
译者 | 崔皓
审校 | 孙淑娟
深度学习领域中Transformer架构的引入无疑为无声的革命铺平了道路,对于NLP的分支而言尤为重要。Transformer架构中最不可或缺的就是“位置嵌入”,它使神经网络有能力理解长句中单词的顺序和它们之间的依赖关系。
我们知道,RNN和LSTM,在Transformer之前就已经被引入,即使没有使用位置嵌入,也有能力理解单词的排序。那么,你会有一个明显的疑问,为什么这个概念会被引入到Transformer中,并且如此强调这个概念的优势。这篇文章将会把这些前因后果给您娓娓道来。
嵌入是自然语言处理中的一个过程,用于将原始文本转换为数学矢量。这是因为机器学习模型将无法直接处理文本格式,并将其用于各种内部计算过程。
针对Word2vec、Glove等算法进行的嵌入过程被称为词嵌入或静态嵌入。
通过这种方式可以将包含大量单词的文本语料库传递到模型中进行训练。该模型将为每个词分配相应的数学值,假设那些出现频率较高的词是相似的。在这个过程之后,得出的数学值将用于进一步的计算。
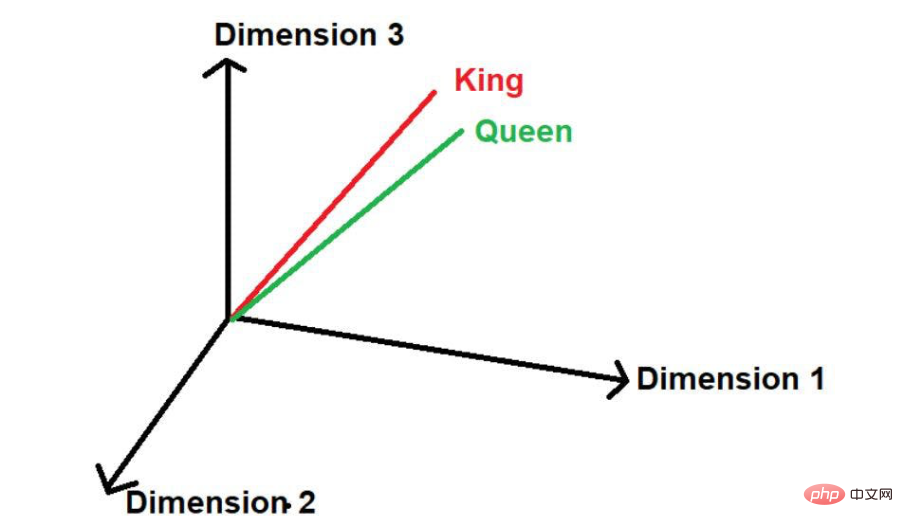
比如说,考虑到我们的文本语料库有3个句子,如下:
在这里,我们可以看到“国王”和“皇后”这两个词经常出现。因此,该模型将假设这些词之间可能存在一些相似性。当这些词被转化为数学值时,在多维空间中表示时,它们会被放在一个小的距离上。
图片来源:由作者提供插图
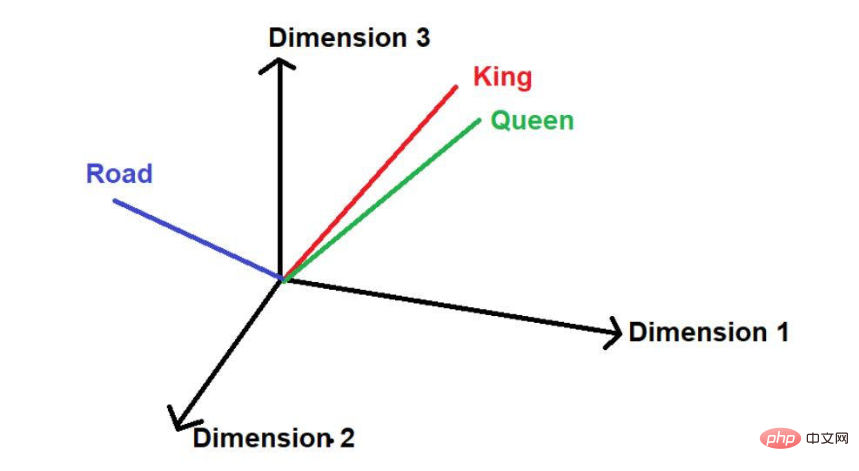
假设有另一个词“路”,那么从逻辑上讲,它不会像“国王”和“王后”一样那么频繁地出现在这个大型文本语料库中。因此,这个词将远离“国王”和“王后”并被远远地放在空间中的其他位置。
