

全身追踪、不怕遮挡,CMU两位华人做了个基于WiFi信号的DensePose

过去几年,在自动驾驶和 VR 等应用的推动下,使用 2D 和 3D 传感器(如 RGB 传感器、LiDARs 或雷达)进行人体姿态估计取得了很大进展。但是,这些传感器在技术上和实际使用中都存在一些限制。首先成本高,普通家庭或小企业往往承担不起 LiDAR 和雷达传感器的费用。其次,这些传感器对于日常和家用而言太过耗电。
至于 RGB 相机,狭窄的视野和恶劣的照明条件会对基于相机的方法造成严重影响。遮挡成为阻碍基于相机的模型在图像中生成合理姿态预测的另一个障碍。室内场景尤其难搞,家具通常会挡住人。更重要的是,隐私问题阻碍了在非公共场所使用这些技术,很多人不愿意在家中安装摄像头记录自己的行为。但在医疗领域,出于安全、健康等原因,很多老年人有时不得不在摄像头和其他传感器的帮助下进行实时监控。
近日,CMU 的三位研究者在论文《DensePose From WiFi》中提出,在某些情况下,WiFi 信号可以作为 RGB 图像的替代来进行人体感知。照明和遮挡对用于室内监控的 WiFi 解决方案影响不大。WiFi 信号有助于保护个人隐私,所需的相关设备也能以合理的价格买到。关键的一点是,很多家庭都安装了 WiFi,因此这项技术有可能扩展到监控老年人的健康状况或者识别家中的可疑行为。
论文地址:https://arxiv.org/pdf/2301.00250.pdf
研究者想要解决的问题如下图 1 第一行所示。给定 3 个 WiFi 发射器和 3 个对应的接收器,能否在多人的杂乱环境中检测和复原密集人体姿态对应关系(图 1 第四行)?需要注意的是,很多 WiFi 路由器(如 TP-Link AC1750)都有 3 根天线,因此本文方法中只需要 2 个这样的路由器。每个路由器的价格大约是 30 美元,意味着整个设置依然比 LiDAR 和雷达系统便宜得多。
为了实现如图 1 第四行的效果,研究者从计算机视觉的深度学习架构中获得灵感,提出了一种可以基于 WiFi 执行密集姿态估计的神经网络架构,并实现了在有遮挡和多人的场景中仅利用 WiFi 信号来估计密集姿态。

下图左为基于图像的 DensePose,图右为基于 WiFi 的 DensePose。

图源:推特 @AiBreakfast
另外,值得一提的是,论文一二作均为华人。论文一作 Jiaqi Geng 在去年 8 月取得了 CMU 机器人专业硕士学位,二作 Dong Huang 现为 CMU 高级项目科学家。
方法介绍
想要利用 WiFi 生成人体表面的 UV 坐标需要三个组件:首先通过振幅和相位步骤对原始 CSI( Channel-state-information,表示发射信号波与接收信号波之间的比值 )信号进行清理处理;然后,将处理过的 CSI 样本通过双分支编码器 - 解码器网络转换为 2D 特征图;接着将 2D 特征图馈送到一个叫做 DensePose-RCNN 架构中(主要是把 2D 图像转换为 3D 人体模型),以估计 UV 图。
原始 CSI 样本带有噪声(见图 3 (b)),不仅如此,大多数基于 WiFi 的解决方案都忽略了 CSI 信号相位,而专注于信号的幅度(见图 3 (a))。然而丢弃相位信息会对模型性能产生负面影响。因此,该研究执行清理(sanitization)处理以获得稳定的相位值,从而更好的利用 CSI 信息。

为了从一维 CSI 信号中估计出空间域中的 UV 映射,首先需要将网络输入从 CSI 域转换到空间域。本文采用 Modality Translation Network 完成(如图 4)。经过一番操作,就可以得到由 WiFi 信号生成的图像域中的 3×720×1280 场景表示。

在图像域中获得 3×720×1280 场景表示后,该研究采用类似于 DensePose-RCNN 的网络架构 WiFi-DensePose RCNN 来预测人体 UV 图。具体而言,在 WiFi-DensePose RCNN(图 5)中,该研究使用 ResNet-FPN 作为主干,并从获得的 3 × 720 × 1280 图像特征图中提取空间特征。然后将输出输送到区域提议网络。为了更好地利用不同来源的互补信息,WiFi-DensePose RCNN 还包含两个分支,DensePose head 和 Keypoint head,之后处理结果被合并输入到 refinement 单元。
然而从随机初始化训练 Modality Translation Network 和 WiFi-DensePose RCNN 网络需要大量时间(大约 80 小时)。为了提高训练效率,该研究将一个基于图像的 DensPose 网络迁移到基于 WiFi 的网络中(详见图 6)。

直接初始化基于 WiFi 的网络与基于图像的网络权重无法工作,因此,该研究首先训练了一个基于图像的 DensePose-RCNN 模型作为教师网络,学生网络由 modality translation 网络和 WiFi-DensePose RCNN 组成。这样做的目的是最小化学生模型与教师模型生成的多层特征图之间的差异。
实验
表 1 结果显示,基于 WiFi 的方法得到了很高的 AP@50 值,为 87.2,这表明该模型可以有效地检测出人体 bounding boxes 的大致位置。AP@75 相对较低,值为 35.6,这表明人体细节没有得到完美估计。

