

无障碍出行更安全!字节跳动研究成果获CVPR2022 AVA竞赛冠军

近日,CVPR2022各项竞赛结果陆续公布, 字节跳动智能创作AI平台「Byte-IC-AutoML」团队在基于合成数据的实例分割挑战赛( Accessibility Vision and Autonomy Challenge ,下文简称AVA) 中,凭借自研的 Parallel Pre-trained Transformers (PPT) 框架脱颖而出,成为该比赛唯一赛道的冠军。
论文地址:https://www.php.cn/link/ede529dfcbb2907e9760eea0875cdd12
本届AVA竞赛由波士顿大学(Boston University)和卡耐基梅隆大学(Carnegie Mellon University)联合举办。
竞赛通过渲染引擎得到一个合成的实例分割数据集,其中包含与残疾行人交互的自治系统的数据样例。竞赛目标是为无障碍相关人与物提供目标检测和实例分割的基准和方法。

数据集可视化
竞赛难点分析
- 领域泛化问题:本次比赛数据集均为渲染引擎合成的图像, 数据 domain 和自然图像存在显著差异;
- 长尾/少样本问题:数据存在长尾分布, 如 "拐杖" 和 "轮椅" 类别在数据集中更少, 分割效果也更差;
- 分割鲁棒性问题:些类别的分割效果非常差, 实例分割 mAP 比目标检测分割 mAP 低 30
技术方案详解
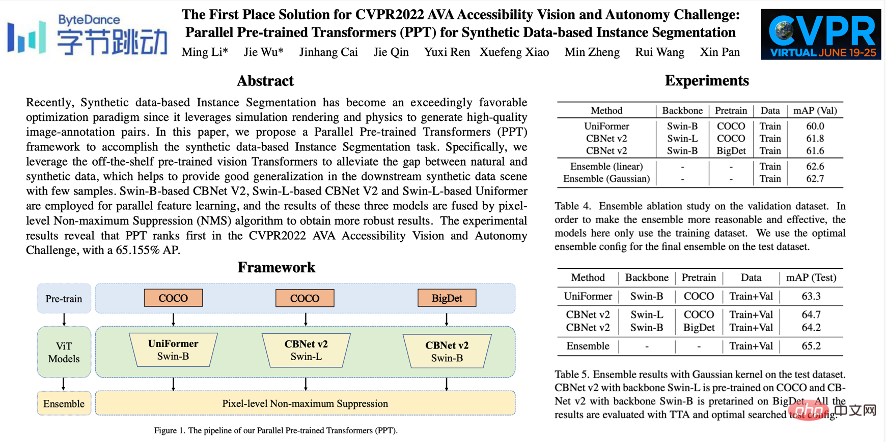
Byte-IC-AutoML团队提出了一个Parallel Pre-trained Transformers (PPT)框架来完成。框架主要由三个模块组成:1)并行的大规模预训练的Transformers;2)Balance Copy-Paste 数据增强;3)像素级别的非极大值抑制和模型融合;
并行大规模预训练Transformers
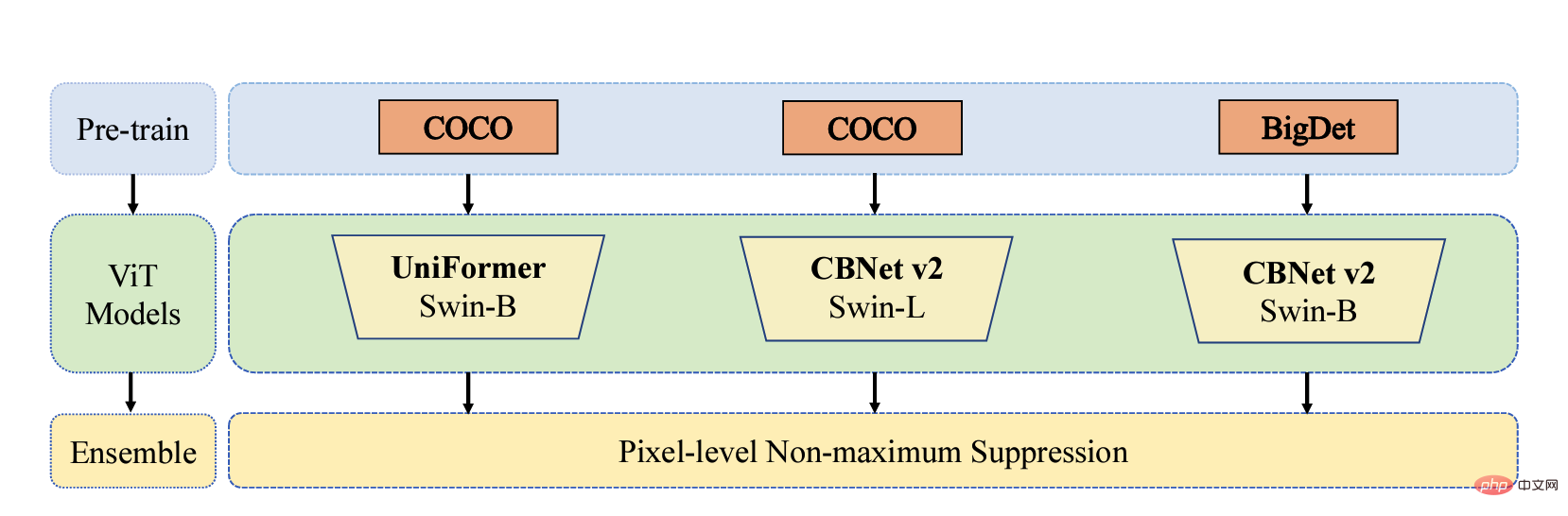