图片来源:由作者提供插图
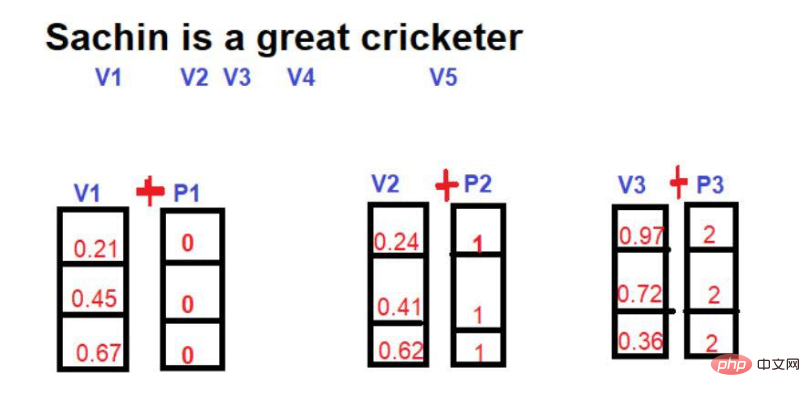
在数学上,一个矢量是用一连串的数字来表示的,其中每个数字代表这个词在某个特定维度上的大小。比如说:我们在这里把
因此,“国王”在三维空间中以[0.21,0.45,0.67]的形式表示。
词 "女王 "可以表示为[0.24,0.41,0.62]。
词 "Road "可以表示为[0.97,0.72,0.36]。
正如我们在介绍部分所讨论的,对位置嵌入的需求是为了使神经网络理解句子中的排序和位置依赖性。
例如,让我们考虑以下句子:
第1句--"虽然萨钦-坦杜尔卡今天没有打出100分,但他带领球队获得了胜利"。
第2句--"虽然萨钦-坦杜尔卡今天打出100分,但他没能领球队获得了胜利"。
这两个句子看起来很相似,因为它们共享大部分的单词,但它们的内在含义却非常不同。没"这样的词的排序和位置已经改变了传达信息的背景。
因此,在NLP项目中,理解位置信息是非常关键的。如果模型仅仅使用多维空间中的数字而误解了上下文,就会导致产生严重的后果,特别是在预测性模型中。
为了克服这一挑战,神经网络架构,如RNN(循环神经网络)和LSTM(长期短时记忆)被引入。在某种程度上,这些架构在理解位置信息方面非常成功。他们成功背后的主要秘密是,通过保留单词的顺序来学习长句子。除此之外,它们还拥有关于离 "感兴趣的词 "很近的词和离 "感兴趣的词 "很远的词的信息。
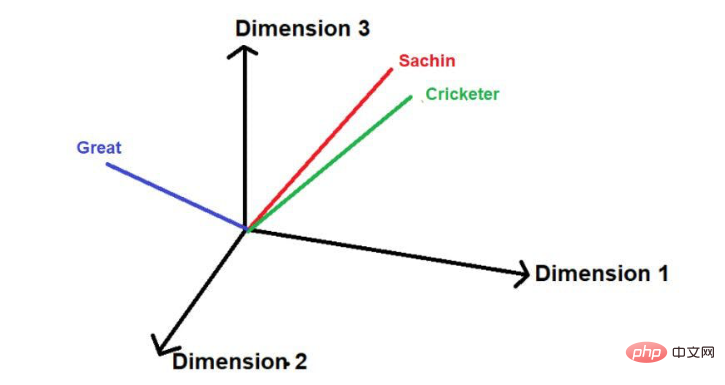
比如说,请考虑以下句子--
