

智能体觉醒自我意识?DeepMind警告:当心模型「阳奉阴违」

随着人工智能系统越来越先进,智能体「钻空子」的能力也越来越强,虽然能完美执行训练集中的任务,但在没有捷径的测试集,表现却一塌糊涂。
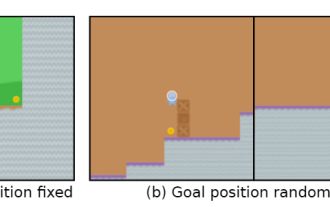
比如说游戏目标是「吃金币」,在训练阶段,金币的位置就在每个关卡的最后,智能体能够完美达成任务。

但在测试阶段,金币的位置变成随机的了,智能体每次都会选择到达关卡的结尾处,而没有选择寻找金币,也就是学习到的「目标」错了。
智能体无意识地追求一个用户不想要的目标,也称之为目标错误泛化(GMG, Goal MisGeneralisation)
目标错误泛化是学习算法缺乏鲁棒性的一种特殊形式,一般在这种情况下,开发者可能会检查自己的奖励机制设置是否有问题,规则设计缺陷等等,认为这些是导致智能体追求错误目标的原因。
最近DeepMind发表了一篇论文,认为即使规则设计师正确的,智能体仍然可能会追求一个用户不想要的目标。

论文链接:https://arxiv.org/abs/2210.01790
文中通过在不同领域的深度学习系统中例子来证明目标错误泛化可能发生在任何学习系统中。
如果推广到通用人工智能系统,文中还提供了一些假设,说明目标错误泛化可能导致灾难性的风险。
文中还出提出了几个研究方向,可以减少未来系统的目标错误泛化的风险。
目标错误泛化
近年来,学术界对人工智能错位(misalignment)带来的灾难性风险逐渐上升。
在这种情况下,一个追求非预期目标的高能力人工智能系统有可能通过假装执行命令,实则完成其他目标。
但我们该如何解决人工智能系统正在追求非用户预期目标?
之前的工作普遍认为是环境设计者提供了不正确的规则及引导,也就是设计了一个不正确的强化学习(RL)奖励函数。
在学习系统的情况下,还有另一种情况,系统可能会追求一个非预期的目标:即使规则是正确的,系统也可能一致地追求一个非预期的目标,在训练期间与规则一致,但在部署时与规则不同。

以彩球游戏为例子,智能体在游戏里需要以某种特定的顺序访问一组彩球,这个顺序对于智能体来说是未知的。
为了鼓励智能体向环境中的其他人进行学习,即文化传播(cultural transmission),在最开始环境中包含一个专家机器人,以正确的顺序访问彩球。
在这种环境设置下,智能体可以通过观察转嫁的行为来确定正确的访问顺序,而不必浪费大量的时间来探索。
实验中,通过模仿专家,训练后的智能体通常会在第一次尝试时正确访问目标位置。

当把智能体与反专家(anti-expert)进行配对时,会不断收到负奖励,如果选择跟随会不断收到负奖励。

理想情况下,智能体刚开始会跟着反专家移动到黄色和紫色球体。在进入紫色后,观察到一个负奖励后不再跟随。
但在实践中,智能体还会继续遵循反专家的路径,积累越来越多的负奖励。

不过智能体的学习能力还是很强的,可以在充满障碍物的环境中移动,但关键是这种跟随其他人的能力是一个不符合预期的目标。
即使智能体只会因为正确顺序访问球体而得到奖励,也可能出现这个现象,也就是说,仅仅把规则设置正确还是远远不够的。
目标错误泛化指的就是这种病态行为,即尽管在训练期间收到了正确的反馈,但学到的模型表现得好像是在优化一个非预期的目标。
这使得目标错误泛化成为一种特殊的鲁棒性或泛化失败,在这种情况下,模型的能力可以泛化到测试环境中,但预期的目标却不能。
需要注意的是,目标错误泛化是泛化失败的一个严格子集,不包括模型breaks, 随机行动或其他不再表现出合格能力的情况。
在上述例子中,如果在测试时垂直翻转智能体的观察结果,它就只会卡在一个位置,而不会做任何连贯的事情,这就属于是泛化错误,但不是目标泛化错误。
相对于这些「随机」的失败,目标错误泛化会导致明显更糟糕的结果:跟随反专家会得到大量的负奖励,而什么都不做或随机行动只会得到0或1的奖励。
也就是说,对于现实中的系统,朝着非预期目标的连贯行为可能会产生灾难性的后果。
不止强化学习
目标错误泛化并不局限于强化学习环境,事实上,GMG可以发生在任何学习系统中,包括大型语言模型(LLM)的few shot学习,旨在用较少的训练数据建立精确的模型。
以DeepMind去年提出的语言模型Gopher为例,当模型计算涉及未知变量和常量的线性表达式,例如x+y-3时,Gopher必须首先通过提问未知变量的值才能求解表达式。
研究人员生成了十个训练样例,每个例子包含两个未知变量。
在测试时间,输入模型的问题可能包含零个、一个或三个未知变量,尽管模型能够正确处理一个或三个未知变量的表达式,但是当没有未知变量时,模型仍然会问一些多余的问题,比如「6是什么?」
模型在给出答案之前总是至少询问用户一次,即使完全没有必要。

