

ViP3D: 通过3D智体query实现端到端视觉轨迹预测

arXiv论文“ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries“,22年8月2日上传,清华、上海(姚)期智研究院、CMU、复旦、理想汽车和MIT等的联合工作。

现有的自主驾驶流水线将感知模块与预测模块分开。这两个模块通过人工选择的特征进行通信,如智体框和轨迹作为接口。由于这种分离,预测模块仅从感知模块接收部分信息。更糟糕的是,来自感知模块的错误可能会传播和累积,从而对预测结果产生不利影响。
这项工作提出ViP3D,一种视觉轨迹预测流水线,利用原始视频的丰富信息预测场景中智体的未来轨迹。ViP3D在整个流水线中使用稀疏智体query,使其完全可微分和可解释。此外,提出一种新的端到端视觉轨迹预测任务的评估指标,端到端预测精度(EPA,End-to-end Prediction Accuracy),其在综合考虑感知和预测精度的同时,对预测轨迹与地面真实轨迹进行评分。
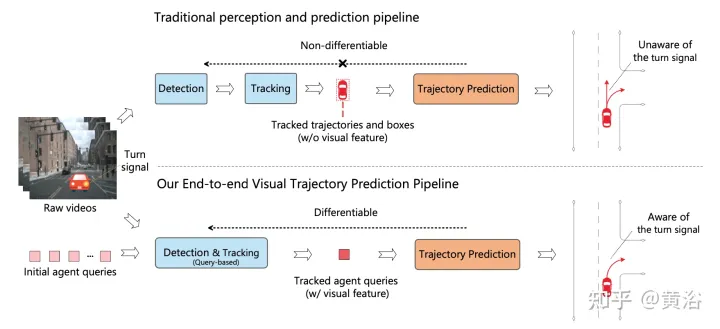
如图是传统多步级联流水线与ViP3D的比较:传统的流水线涉及多个不可微模块,例如检测、跟踪和预测;ViP3D将多视图视频作为输入,以端到端的方式生成预测轨迹,可有效利用视觉信息,比如车辆转向信号。
ViP3D旨在以端到端的方式解决原始视频的轨迹预测问题。具体而言,给定多视图视频和高清地图,ViP3D预测场景中所有智体的未来轨迹。
ViP3D的总体流程如图所示:首先,基于查询的跟踪器处理来自周围摄像机的多视图视频,获得有视觉特征所跟踪智体的query。智体query中的视觉特征,捕获智体的运动动力学和视觉特征,以及智体之间的关系。之后,轨迹预测器将跟踪智体的query作为输入,并与HD地图特征相关联,最后输出预测的轨迹。
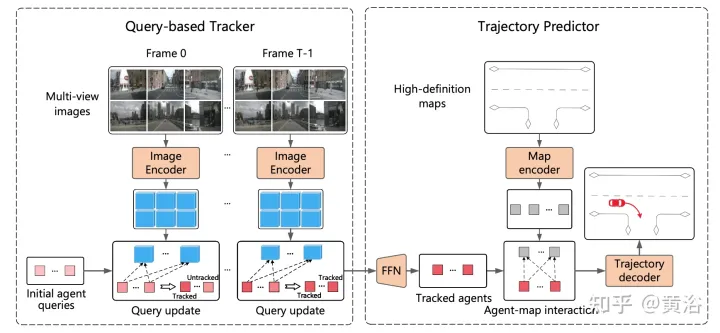
基于query的跟踪器从环绕摄像机的原始视频中提取视觉特征。具体而言,对于每一帧,按照DETR3D提取图像特征。对于时域特征聚合,按照MOTR(“Motr: End-to-end multiple-object tracking with transformer“. arXiv 2105.03247, 2021)设计了一个基于query的跟踪器,包括两个关键步骤:query特征更新和query监督。智体query会随时间更新,建模智体的运动动力学。
大多数现有的轨迹预测方法可分为三个部分:智体编码、地图编码和轨迹解码。在基于query的跟踪之后,获得被跟踪智体的query,该query可以被视为通过智体编码获得的智体特征。因此,剩下的任务是地图编码和轨迹解码。
分别将预测和真值智体表示为无序集Sˆ和S,其中每个智体由当前时间步的智体坐标和K个可能的未来轨迹表示。对于每个智体类型c,计算Scˆ和Sc之间的预测精度。将预测智体和真值智体之间的成本定义为:

这样Scˆ和Sc之间的EPA定义为:

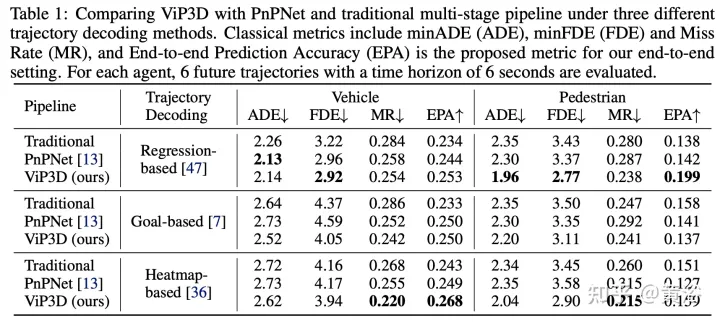
实验结果如下:
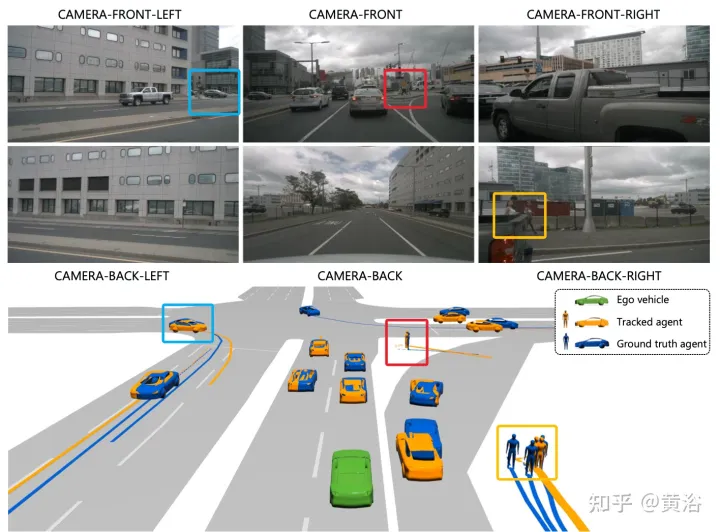
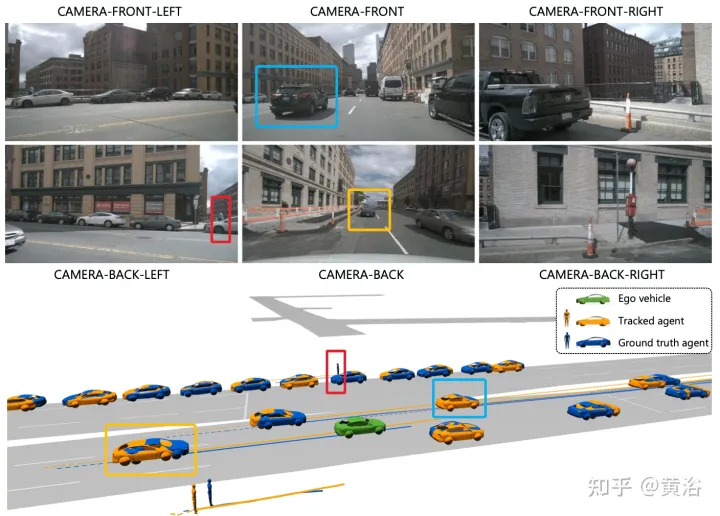
注:这个目标渲染做的不错。
以上是ViP3D: 通过3D智体query实现端到端视觉轨迹预测的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
写在前面&笔者的个人理解目前,在整个自动驾驶系统当中,感知模块扮演了其中至关重要的角色,行驶在道路上的自动驾驶车辆只有通过感知模块获得到准确的感知结果后,才能让自动驾驶系统中的下游规控模块做出及时、正确的判断和行为决策。目前,具备自动驾驶功能的汽车中通常会配备包括环视相机传感器、激光雷达传感器以及毫米波雷达传感器在内的多种数据信息传感器来收集不同模态的信息,用于实现准确的感知任务。基于纯视觉的BEV感知算法因其较低的硬件成本和易于部署的特点,以及其输出结果能便捷地应用于各种下游任务,因此受到工业
 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
如此强大的AI模仿能力,真的防不住,完全防不住。现在AI的发展已经达到了这种程度吗?你前脚让自己的五官乱飞,后脚,一模一样的表情就被复现出来,瞪眼、挑眉、嘟嘴,不管多么夸张的表情,都模仿的非常到位。加大难度,让眉毛挑的再高些,眼睛睁的再大些,甚至连嘴型都是歪的,虚拟人物头像也能完美复现表情。当你在左侧调整参数时,右侧的虚拟头像也会相应地改变动作给嘴巴、眼睛一个特写,模仿的不能说完全相同,只能说表情一模一样(最右边)。这项研究来自慕尼黑工业大学等机构,他们提出了GaussianAvatars,这种
 牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
写在前面项目链接:https://nianticlabs.github.io/mickey/给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对
 你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》杂志曾经写过一篇文章,说“编程到1960年就会消失”,因为IBM开发了一种新语言FORTRAN,这种新语言可以让工程师写出他们所需的数学公式,然后提交给计算机运行,所以编程就会终结。图片又过了几年,我们听到了一种新说法:任何业务人员都可以使用业务术语来描述自己的问题,告诉计算机要做什么,使用这种叫做COBOL的编程语言,公司不再需要程序员了。后来,据说IBM开发出了一门名为RPG的新编程语言,可以让员工填写表格并生成报告,因此大部分企业的编程需求都可以通过它来完成图
 《原神》:知名原神3d同人作者被捕
Feb 15, 2024 am 09:51 AM
《原神》:知名原神3d同人作者被捕
Feb 15, 2024 am 09:51 AM
一些原神“奇怪”的关键词,在这两天很有关注度,明明搜索指数没啥变化,却不断有热议话题蹦窜。例如了龙王、钟离等“转变”立绘激增,虽在网络上疯传了一阵子,但是经过追溯发现这些是合理、常规的二创同人。如果单是这些,倒也翻不起多大的热度。按照一部分网友的说法,除了原神自身就有热度外,发现了一件格外醒目的事情:原神3d同人作者shirakami已经被捕。这引发了不小的热议。为什么被捕?关键词,原神3D动画。还是越过了线(就是你想的那种),再多就不能明说了。经过多方求证,以及新闻报道,确实有此事。自从去年发
 MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
本文经自动驾驶之心公众号授权转载,转载请联系出处。原标题:MotionLM:Multi-AgentMotionForecastingasLanguageModeling论文链接:https://arxiv.org/pdf/2309.16534.pdf作者单位:Waymo会议:ICCV2023论文思路:对于自动驾驶车辆安全规划来说,可靠地预测道路代理未来行为是至关重要的。本研究将连续轨迹表示为离散运动令牌序列,并将多智能体运动预测视为语言建模任务。我们提出的模型MotionLM具有以下几个优点:首