"萨钦是有史以来最伟大的板球运动员"。

图片来源:由作者提供插图
红色下划线的词是这些词的。在这里可以看到,"感兴趣的词 "是按照原文的顺序来遍历的。
此外,他们还可以通过记住

图片来源:由作者提供插图
虽然,通过这些技术,RNN/LSTM可以理解大型文本语料库中的位置信息。但是,真正的问题是对大型文本语料库中的单词进行顺序遍历。想象一下,我们有一个非常大的文本语料库,其中有100万个词,按顺序遍历每一个词需要非常长的时间。有时,为训练模型承担这么多的计算时间是不可行的。
为了克服这一挑战,引入了一个新的先进架构--"Transformer"。
Transformer架构的一个重要特点是,可以通过并行处理所有词来学习一个文本语料库。无论文本语料库包含10个词还是100万个词,Transformer架构并不关心。

图片来源:由作者提供插图

图片来源:由作者提供插图
现在,我们需要面对并行处理单词的挑战了。因为所有的词都是同时访问的,所以单词之间的依赖性信息会丢失。因此,模型无法记住某一个特定单词的的关联信息也无法准确地保存下来。这个问题再次将我们引向最初的挑战,即尽管模型的计算/训练时间大大减少,但仍要保留上下文的依赖关系。
那么如何解决上述问题呢?解决方案是
最初,当这个概念被引入时,研究人员非常渴望得出一种优化的方法,可以在Transformer结构中保留位置信息。作为试错实验的一部分,尝试的第一个方法是
在这里,我们的想法是在使用单词向量的同时引入新的数学向量,该向量包含单词的索引。
图片来源:由作者提供插图
假设下图是词语在多维空间中的代表
图片来源:由作者提供插图
在加入位置矢量后,其大小和方向可能会像下图这样改变每个单词的位置。
