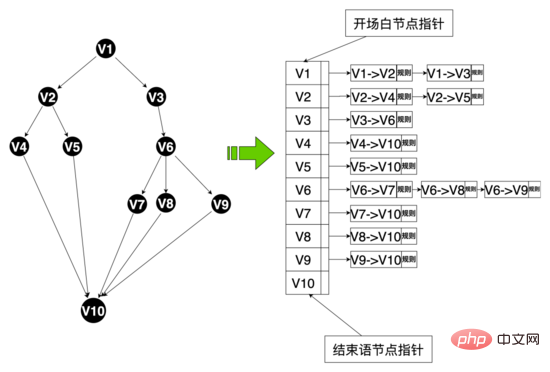
代码层面: 抽象出来边、节点、话术类、话术状态类概念,边和节点是数据层的映射,边上还维护了正则、语料等命中逻辑,话术类维护了开场白节点、话术图等关键信息,话术图是整个话术拓扑结构的映射,维护了节点和以该节点为开始节点边集合的映射,话术状态类维护了话术的当前状态,包括话术类和当前节点,系统可以根据话术当前节点,从话术图中获取到以该节点为开始节点的所有边(类似 邻接表 ),根据用户当前的回复去匹配不同边上的规则,如果命中,那么话术图就流转到命中边的结束节点,同时从该节点上获取机器人的回复内容,话术结构就流转起来了。
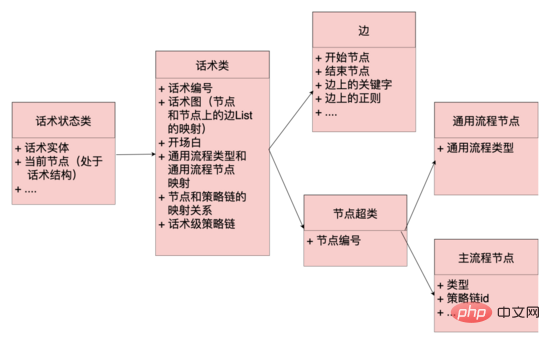
话术图数据结构:
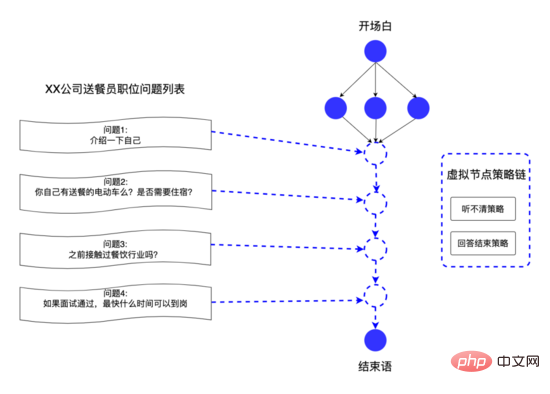
通过以上数据结构,系统平台能快速响应业务方的话术定制需求,例如招聘方可以自定义每个招聘职位的问题,我们将这些问题抽象为话术中的虚拟节点,使用虚拟边将虚拟节点连接起来,从而为不同职位提供个性化的面试问题,实现千人千面的效果。
神奇面试间上线后效果良好,因此业务方希望进行快速扩量,AI面试机器人需要支持最高同时在线千人以上,因此我们从资源管理、资源预估、性能试验、监控四方面入手,有效提升了AI面试机器人服务的性能,线上实际使用中,优化后服务可同时接待的面试请求能力为优化前 20倍 。
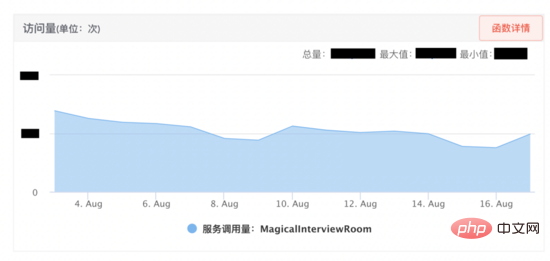
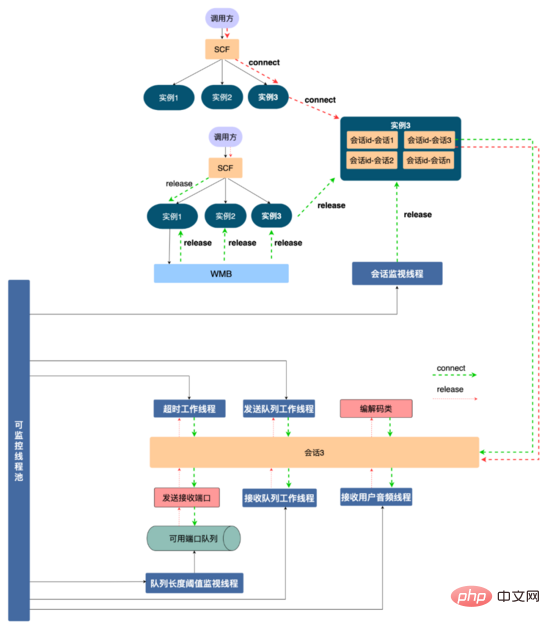
资源管理方案: 为了更好地管理服务中使用到的资源,防止出现资源耗尽,我们设计了如下所示的资源管理方案。首先AI面试机器人跟音视频是通过SCF约定通信协议,由于SCF是负载均衡的,所以调用方请求会 随机 打到集群中某台机器上,比如某一次请求打到服务实例1,通信协议可以将这通面试的交互绑定到该实例,接下来是抽象出来一个 会话 的概念(代码层面是一个会话类,每一个会话是一个线程),将这一通面试中申请的资源比如发送接收端口、编解码类、各种线程资源注册到会话上,在代码上保证释放会话时一定释放注册在会话上的资源,这样不同视频面试通过 线程的隔离性 实现了资源隔离,从而方便进行资源管理。
