
CLIP(Contrastive Language-Image Pre-training)是一种机器学习技术,它可以准确理解和分类图像和自然语言文本,这对图像和语言处理具有深远的影响,并且已经被用作流行的扩散模型DALL-E的底层机制。在这篇文章中,我们将介绍如何调整CLIP来辅助视频搜索。
这篇文章将不深入研究CLIP模型的技术细节,而是展示CLIP的另外一个实际应用(除了扩散模型外)。
首先我们要知道:CLIP使用图像解码器和文本编码器来预测数据集中哪些图像与哪些文本是匹配的。

通过使用来自hugging face的预训练CLIP模型,我们可以构建一个简单而强大的视频搜索引擎,并且具有自然语言能力,而且不需要进行特征工程的处理。
我们需要用到以下的软件
Python≥= 3.8,ffmpeg,opencv
通过文本搜索视频的技术有很多。我们可以将搜索引擎将由两部分组成,索引和搜索。
视频索引通常涉及人工和机器过程的结合。人类通过在标题、标签和描述中添加相关关键字来预处理视频,而自动化过程则是提取视觉和听觉特征,例如物体检测和音频转录。用户交互指标等等,这样可以记录视频的哪些部分是最相关的,以及它们保持相关性的时间。所有这些步骤都有助于创建视频内容的可搜索索引。
索引过程的概述如下
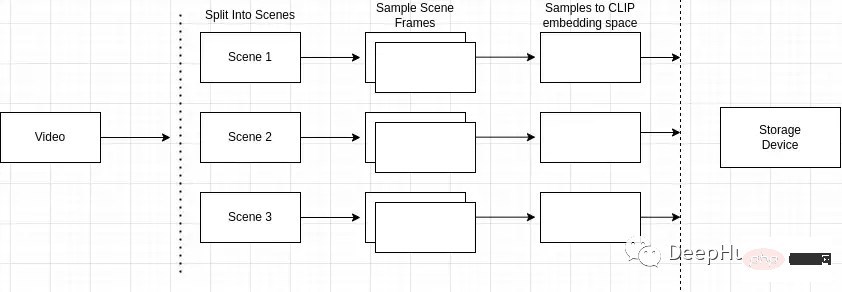
为什么场景检测很重要?视频由场景组成,而场景由相似的帧组成。如果我们只对视频中的任意场景进行采样,可能会错过整个视频中的关键帧。
所以我们就需要准确地识别和定位视频中的特定事件或动作。例如,如果我搜索“公园里的狗”,而我正在搜索的视频包含多个场景,例如一个男人骑自行车的场景和一个公园里的狗的场景,场景检测可以让我识别出与搜索查询最接近的场景。
可以使用“scene detect”python包来进行这个操作。
mport scenedetect as sd video_path = '' # path to video on machine video = sd.open_video(video_path) sm = sd.SceneManager() sm.add_detector(sd.ContentDetector(threshold=27.0)) sm.detect_scenes(video) scenes = sm.get_scene_list()
然后就需要使用cv2对视频进行帧采样。
import cv2 cap = cv2.VideoCapture(video_path) every_n = 2 # number of samples per scene scenes_frame_samples = [] for scene_idx in range(len(scenes)): scene_length = abs(scenes[scene_idx][0].frame_num - scenes[scene_idx][1].frame_num) every_n = round(scene_length/no_of_samples) local_samples = [(every_n * n) + scenes[scene_idx][0].frame_num for n in range(3)] scenes_frame_samples.append(local_samples)
在收集样本之后,我们需要将它们计算成CLIP模型可用的东西。
首先需要将每个样本转换为图像张量嵌入。
from transformers import CLIPProcessor
from PIL import Image
clip_processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
def clip_embeddings(image):
inputs = clip_processor(images=image, return_tensors="pt", padding=True)
input_tokens = {
k: v for k, v in inputs.items()
}
return input_tokens['pixel_values']
# ...
scene_clip_embeddings = [] # to hold the scene embeddings in the next step
for scene_idx in range(len(scenes_frame_samples)):
scene_samples = scenes_frame_samples[scene_idx]
pixel_tensors = [] # holds all of the clip embeddings for each of the samples
for frame_sample in scene_samples:
cap.set(1, frame_sample)
ret, frame = cap.read()
if not ret:
print('failed to read', ret, frame_sample, scene_idx, frame)
break
pil_image = Image.fromarray(frame)
clip_pixel_values = clip_embeddings(pil_image)
pixel_tensors.append(clip_pixel_values)下一步就是平均同一场景中的所有样本,这样可以降低样本的维数,而且还可以解决单个样本中存在噪声的问题。
import torch
import uuid
def save_tensor(t):
path = f'/tmp/{uuid.uuid4()}'
torch.save(t, path)