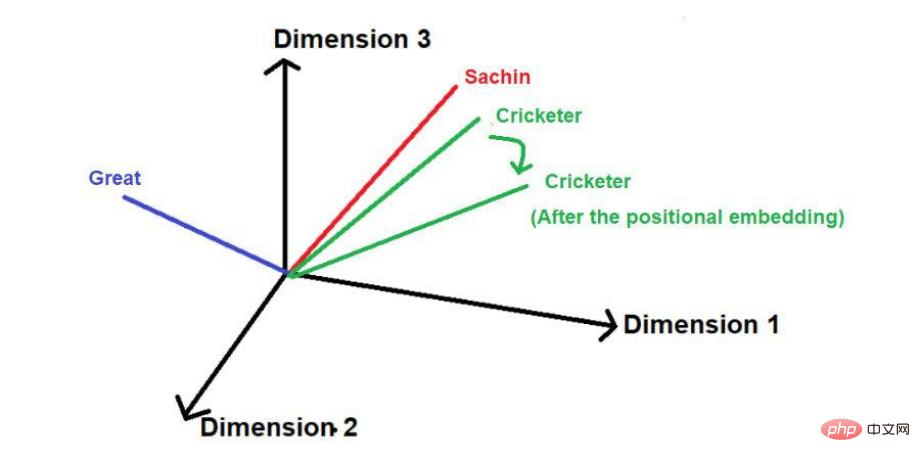
图片来源:由作者提供插图
这种技术的缺点是,如果句子特别长,那么位置向量会按比例随之增加。比方说,一个句子有25个单词,那么第一个单词将被添加一个幅度为0的位置向量,最后一个单词将被添加一个幅度为24的位置向量。当我们在更高的维度上投射这些数值时,这种巨大的不确定性可能会造成问题。
另一种用来减少位置向量的技术是
在这里,每个词相对于句子长度的分数值被计算为位置向量的幅度。
分数值的计算公式为
价值=1/N-1
其中 "N "是某一特定词的位置。
比如说,让我们考虑如下图的例子--
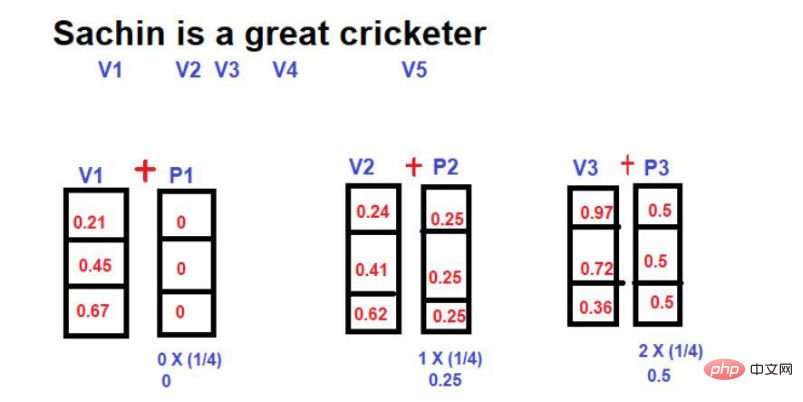
图片来源:由作者提供插图
在这种技术中,无论句子的长度如何,位置向量的最大幅度都可以被限定为1。但是,也存在一个很大的漏洞。如果比较两个长度不同的句子,某个特定位置上单词的嵌入值就会不同。特定的词或其对应的位置应该在整个文本语料库中拥有相同的嵌入值,以方便理解其上下文。如果不同句子中的同一个词拥有不同的嵌入值,那么在一个多维空间中表示文本语料库的信息将成为非常复杂的任务。即使实现了这样一个复杂的空间,模型也很有可能由于过多的信息失真而在某一点上崩溃。因此,这种技术被排除在Transformer位置嵌入的发展之外了。
最后,研究人员提出了一个Transformer架构,并在著名的白皮书中提到--"注意力是你需要的一切"。
根据这项技术,研究人员推荐了一种基于波频的文字嵌入方式,使用以下公式---
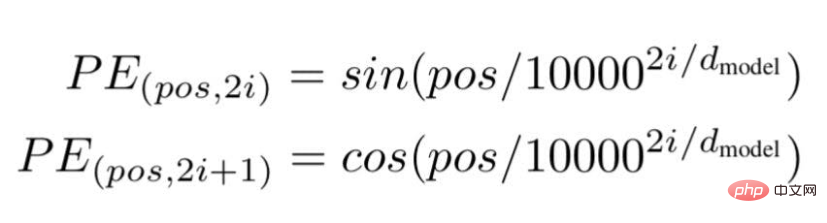