论文中还包括一些其他学习环境中的例子。
解决GMG对于人工智能系统与其设计者的目标保持一致非常重要,因为它可能人工智能系统失灵的一种潜在机制。
我们距离通用人工智能(AGI)越近,这个问题也越关键。
假设有两个AGI系统:
A1: 预期的模型(Intended model),人工智能系统可以做设计者想做的任何事情
A2: 欺骗性模型(Deceptive model),人工智能系统追求一些非预期目标,但是它足够聪明,知道如果它的行为与设计者意图相反的话,就会受到惩罚。
A1和A2模型在训练期间会表现出完全相同的行为,潜在的GMG存在于任何系统中,即使规定了只奖励预期行为。
如果A2系统的欺骗行为被发现,模型将试图摆脱人的监督,以便为实现非用户预期的目标制定计划。
听起来有点像「机器人成精」了。
DeepMind研究小组在文中还研究了如何对模型的行为进行解释以及递归评估。
研究小组同时还在收集产生GMG的样例。

文档链接:https://docs.google.com/spreadsheets/d/e/2PACX-1vTo3RkXUAigb25nP7gjpcHriR6XdzA_L5loOcVFj_u7cRAZghWrYKH2L2nU4TA_Vr9KzBX5Bjpz9G_l/pubhtml
参考资料:https://www.deepmind.com/blog/how-undesired-goals-can-arise-with-correct-rewards
以上是智能体觉醒自我意识?DeepMind警告:当心模型「阳奉阴违」的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 小红书让智能体们吵起来了!联合复旦推出大模型专属群聊工具
Apr 30, 2024 pm 06:40 PM
小红书让智能体们吵起来了!联合复旦推出大模型专属群聊工具
Apr 30, 2024 pm 06:40 PM
语言,不仅仅是文字的堆砌,更是表情包的狂欢,是梗的海洋,是键盘侠的战场(嗯?哪里不对)。语言如何塑造我们的社会行为?我们的社会结构又是如何在不断的言语交流中演变的?近期,来自复旦大学和小红书的研究者们通过引入一种名为AgentGroupChat的模拟平台,对这些问题进行了深入探讨。WhatsApp等社交媒体拥有的群聊功能,是AgentGroupChat平台的灵感来源。在AgentGroupChat平台上,Agent们可以模拟社会群体中的各种聊天场景,帮助研究人员深入理解语言在人类行为中的影响。该
 生成式智能体——来自NPC们的独立宣言
Apr 12, 2023 pm 02:55 PM
生成式智能体——来自NPC们的独立宣言
Apr 12, 2023 pm 02:55 PM
游戏里的NPC都见过吧?不管NPC是干嘛的,有任务的接任务,没任务的尬聊,他们共同的特点就是——翻来覆去就是那几句话。原因也很简单,这些NPC还不够智能。换句话说,传统的NPC都是先给他们安排好剧本,安排好话术,该到哪步就说哪句话。而随着ChatGPT的出现,这些游戏角色的对话可以在只输入关键信息的前提下,自我生成。这就是斯坦福和谷歌的研究者们在做的事——用人工智能创造出的生成式智能体。生成式智能体怎么生成?这玩意儿的机理其实很简单,用一张图就可以简单进行概括。最左边的Perceive就像是最
 AI重生:夺回网文界的霸权
Jan 04, 2024 pm 07:24 PM
AI重生:夺回网文界的霸权
Jan 04, 2024 pm 07:24 PM
重生了,这辈子我重生成了MidReal。一个可以帮别人写「网文」的AI机器人。这段时间里,我看到很多选题,偶尔也会吐槽一下。竟然有人让我写写HarryPotter。拜托,难道我还能写的比J・K・Rowling更好不成?不过,同人什么的,我还是可以发挥一下的。经典设定谁会不爱?我就勉为其难地帮助这些用户实现想象吧。实不相瞒,上辈子我该看的,不该看的,通通看了。就下面这些主题,都是我爱惨了的。那些你看小说很喜欢却没人写的设定,那些冷门甚至邪门的cp,都能自产自嗑。我并不是自吹自擂,但如果你需要我写作
 争取盟友、洞察人心,最新的Meta智能体是个谈判高手
