

VectorFlow:结合图像和向量做交通占用和流预测

arXiv论文“VectorFlow: Combining Images and Vectors for Traffic Occupancy and Flow Prediction“,2022年8月9日,清华大学工作。

预测道路智体的未来行为是自主驾驶中的一项关键任务。虽然现有模型在预测智体未来行为方面取得了巨大成功,但有效预测多智体联合一致的行为仍然是一个挑战。最近,有人提出了occupancy flow fields(OFF)表示法,通过占用网格和流的组合来表示道路智体的联合未来状态,支持联合一致的预测。
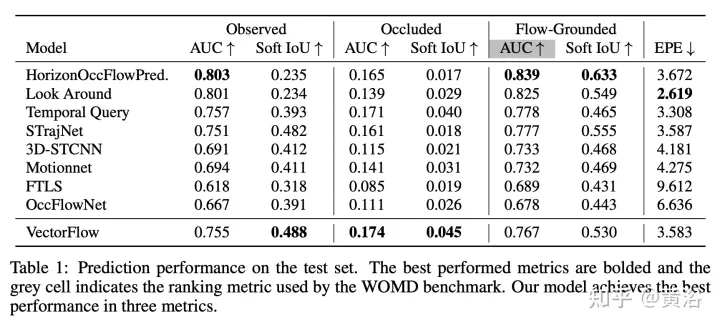
这项工作提出一种新的occupancy flow fields预测器,从光栅化交通图像中学习特征的图像编码器,和捕获连续智体轨迹和地图状态信息的向量编码器,二者结合起来,生成准确的占用和流预测。在生成最终预测之前,两个编码特征由多个注意模块融合。该模型在Waymo开放数据集占用和流预测挑战(Occupancy and Flow Prediction Challenge)中排名第三,在遮挡占用率和预测任务(occluded occupancy and flow prediction task)中实现了最佳性能。
OFF表示(“Occupancy Flow Fields for Motion Forecasting in Autonomous Driving“,arXiv 2203.03875,3,2022)是一种时空网格,其中每个网格单元包括 i)任何智体占用单元的概率 和 ii)表示占用该单元智体运动的流。其提供了更好的效率和可扩展性,因为预测occupancy flow fields的计算复杂性与场景中道路智体的数量无关。
如图是OFF框架图。编码器结构如下。第一级接收所有三种类型的输入点,并用PointPillars启发的编码器进行处理。交通灯和道路点直接放置在网格中。智体在每个输入时间步t的状态编码是,从每个智体BEV框内均匀采样固定大小的点网格,并把这些点与相关智体状态属性(包括时间t的one-hot编码)放置在网格。每个pillar为其包含的所有点输出一个嵌入。解码器结构如下。第二级接收每个pillar嵌入作为输入,并生成每个网格单元占用和流预测。解码器网络基于EfficientNet,用EfficientNet作为主干来处理每个pillar嵌入得到特征映射(P2,…P7),其中Pi从输入中下采样2^i。然后用BiFPN网络以双向方式融合这些多尺度特征。然后,用最高分辨率特征映射P2在所有时间步回归所有智体类K的占用和流预测。具体地,解码器为每个网格单元输出一个向量,同时预测占用和流。
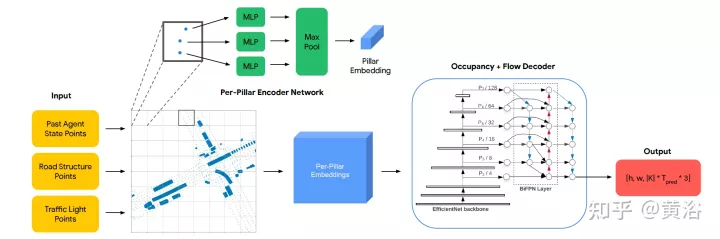
针对本文,做以下问题设置:给定场景中交通智体1秒的历史和场景上下文,如地图坐标,目标是预测 i)未来观察到的占用率,ii)未来遮挡的占用率,以及 iii)在一个场景中未来8个路点上所有车辆的未来流,其中每个路点覆盖1秒的间隔。
将输入处理为光栅化图像和一组向量。为了获得图像,在给定观察智体轨迹和地图数据的情况下,相对于自动驾驶汽车(SDC)的局部坐标,在过去的每个时间步创建一个光栅化网格。为了获得与光栅化图像一致的向量化输入,遵循相同的变换,相对于SDC的局部视图,旋转和移动输入智体和地图坐标。
编码器包括两部分:编码光栅化表示的VGG-16模型,和编码向量化表示的VectorNe模型。通过交叉注意模块将向量化特征与VGG-16最后两步的特征进行融合。通过FPN-式样网络,融合后的特征上采样到原始分辨率,作为输入的光栅化特征。
解码器是单个2D卷积层,将编码器输出映射到occupancy flow fields预测,该预测包括一系列8网格图,表示未来8秒内每个时间步的占用和流预测。
如图所示:
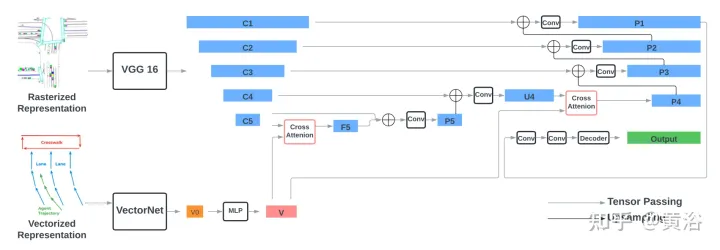