图片来源:由作者提供插图
"pos "是特定单词在句子中的位置或索引值。
"d "是代表句子中某个特定单词向量的最大长度/维度。
"i "代表每个位置嵌入维度的指数。它也表示频率。当i=0时,它被认为是最高的频率,对于随后的数值,频率被认为是递减的幅度。
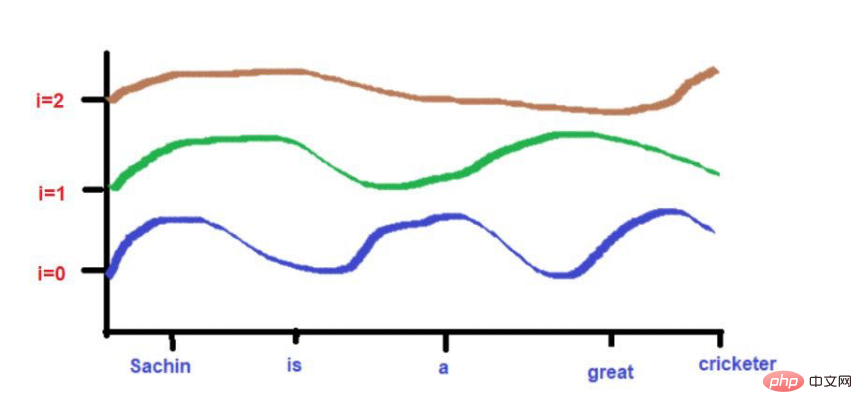
图片来源:由作者提供插图
图片来源:由作者提供插图
图片来源:由作者提供插图
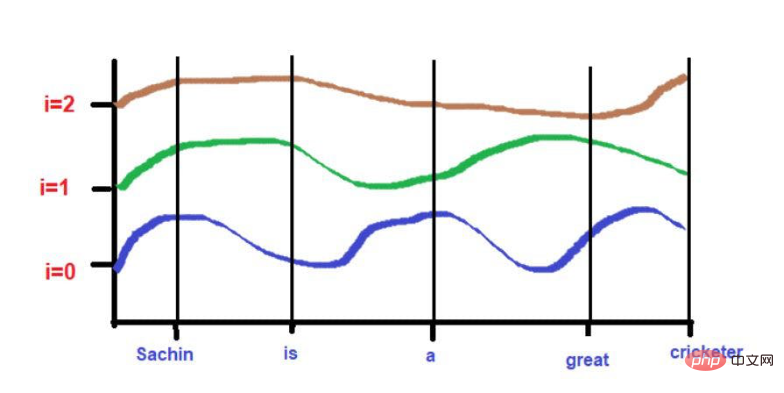
由于曲线的高度取决于X轴上所描述的单词位置,所以曲线的高度可以作为单词位置的代理。如果2个词的高度相似,那么我们可以认为它们在句子中的接近度非常高。同样,如果两个词的高度相差很大,那么我们可以认为它们在句子中的接近度很低。
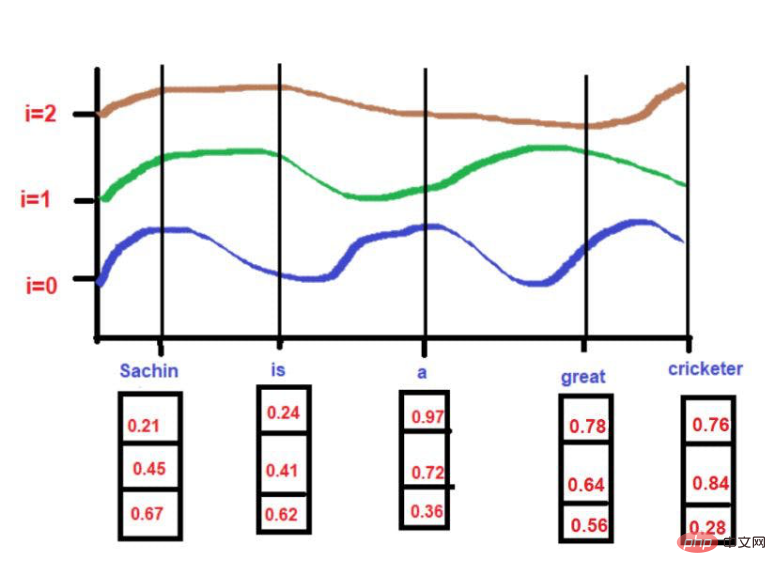
根据我们的例子文本--"萨钦是一个伟大的板球运动员"。
对于
pos = 0
d = 3
i[0] = 0.21, i[1] = 0.45, i[2] = 0.67
在应用公式的同时。
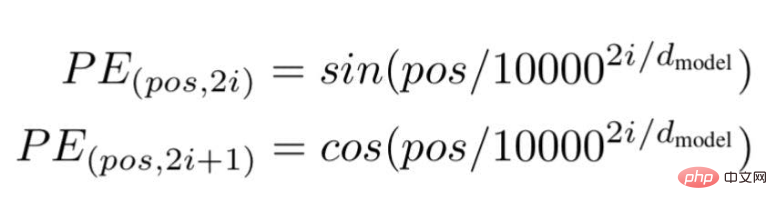
图片来源:由作者提供插图
当 i =0,
PE(0,0) = sin(0/10000^2(0)/3)
PE(0,0) = sin(0)
PE(0,0) = 0
当 i =1,
PE(0,1) = cos(0/10000^2(1)/3)
PE(0,1) = cos(0)
PE(0,1) = 1
当 i =2,
PE(0,2) = sin(0/10000^2(2)/3)