return path
# ..
avg_tensor = torch.mean(torch.stack(pixel_tensors), dim=0)
scene_clip_embeddings.append(save_tensor(avg_tensor))这样就获得了一个CLIP嵌入的表示视频内容的的张量列表。
对于底层索引存储,我们使用LevelDB(LevelDB是由谷歌维护的键/值库)。我们搜索引擎的架构将包括 3 个独立的索引:
我们将首先将视频中所有计算出的元数据以及视频的唯一标识符,插入到元数据索引中,这一步都是现成的,非常简单。
import leveldb
import uuid
def insert_video_metadata(videoID, data):
b = json.dumps(data)
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
video_id = str(uuid.uuid4())
insert_video_metadata(video_id, {
'VideoURI': video_path,
})然后在场景嵌入索引中创建一个新条目保存视频中的每个像素嵌入,还需要一个唯一的标识符来识别每个场景。
import leveldb
import uuid
def insert_scene_embeddings(sceneID, data):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
level_instance.Put(sceneID.encode('utf-8'), data)
# ...
for f in scene_clip_embeddings:
scene_id = str(uuid.uuid4())
with open(f, mode='rb') as file:
content = file.read()
insert_scene_embeddings(scene_id, content)最后,我们需要保存哪些场景属于哪个视频。
import leveldb
import uuid
def insert_video_scene(videoID, sceneIds):
b = ",".join(sceneIds)
level_instance = leveldb.LevelDB('./dbs/scene_index')
level_instance.Put(videoID.encode('utf-8'), b.encode('utf-8'))
# ...
scene_ids = []
for f in scene_clip_embeddings:
# .. as shown in previous step
scene_ids.append(scene_id)
scene_embedding_index.insert(scene_id, content)
scene_index.insert(video_id, scene_ids)现在我们有了一种将视频的索引,下面就可以根据模型输出对它们进行搜索和排序。
第一步需要遍历场景索引中的所有记录。然后,创建一个视频中所有视频和匹配场景id的列表。
records = []
level_instance = leveldb.LevelDB('./dbs/scene_index')
for k, v in level_instance.RangeIter():
record = (k.decode('utf-8'), str(v.decode('utf-8')).split(','))
records.append(record)下一步需要收集每个视频中存在的所有场景嵌入张量。
import leveldb
def get_tensor_by_scene_id(id):
level_instance = leveldb.LevelDB('./dbs/scene_embedding_index')
b = level_instance.Get(bytes(id,'utf-8'))
return BytesIO(b)
for r in records:
tensors = [get_tensor_by_scene_id(id) for id in r[1]]在我们有了组成视频的所有张量之后,我们可以把它传递到模型中。该模型的输入是“pixel_values”,表示视频场景的张量。
import torch
from transformers import CLIPProcessor, CLIPModel
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
inputs = processor(text=text, return_tensors="pt", padding=True)
for tensor in tensors:
image_tensor = torch.load(tensor)
inputs['pixel_values'] = image_tensor
outputs = model(**inputs)然后访问模型输出中的“logits_per_image”获得模型的输出。
Logits本质上是对网络的原始非标准化预测。由于我们只提供一个文本字符串和一个表示视频中的场景的张量,所以logit的结构将是一个单值预测。
logits_per_image = outputs.logits_per_image probs = logits_per_image.squeeze() prob_for_tensor = probs.item()
将每次迭代的概率相加,并在运算结束时将其除以张量的总数来获得视频的平均概率。
def clip_scenes_avg(tensors, text): avg_sum = 0.0 for tensor in tensors: # ... previous code snippets probs = probs.item() avg_sum += probs.item() return avg_sum / len(tensors)
最后在得到每个视频的概率并对概率进行排序后,返回请求的搜索结果数目。
import leveldb
import json
top_n = 1 # number of search results we want back
def video_metadata_by_id(id):
level_instance = leveldb.LevelDB('./dbs/videometadata_index')
b = level_instance.Get(bytes(id,'utf-8'))
return json.loads(b.decode('utf-8'))
results = []
for r in records:
# .. collect scene tensors
# r[0]: video id
return (clip_scenes_avg, r[0])
sorted = list(results)
sorted.sort(key=lambda x: x[0], reverse=True)
results = []
for s in sorted[:top_n]:
data = video_metadata_by_id(s[1])
results.append({
'video_id': s[1],
'score': s[0],
'video_uri': data['VideoURI']
})就是这样!现在就可以输入一些视频并测试搜索结果。
通过CLIP可以轻松地创建一个频搜索引擎。使用预训练的CLIP模型和谷歌的LevelDB,我们可以对视频进行索引和处理,并使用自然语言输入进行搜索。通过这个搜索引擎使用户可以轻松地找到相关的视频,最主要的是我们并不需要大量的预处理或特征工程。
那么我们还能有什么改进呢?
可以在这里找到本文的代码:https://github.com/GuyARoss/CLIP-video-search/tree/article-01。
以及这个修改版本:https://github.com/GuyARoss/CLIP-video-search。
以上是使用CLIP构建视频搜索引擎的详细内容。更多信息请关注PHP中文网其他相关文章!





