最近很多的预训练文章表明,大规模数据集预训练的模型可以很好地泛化到不同的下游场景中。因此,团队使用 COCO 和BigDetection 数据集先对模型进行预训练,这可以较大程度地缓解自然数据和合成数据之间的领域偏差,以便可以在下游的合成数据场景中用较少的样本快速训练。在模型层面, 考虑到 Vision Transformers 没有 CNN 的归纳偏置, 更能享受预训练带来的好处,团队使用 UniFormer 和CBNetV2。UniFormer 统一了 convolution 和 self-attention,同时解决 local redundancy 和 global dependency 两大问题,实现高效的特征学习。CBNetV2 架构串接多个相同的主干分组,这些主干通过复合连接来构建高性能检测器。模型的主干特征提取器都是 Swin Transformer。多个大规模预训练的 Transformers 通过并行的方式排列,输出的结果进行集成学习输出最终的结果。
不同方法在验证数据集上的mAP
Balance Copy-Paste 数据增强
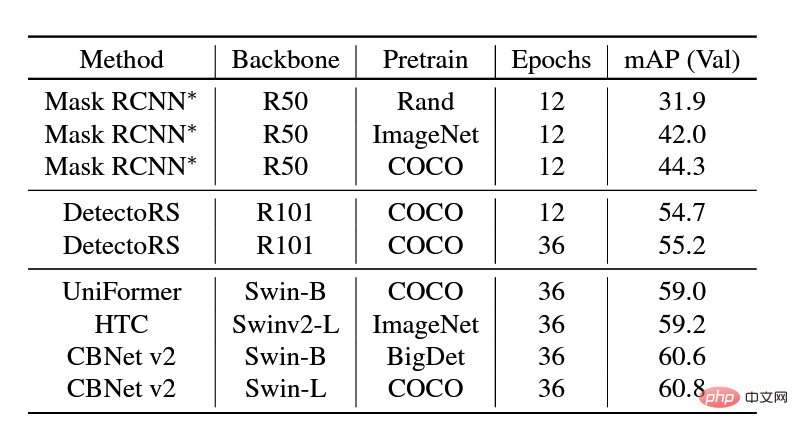
Copy-Paste技术通过随机粘贴对象为实例分割模型提供了令人印象深刻的结果,尤其是对于长尾分布下的数据集。然而,这种方法均衡地增加了所有类别的样本,并没能从根本上缓解类别分布的长尾问题。因此,团队提出了Balance Copy-Paste 数据增强方法。Balance Copy-Paste 根据类别的有效数量自适应地对类别进行采样,提高了整体的样本质量,缓解了样本数少和长尾分布的问题, 最终大幅提升了模型在实例分割上的 mAP。
Balance Copy-Paste数据增强技术带来的提升
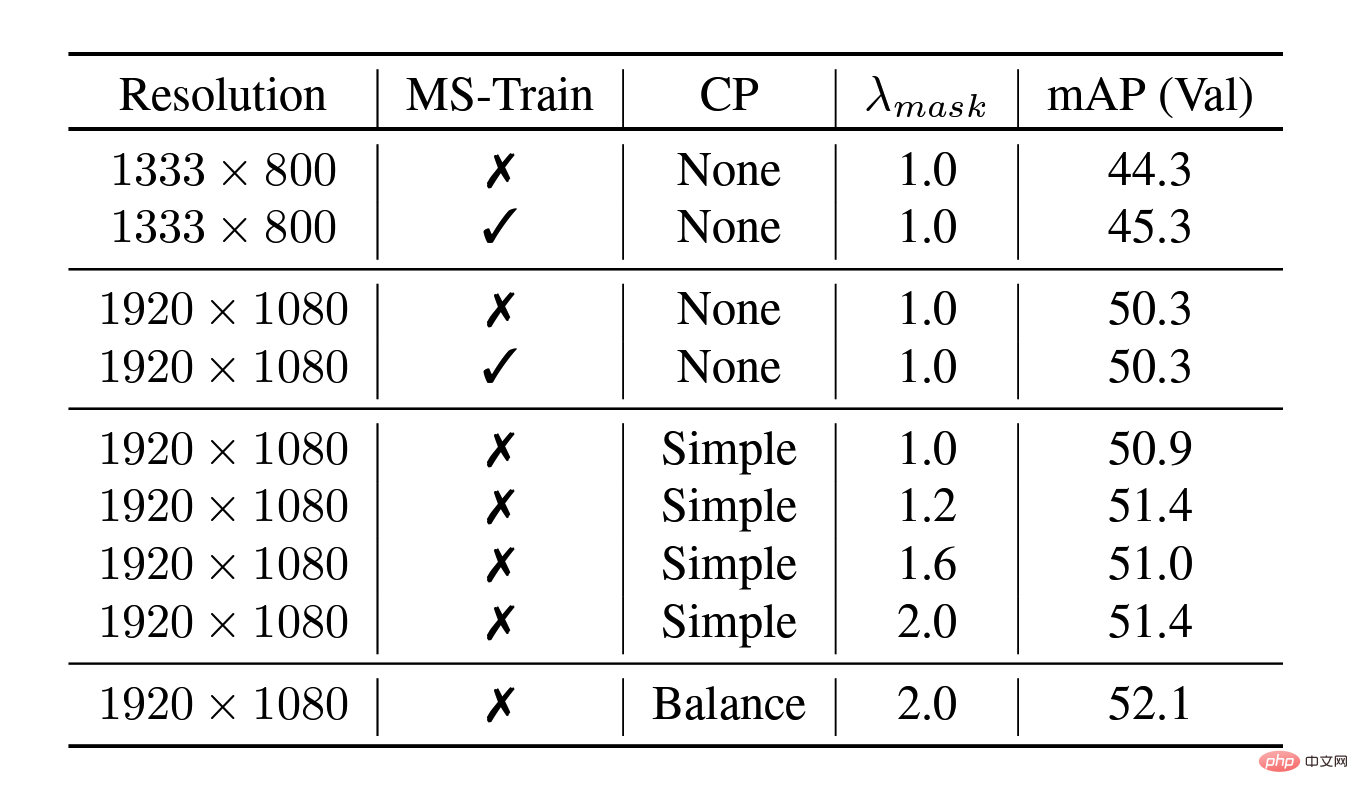
像素级别的非极大值抑制和模型融合
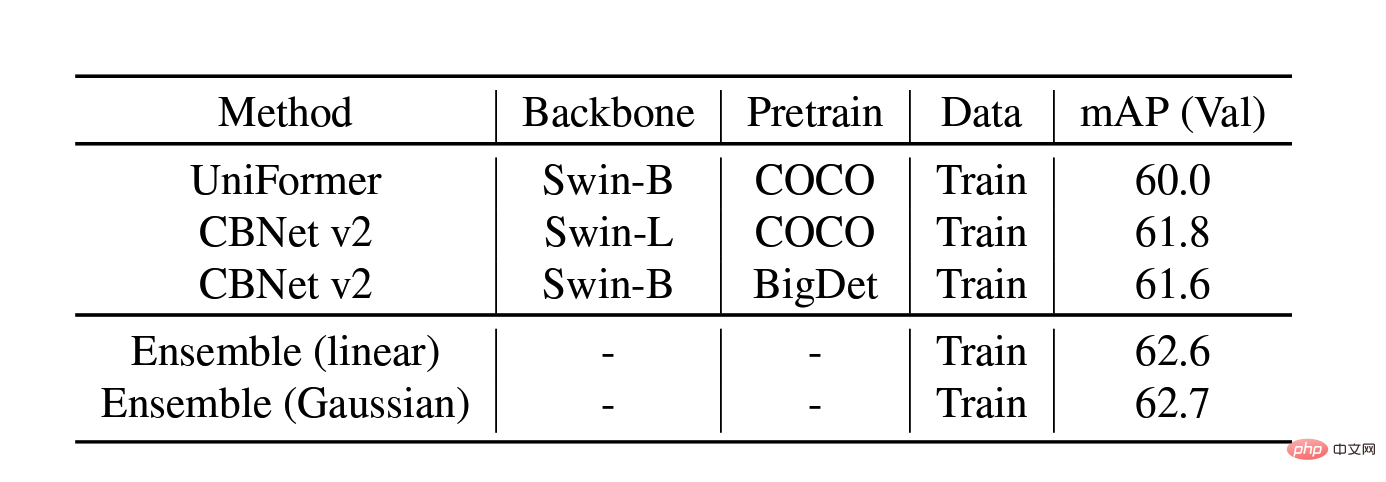