同时通过会话id(调用方通过通信协议约定好的,具有全局唯一性)将会话实例绑定到会话容器上。用户挂断的时候调用SCF释放资源,由于SCF的随机性,请求可能打到服务实例3,实例3上是没有这通面试的会话,为了释放资源,我们使用WMB(五八同城自研消息队列) 广播 这个释放资源消息,消息体中含有会话id,所有服务实例都会消费到这一条消息,服务实例1含有该会话id,找到与会话id绑定的会话,调用会话的资源释放功能,将使用到的资源释放(其余实例会丢弃该消息)。
如果由于某些原因释放请求没有执行,会话容器有一个 会话监视线程 ,可以扫描会话容器中所有会话的生命周期,为会话设定一个最大的生命周期(比如10分钟),如果会话过期,主动触发会话的资源回收,释放会话资源。同时对于会话中申请的线程、端口等有限资源,我们使用 集中式 管理,使用线程池对线程集中管理,将所有可用端口放入到一个队列中,对队列剩余端口进行监控,保证服务的稳定性和可用性。
机器资源预估:
限制资源 |
瓶颈关注点 |
会话申请的临时资源 |
临时资源是否可以及时回收,比如端口、线程、编解码类等资源。 |
机器网络带宽 |
1000MB/s >> 2500 * 32 KB/s |
机器硬盘资源 |
商家自定义问题 LRU 淘汰策略 |
线程 |
线程池队列中任务大小、任务执行耗时、创建线程数量监控等指标 |
性能实验:
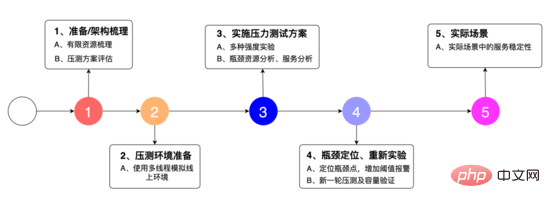
我们设计了如上图所示的实验方案: 1、是对系统的架构进行梳理,发现其中有限的资源,同时整理压力测试方案,2、是使用多线程模拟线上环境,3、是多种强度的强度试验,瓶颈资源的分析,服务的分析。 4、定位瓶颈点,增加阈值报警,重新试验,5、是在实际场景中的服务的稳定性表现。
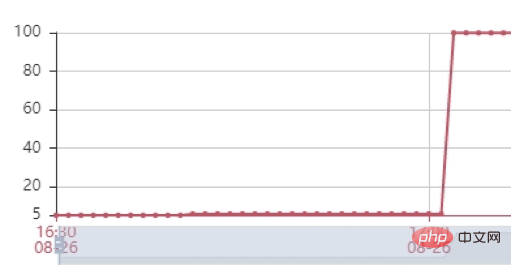
压力测试: 接下来我们进行压力测试,尝试多种强度请求量试验,当使用2500请求/min对接口进行压力测试,发现服务的主要瓶颈是在服务的 堆内存 上。从下图可以看到服务的堆内存很快到达100%,接口无响应。我们dump堆内存后发现堆内存中出现几百个DialingInfo对象,每个对象占用18.75MB,查看代码可知,这个对象使用来存放AI面试机器人和用户的对话内容,allRobotVoiceBuffer和allUserVoiceBuffer两个对象各自占用一半的内存大小,allRobotVoiceBuffer是存放机器人的语音信息(存放形式:byte数组),allUserVoiceBuffer是存放用户的语音信息。
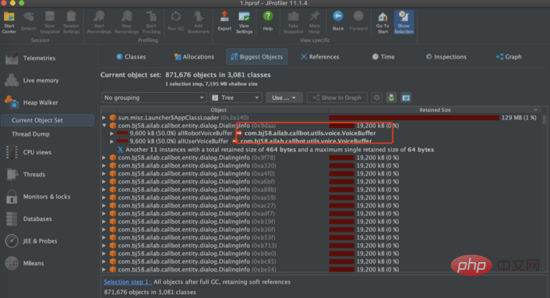