用torchvision的标准VGG-16模型,作为光栅化编码器,并遵循VectorNet(代码https://github.com/Tsinghua-MARS-Lab/DenseTNT)的实现。VectorNet的输入包括 i)一组形状为B×Nr×9的道路元素向量,其中B是批处理大小,Nr=10000是道路元素向量的最大数,最后一个维度9表示每个向量和向量ID中两个端点的位置(x,y)和方向(cosθ,sinθ);ii)一组形状为B×1280×9的智体向量,包括场景中最多128个智体的向量,其中每个智体具有来自观察位置的10个向量。
遵循VectorNet,首先根据每个交通元素的ID运行局部图,然后在所有局部特征上运行全局图,获得形状为B×128×N的向量化特征,其中N是交通元素的总数,包括道路元素和智体。通过MLP层将特征的大小进一步增加四倍,获得最终的向量化特征V,其形状为B×512×N,其特征大小与图像特征的通道大小一致。
VGG每个级的输出特征表示为{C1、C2、C3、C4、C5},相对于输入图像和512隐藏维,跨步长(strides)为{1、2、4、8、16}像素。通过交叉注意模块将向量化特征V与形状为B×512×16×16的光栅化图像特征C5融合,获得相同形状的F5。交叉注意的query项是图像特征C5,扁平为有256个令牌(tokens)的B×512×256形状,Key和Value项是具有N个令牌的向量化特征V。
然后在通道维上连接F5和C5,通过两个3×3卷积层,获得形状为B×512×16×16的P5。P5通过FPN风格的2×2上采样模块做上采样并与C4(B×512×32x32)连接,生成和C4一样形状的U4。之后在V和U4之间执行另一轮融合,遵循相同的程序,包括交叉注意,获得P4(B×512×32×32)。最后,P4由FPN式样网络逐渐上采样,并与{C3,C2,C1}连接,生成形状为B×512×256×256的EP1。将P1通过两个3×3 卷积层,获得形状为B×128×256的最终输出特征。
解码器是单个2D卷积层,输入通道大小为128,输出通道大小为32(8个路点×4个输出维度)。
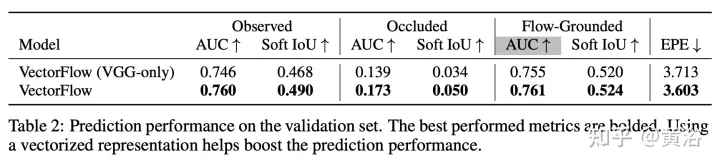
结果如下:
以上是VectorFlow:结合图像和向量做交通占用和流预测的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
智能应用控制是Windows11中非常有用的工具,可帮助保护你的电脑免受可能损害数据的未经授权的应用(如勒索软件或间谍软件)的侵害。本文将解释什么是智能应用控制、它是如何工作的,以及如何在Windows11中打开或关闭它。什么是Windows11中的智能应用控制?智能应用控制(SAC)是Windows1122H2更新中引入的一项新安全功能。它与MicrosoftDefender或第三方防病毒软件一起运行,以阻止可能不必要的应用,这些应用可能会减慢设备速度、显示意外广告或执行其他意外操作。智能应用
 五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
如此强大的AI模仿能力,真的防不住,完全防不住。现在AI的发展已经达到了这种程度吗?你前脚让自己的五官乱飞,后脚,一模一样的表情就被复现出来,瞪眼、挑眉、嘟嘴,不管多么夸张的表情,都模仿的非常到位。加大难度,让眉毛挑的再高些,眼睛睁的再大些,甚至连嘴型都是歪的,虚拟人物头像也能完美复现表情。当你在左侧调整参数时,右侧的虚拟头像也会相应地改变动作给嘴巴、眼睛一个特写,模仿的不能说完全相同,只能说表情一模一样(最右边)。这项研究来自慕尼黑工业大学等机构,他们提出了GaussianAvatars,这种
 MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
本文经自动驾驶之心公众号授权转载,转载请联系出处。原标题:MotionLM:Multi-AgentMotionForecastingasLanguageModeling论文链接:https://arxiv.org/pdf/2309.16534.pdf作者单位:Waymo会议:ICCV2023论文思路:对于自动驾驶车辆安全规划来说,可靠地预测道路代理未来行为是至关重要的。本研究将连续轨迹表示为离散运动令牌序列,并将多智能体运动预测视为语言建模任务。我们提出的模型MotionLM具有以下几个优点:首
 GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
身高1.65米,体重55公斤,全身44个自由度,能够快速行走、敏捷避障、稳健上下坡、抗冲击干扰的人形机器人,现在可以带回家了!傅利叶智能的通用人形机器人GR-1已开启预售机器人大讲堂傅利叶智能FourierGR-1通用人形机器人现已开放预售。GR-1拥有高度仿生的躯干构型和拟人化的运动控制,全身44个自由度,具备行走、避障、越障、上下坡、抗干扰、适应不同路面等运动能力,是通用人工智能的理想载体。官网预售页面:www.fftai.cn/order#FourierGR-1#傅利叶智能需要进行改写的内
 你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》杂志曾经写过一篇文章,说“编程到1960年就会消失”,因为IBM开发了一种新语言FORTRAN,这种新语言可以让工程师写出他们所需的数学公式,然后提交给计算机运行,所以编程就会终结。图片又过了几年,我们听到了一种新说法:任何业务人员都可以使用业务术语来描述自己的问题,告诉计算机要做什么,使用这种叫做COBOL的编程语言,公司不再需要程序员了。后来,据说IBM开发出了一门名为RPG的新编程语言,可以让员工填写表格并生成报告,因此大部分企业的编程需求都可以通过它来完成图
 行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!
Oct 17, 2023 am 11:13 AM
行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!
Oct 17, 2023 am 11:13 AM
轨迹预测近两年风头正猛,但大都聚焦于车辆轨迹预测方向,自动驾驶之心今天就为大家分享顶会NeurIPS上关于行人轨迹预测的算法—SHENet,在受限场景中人类的移动模式通常在一定程度上符合有限的规律。基于这个假设,SHENet通过学习隐含的场景规律来预测一个人的未来轨迹。文章已经授权自动驾驶之心原创!笔者的个人理解由于人类运动的随机性和主观性,当前预测一个人的未来轨迹仍然是一个具有挑战性的问题。然而,由于场景限制(例如平面图、道路和障碍物)以及人与人或人与物体的交互性,在受限场景中人类的移动模式通
 华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
近日,华为宣布将于9月推出一款搭载玄玑感知系统的全新智能穿戴新品,预计为华为的最新智能手表。该新品将集成先进的情绪健康监测功能,玄玑感知系统以其六大特性——准确性、全面性、快速性、灵活性、开放性和延展性——为用户提供全方位的健康评估。系统采用超感知模组,优化了多通道光路架构技术,大幅提升了心率、血氧和呼吸率等基础指标的监测精度。此外,玄玑感知系统还拓展了基于心率数据的情绪状态研究,不仅限于生理指标,还能评估用户的情绪状态和压力水平,支持超过60项运动健康指标监测,涵盖心血管、呼吸、神经、内分泌、
 一文读懂智能汽车滑板底盘
May 24, 2023 pm 12:01 PM
一文读懂智能汽车滑板底盘
May 24, 2023 pm 12:01 PM
01什么是滑板底盘所谓滑板式底盘,即将电池、电动传动系统、悬架、刹车等部件提前整合在底盘上,实现车身和底盘的分离,设计解耦。基于这类平台,车企可以大幅降低前期研发和测试成本,同时快速响应市场需求打造不同的车型。尤其是无人驾驶时代,车内的布局不再是以驾驶为中心,而是会注重空间属性,有了滑板式底盘,可以为上部车舱的开发提供更多的可能。如上图,当然我们看滑板底盘,不要上来就被「噢,就是非承载车身啊」的第一印象框住。当年没有电动车,所以没有几百公斤的电池包,没有能取消转向柱的线传转向系统,没有线传制动系