验证集上的模型融合消融实验
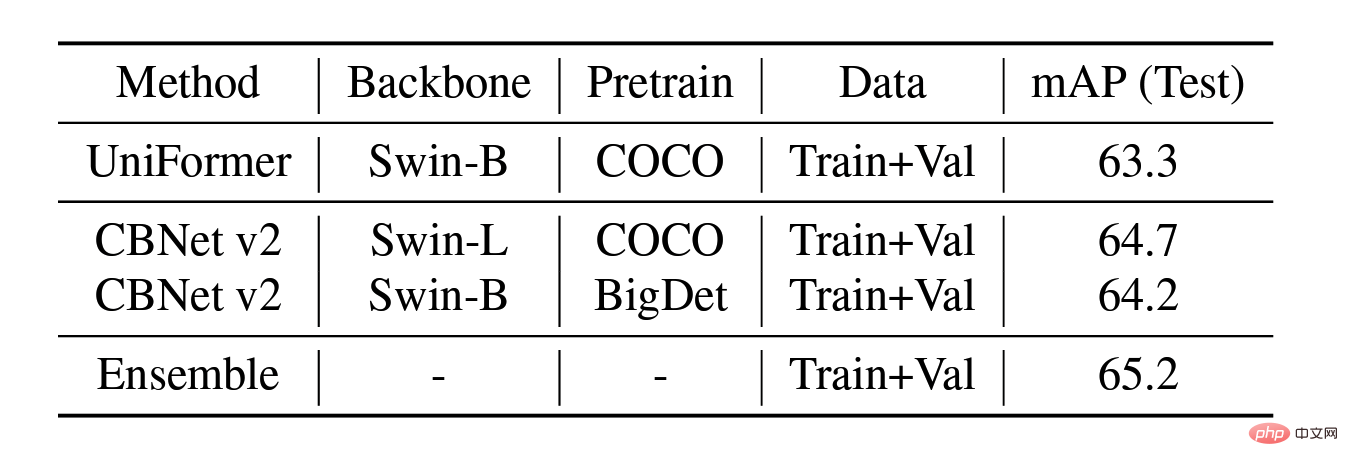
测试集上的模型融合消融实验
目前,城市和交通数据集更多的是通用场景, 只包含正常的交通工具和行人,数据集中缺乏关于残疾人及行动不便的人, 以及其辅助设备的类别,利用当前已有数据集得到的检测模型无法检测出这些人与物体。
字节跳动Byte-IC-AutoML团队的这项技术方案,对目前自动驾驶和街道场景理解有广泛应用:经过这些合成数据得到的模型可以识别出“轮椅”,“在轮椅上的人”,“拄拐杖的人”等少见的类别,不但能更加精细地对人群/物体进行划分, 而且不会错判误判导致场景理解错误。此外, 通过这种合成数据的方式, 可以构造出真实世界中比较少见类别的数据, 从而训练更加通用, 更加完善的目标检测模型。
智能创作是字节跳动的多媒体创新科技研究所和综合型服务商。覆盖了计算机视觉、图形学、语音、拍摄编辑、特效、客户端、AI平台、服务端工程等技术领域,在部门内部实现了前沿算法-工程系统-产品全链路的闭环,旨在以多种形式向公司内部各业务线以及外部合作客户提供业界最前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。团队技术能力正通过火山引擎对外开放。
火山引擎是字节跳动旗下的云服务平台,将字节跳动快速发展过程中积累的增长方法、技术能力和工具开放给外部企业,提供云基础、视频与内容分发、大数据、人工智能、开发与运维等服务,帮助企业在数字化升级中实现持续增长。
以上是无障碍出行更安全!字节跳动研究成果获CVPR2022 AVA竞赛冠军的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