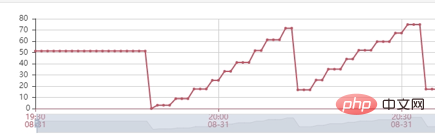
查看代码可以发现allRobotVoiceBuffer和allUserVoiceBuffer这两个对象 初始化 服务的时候就共同占用了18.75MB(这个数值是因为要存放5min的音频数据),我们需要考虑这个初始化大小是否合理,分析神奇面试间历史通话数据,可以看出来 63% 的用户没有回答机器人第一个问题直接挂断面试,因此我们尝试降低这两个对象初始化内存大小,将allRobotVoiceBuffer修改为0.47MB(这个数值为机器人第一个问题音频的大小),allUserVoiceBuffer为0MB,同时由于allRobotVoiceBuffer和allUserVoiceBuffer这两个对象可以ms级别扩容,如果对话内容超过对象大小可以实现扩容不影响服务,修改后我们仍然使用2500min/请求去压力测试,服务可以实现稳定的垃圾回收。
细粒度的监控:
指标类型 |
概述 |
服务关键性指标 |
请求量、成功量、失败量、没有可用端口等 13 个指标 |
资源性指标 |
可用端口队列长度小于阈值、缓存个性化问题超过阈值等 5 个指标 |
流程性指标 |
构建话术失败、下发关键信息失败、下发时间轴失败等 52 个指标 |
线程池监控指标 |
请求创建线程数量、正在执行的任务数量、任务平均耗时 6 个指标 |
职位问答环节指标 |
获取语音答案异常、答案预热平均耗时等 9 个指标 |
ASR 指标 |
自研语音识别平均时长、自研识别失败等 18 个指标 |
Vad 指标 |
调用次数、最大耗时等 4 个指标 |
本 文主要介绍了AI面试机器人的后端架构,AI面试机器人和用户的交互全流程,对话引擎的核心功能以及服务性能优化实践等工作。 后续我们将持续支持神奇面试间项目的功能迭代以及性能优化,进一步将AI面试机器人落地到不同的业务。
1、RTP: A Transport Protocol for Real-Time Applications. H. Schulzrinne R. Frederick S. Casner V. Jacobson
张驰, 58 同城 AI Lab 后端高级开发工程师, 2019 年 12 月加入 58 同城,目前主要从事语音交互相关的后端研发工作。 2016 年硕士毕业于北方工业大学,曾就职于便利蜂、中国电子,从事后端开发工作。
以上是AI面试机器人后端架构实践的详细内容。更多信息请关注PHP中文网其他相关文章!






