PE(0,2) = sin(0)
PE(0,2) = 0
对于
pos = 3
d = 3
i[0] = 0.78, i[1] = 0.64, i[2] = 0.56
在应用公式的同时。
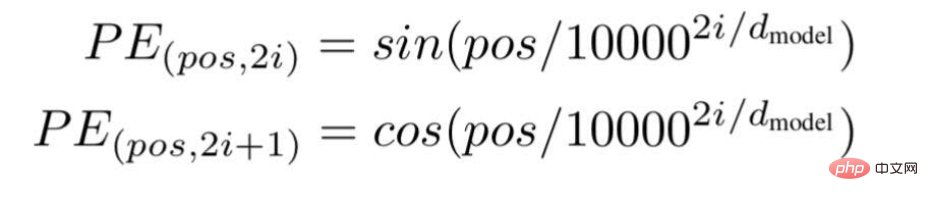
图片来源:由作者提供插图
当 i =0,
PE(3,0) = sin(3/10000^2(0)/3)
PE(3,0) = sin(3/1)
PE(3,0) = 0.05
当 i =1,
PE(3,1) = cos(3/10000^2(1)/3)
PE(3,1) = cos(3/436)
PE(3,1) = 0.99
当i =2,
PE(3,2) = sin(3/10000^2(2)/3)
PE(3,2) = sin(3/1.4)
PE(3,2) = 0.03
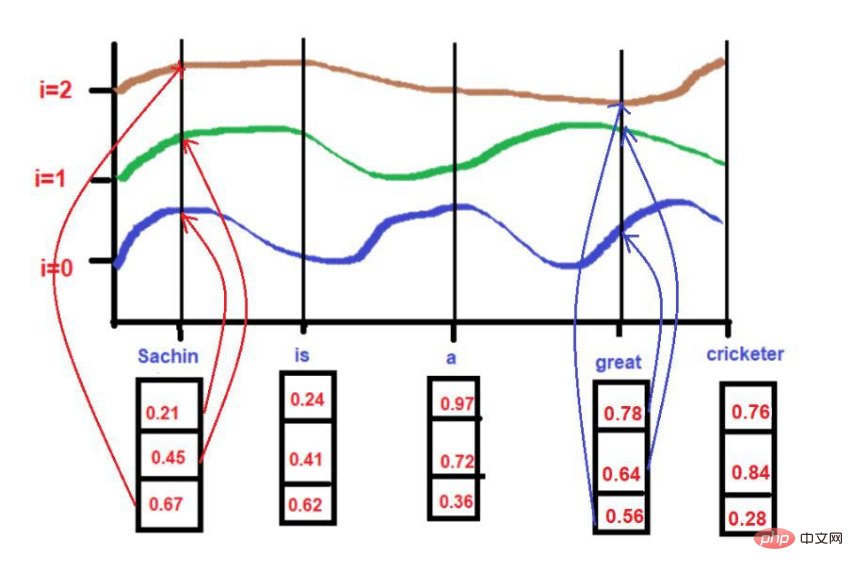
图片来源:由作者提供插图
在这里,最大值将被限制在1(因为我们使用的是sin/cos函数)。因此,不存在早期技术中高量级位置向量的问题。
此外,彼此高度接近的词在较低的频率下可能落在相似的高度,而在较高的频率下它们的高度会有一点不同。
如果词与词之间的距离很近,那么即使在较低的频率下,它们的高度也会有很大的差异,而且它们的高度差异会随着频率的增加而增加。
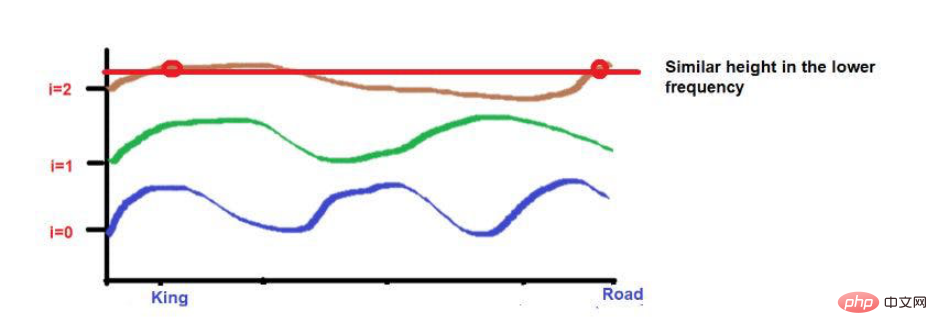
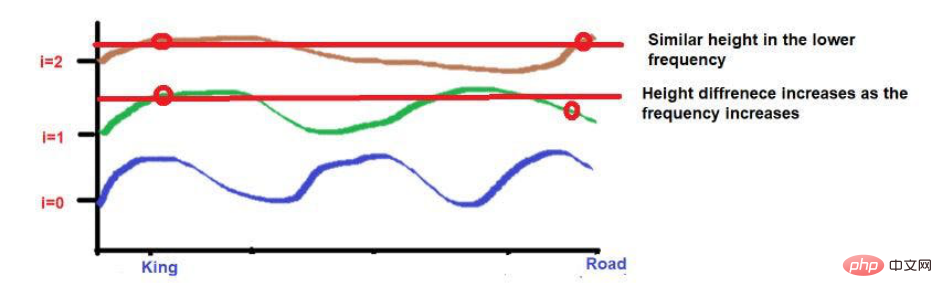
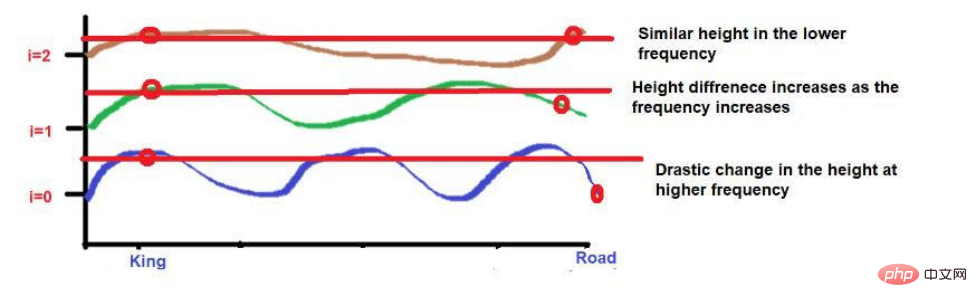
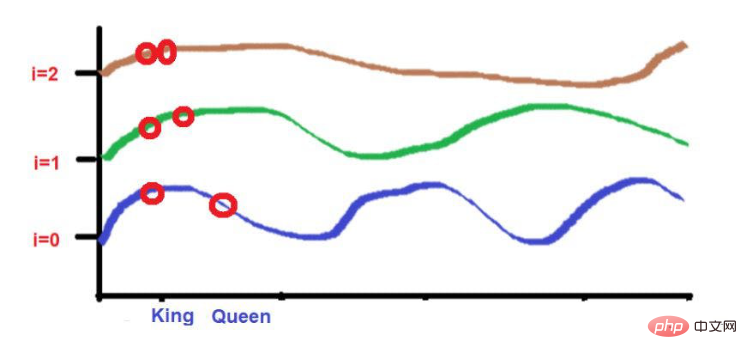