火山引擎总裁谭待企业要做好大模型落地,面临模型效果、推理成本、落地难度的三大关键挑战:既要有好的基础大模型做支撑,解决复杂难题,也要有低成本的推理服务让大模型被广泛应用,还要更多工具、平台和应用帮助企业做好场景落地。——谭待火山引擎总裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最关键的挑战。谭待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均处理1,200亿tokens文本、生成3,000万张图片。为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山
 营销效果大幅提升,AIGC视频创作就该这么用
Jun 25, 2024 am 12:01 AM
营销效果大幅提升,AIGC视频创作就该这么用
Jun 25, 2024 am 12:01 AM
经过一年多的发展,AIGC已经从文字对话、图片生成逐步向视频生成迈进。回想四个月前,Sora的诞生让视频生成赛道经历了一场洗牌,大力推动了AIGC在视频创作领域的应用范围和深度。在人人都在谈论大模型的时代,我们一方面惊讶于视频生成带来的视觉震撼,另一方面又面临着落地难问题。诚然,大模型从技术研发到应用实践还处于一个磨合期,仍需结合实际业务场景进行调优,但理想与现实的距离正在被逐步缩小。营销作为人工智能技术的重要落地场景,成为了很多企业及从业者想要突破的方向。掌握了恰当方法,营销视频的创作过程就会
 如何探索和可视化用于图像中物体检测的 ML 数据
Feb 16, 2024 am 11:33 AM
如何探索和可视化用于图像中物体检测的 ML 数据
Feb 16, 2024 am 11:33 AM
近年来,人们对深入理解机器学习数据(ML-data)的重要性有了更深刻的认识。然而,由于检测大型数据集通常需要大量的人力和物力投入,因此在计算机视觉领域的广泛应用仍然需要进一步的开发。通常,在物体检测(ObjectDetection,属于计算机视觉的一个子集)中,通过定义边界框,来定位图像中的物体,不仅可以识别物体,还能够了解物体的上下文、大小、以及与场景中其他元素的关系。同时,针对类的分布、物体大小的多样性、以及类出现的常见环境进行全面了解,也有助于在评估和调试中发现训练模型中的错误模式,从而