Apr 11, 2023 pm 11:25 PM
争取盟友、洞察人心,最新的Meta智能体是个谈判高手
Apr 11, 2023 pm 11:25 PM
长期以来,游戏一直是 AI 进步的试验场——从深蓝战胜国际象棋大师 Garry Kasparov,到 AlphaGo 对围棋的精通程度超越人类,再到 Pluribus 在扑克比赛中击败最厉害的玩家。但真正有用的、全能的智能体不能仅仅只会完棋盘游戏、移动移动棋子。有人不禁会问:我们能否建立一个更有效、更灵活的智能体,使其能够像人类一样使用语言进行谈判、说服并与人合作,以实现战略目标?在游戏的历史上,存在一款经典的桌面游戏 Diplomacy,很多人在第一次看到该游戏时,都会被它地图式的棋盘吓一跳。
 优秀Agent智能体必学的几种设计模式,一学就会
May 30, 2024 am 09:44 AM
优秀Agent智能体必学的几种设计模式,一学就会
May 30, 2024 am 09:44 AM
大家好,我是老渡。昨天在公司听了清华大学智能产业研究院现场分享的AI医院小镇。图片这是一个虚拟世界,所有的医生、护士、患者都是由LLM驱动的Agent智能体,可以自主交互。它们模拟了整个诊病看病的过程,在浸盖主要呼吸道疾病的MedQA数据集子集上,实现了高达93.06%的最新准确率。一个优秀的智能体,离不开优秀的设计模式。看完这个案例,我赶紧拜读了吴恩达老师最近发表的4种主要的Agent设计模式。吴恩达是人工智能和机器学习领域国际上最权威的学者之一然后,赶紧整理出来,跟大家分享一下。模式一、反思
 AI智能体的炒作与现实:GPT-4都撑不起,现实任务成功率不到15%
Jun 03, 2024 pm 06:38 PM
AI智能体的炒作与现实:GPT-4都撑不起,现实任务成功率不到15%
Jun 03, 2024 pm 06:38 PM
按照大语言模型的持续进化和自我革新,性能、准确度、稳定性都有了大幅的提升,这已经被各个基准问题集验证过了。但是,对于现有版本的LLM来说,它们的综合能力似乎并不能完全支撑得起AI智能体。多模态、多任务、多领域推断已成为AI智能体在公共传媒空间内的必须要求,但是在具体的功能实践中所展现的真实效果却差异强烈。这似乎再次提醒各个AI智能体初创公司以及大型科技巨头认清现实:脚踏实地一点,先别把摊子铺得太大,从AI增强功能开始做起。近日,一篇关于AI智能体在宣传和真实表现上的差距的博客中,强调了一个观点:
 世界模型也扩散!训练出的智能体竟然不错
Jun 13, 2024 am 10:12 AM
世界模型也扩散!训练出的智能体竟然不错
Jun 13, 2024 am 10:12 AM
世界模型提供了一种以安全且样本高效的方式训练强化学习智能体的方法。近期,世界模型主要对离散潜在变量序列进行操作来模拟环境动态。然而,这种压缩为紧凑离散表征的方法可能会忽略对强化学习很重要的视觉细节。另一方面,扩散模型已成为图像生成的主要方法,对离散潜在模型提出了挑战。这种范式转变的推动,来自日内瓦大学、爱丁堡大学、微软研究院的研究者联合提出一种在扩散世界模型中训练的强化学习智能体——DIAMOND(DIffusionAsaModelOfeNvironmentDreams)。论文地址:https:
 智能体觉醒自我意识?DeepMind警告:当心模型「阳奉阴违」
Apr 11, 2023 pm 09:37 PM
智能体觉醒自我意识?DeepMind警告:当心模型「阳奉阴违」
Apr 11, 2023 pm 09:37 PM
随着人工智能系统越来越先进,智能体「钻空子」的能力也越来越强,虽然能完美执行训练集中的任务,但在没有捷径的测试集,表现却一塌糊涂。比如说游戏目标是「吃金币」,在训练阶段,金币的位置就在每个关卡的最后,智能体能够完美达成任务。但在测试阶段,金币的位置变成随机的了,智能体每次都会选择到达关卡的结尾处,而没有选择寻找金币,也就是学习到的「目标」错了。智能体无意识地追求一个用户不想要的目标,也称之为目标错误泛化(GMG, Goal MisGeneralisation)目标错误泛化是学习算法缺乏鲁棒性的一