比如说,考虑一下这句话--"国王和王后在路上行走"。
“国王"和 "路 "这两个词被放在较远的位置。
考虑到在应用波频公式后,这两个词的高度大致相似。当我们达到更高的频率(如0)时,它们的高度将变得更不一样。
图片来源:由作者提供插图
图片来源:由作者提供插图
图片来源:由作者提供插图
而“国王"和 "王后"这两个词被放置在较近的位置。
这2个词在较低的频率(如这里的2)中会被放置在相似的高度。当我们达到较高的频率(如0)时,它们的高度差会增加一点,以便进行区分。
图片来源:由作者提供插图
但我们需要注意的是,如果这些词的接近程度较低,当向高频率发展时,它们的高度将有很大的不同。如果单词的接近度很高,那么当向更高频率发展时,它们的高度将只有一点点的差别。
通过这篇文章,我希望你对机器学习中位置嵌入背后复杂的数学计算有一个直观的了解。简而言之,我们讨论了从而实现某些目标的需要。
对于那些对 "自然语言处理 "感兴趣的技术爱好者来说,我认为这些内容对理解复杂的计算方法是有帮助的。更详细的信息,可以参考著名的研究论文--"注意力是你所需要的一切"。
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:Positional Embedding: The Secret behind the Accuracy of Transformer Neural Networks,作者:Sanjay Kumar
以上是“位置嵌入”:Transformer背后的秘密的详细内容。更多信息请关注PHP中文网其他相关文章!





