 火山语音TTS技术实力获国检中心认证 MOS评分高达4.64
Apr 12, 2023 am 10:40 AM
火山语音TTS技术实力获国检中心认证 MOS评分高达4.64
Apr 12, 2023 am 10:40 AM
日前,火山引擎语音合成产品获得国家语音及图像识别产品质量检验检测中心(以下简称“AI国检中心”)颁发的语音合成增强级检验检测证书,在语音合成的基本要求以及扩展要求上已达AI国检中心的最高等级标准。本次评测从中文普通话、多方言、多语种、混合语种、多音色、个性化等维度进行评测,产品的技术支持团队-火山语音团队提供了丰富的音库,经评测其音色MOS评分最高可达4.64分,处行业领先水平。作为我国质检系统在人工智能领域的首家、也是唯一的国家级语音及图像产品质量检验检测机构,AI 国检中心一直致力于推动智能
 Python中的深度学习预训练模型详解
Jun 11, 2023 am 08:12 AM
Python中的深度学习预训练模型详解
Jun 11, 2023 am 08:12 AM
随着人工智能和深度学习的发展,预训练模型已经成为了自然语言处理(NLP)、计算机视觉(CV)、语音识别等领域的热门技术。Python作为目前最流行的编程语言之一,自然也在预训练模型的应用中扮演了重要角色。本文将重点介绍Python中的深度学习预训练模型,包括其定义、种类、应用以及如何使用预训练模型。什么是预训练模型?深度学习模型的主要难点在于对大量高质量
 主打个性化体验,留住用户全靠AIGC?
Jul 15, 2024 pm 06:48 PM
主打个性化体验,留住用户全靠AIGC?
Jul 15, 2024 pm 06:48 PM
1.购买商品前,消费者会在社交媒体上搜索并浏览商品评价。因此,企业在社交平台上针对产品进行营销变得越来越重要。营销的目的是为了:促进产品的销售树立品牌形象提高品牌认知度吸引并留住客户最终提高企业的盈利能力大模型具备出色的理解和生成能力,可以通过浏览和分析用户数据为用户提供个性化内容推荐。《AIGC体验派》第四期中,两位嘉宾将深入探讨AIGC技术在提升「营销转化率」方面发挥的作用。直播时间:7月10日19:00-19:45直播主题:留住用户,AIGC如何通过个性化提升转化率?第四期节目邀请到两位重
 深探无监督预训练技术落地 火山语音“算法优化+工程革新”并举
Apr 08, 2023 pm 12:44 PM
深探无监督预训练技术落地 火山语音“算法优化+工程革新”并举
Apr 08, 2023 pm 12:44 PM
长期以来,火山引擎为时下风靡的视频平台提供基于语音识别技术的智能视频字幕解决方案。简单来说,就是通过AI技术自动将视频中的语音和歌词转化成文字,辅助视频创作的功能。但伴随平台用户的快速增长以及对语言种类更加丰富多样的要求,传统采用的有监督学习技术日渐触及瓶颈,这让团队着实犯了难。众所周知,传统的有监督学习会对人工标注的有监督数据产生严重依赖,尤其在大语种的持续优化以及小语种的冷启动方面。以中文普通话和英语这样的大语种为例,尽管视频平台提供了充足的业务场景语音数据,但有监督数据达到一定规模之后,继
 基于知识增强和预训练大模型的 Query 意图识别
May 19, 2023 pm 02:01 PM
基于知识增强和预训练大模型的 Query 意图识别
May 19, 2023 pm 02:01 PM
一、背景介绍企业数字化是近年来很热的一个话题,它是指运用人工智能、大数据、云计算等新一代数字技术,改变企业的业务模式,从而推动企业业务产生新的增长。企业数字化一般来说包括业务经营的数字化和企业管理的数字化。本次分享主要介绍企业管理层面的数字化。信息数字化,简单来说,就是把信息用数字化的方式进行读写、存储和传递。从以前的纸质文档到现在的电子文档以及在线协同文档,信息数字化已经变成了现在办公的新常态。目前阿里使用钉钉文档和语雀文档进行业务协同,在线文档数量已经达到了2000万以上。另外很多企业内部会