表 2 结果显示 dpAP・GPS@50 和 dpAP・GPSm@50 值较高,但 dpAP・GPS@75 和 dpAP・GPSm@75 值较低。这表明本文模型在估计人体躯干的姿势方面表现良好,但在检测四肢等细节方面仍然存在困难。

表 3 和表 4 的定量结果显示,基于图像的方法比基于 WiFi 的方法产生了非常高的 AP。基于 WiFi 的模型 AP-m 值与 AP-l 值的差异相对较小。该研究认为这是因为离相机远的人在图像中占据的空间更少,这导致关于这些对象的信息更少。相反,WiFi 信号包含了整个场景中的所有信息,而不管拍摄对象的位置。


以上是全身追踪、不怕遮挡,CMU两位华人做了个基于WiFi信号的DensePose的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



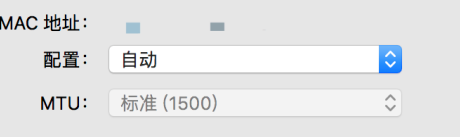 惠普打印机连不上wifi怎么办-惠普打印机连不上wifi的解决方法
Mar 06, 2024 pm 01:00 PM
惠普打印机连不上wifi怎么办-惠普打印机连不上wifi的解决方法
Mar 06, 2024 pm 01:00 PM
很多用户在使用惠普打印机的时候,不熟悉惠普打印机连不上wifi怎么办?下文小编就为各位带来了惠普打印机连不上wifi的解决方法,让我们一起来下文看看吧。惠普打印机mac地址设置为自动选择自动加入网络勾选更改网络配置使用dhcp输入密码连接惠普打印机显示连上wifi
 深入探讨模型、数据和框架:一份详尽的54页高效大语言模型综述
Jan 14, 2024 pm 07:48 PM
深入探讨模型、数据和框架:一份详尽的54页高效大语言模型综述
Jan 14, 2024 pm 07:48 PM
大规模语言模型(LLMs)在许多重要任务中展现出了引人注目的能力,包括自然语言理解、语言生成和复杂推理,并对社会产生了深远的影响。然而,这些出色的能力却需要大量的训练资源(如左图所示)和较长的推理时间(如右图所示)。因此,研究人员需要开发有效的技术手段来解决它们的效率问题。此外,从图的右侧还可以看出,一些高效的LLMs(LanguageModels)如Mistral-7B,已经成功应用于LLMs的设计和部署中。这些高效的LLMs在保持与LLaMA1-33B相近的准确性的同时,能够大大减少推理内存
 win10为何无法连接到Wi-Fi
Jan 16, 2024 pm 04:18 PM
win10为何无法连接到Wi-Fi
Jan 16, 2024 pm 04:18 PM
我们在使用win10操作系统连接wifi无线网的时候会发现出现了连不上wifi网络受限的提示。对于这种问题小编觉得可以尝试一下在网络和共享中心中找到自己的网络,然后进行一系列的调整设置。具体步骤就来看看小编是怎么做的吧~win10为什么连不上wifi方法一1、在电脑屏幕底部通知区域的无线WIFI图标处单击鼠标右键,选择“打开网络和Internet设置”,接着点击“更改适配器选项”按钮。2、在弹出的网络连接界面中,查找名为“WLAN”的无线连接,再次单击右键,并选择“关闭”(或为“禁用”)。3、待
 Win11无法显示WiFi的解决方案
Jan 29, 2024 pm 04:03 PM
Win11无法显示WiFi的解决方案
Jan 29, 2024 pm 04:03 PM
wifi是我们上网的重要媒介,可不少的用户们近期都在反应Win11不显示wifi了,那么这要怎么办?用户们可以直接的点击搜索选项下的服务,然后选择启动类型改成自动就可以了或者是点击左边的网络和internet来进行操作就可以了。下面就让本站来为用户们来仔细的介绍一下win11电脑显示不出wifi列表问题解析吧。win11电脑显示不出wifi列表问题解析方法一:1、点击搜索选项。3、接着我们将启动类型改成自动。方法二:1、我们按住win+i,进入设置。2、点击左边的网络和internet。4、随后
 解决win10无法输入wifi密码的方法
Dec 30, 2023 pm 05:43 PM
解决win10无法输入wifi密码的方法
Dec 30, 2023 pm 05:43 PM
win10wifi不能输入密码是一个非常郁闷的问题,一般情况下就是卡主了,重新打开一下或者重启一下电脑就可以了,还是解决不了的用户,快点来看看详细的解决教程吧。win10wifi无法输入密码教程方法一:1、无法输入密码可能是我们的键盘连接出现了问题,仔细检查一下键盘是否可以使用。2、如果我们需要使用小键盘输入数字的话,还需要查看小键盘是否被锁定了。方法二:注:部分用户反映说执行此操作后,电脑无法开机。实际不是此项设置的原因,而是电脑系统本身有问题。执行此操作后,不会影响电脑的正常启动,电脑系统不
 wifi打不开是什么原因 附:修复wifi功能打不开的方法
Mar 14, 2024 pm 03:34 PM
wifi打不开是什么原因 附:修复wifi功能打不开的方法
Mar 14, 2024 pm 03:34 PM
现在手机除了都有数据和wifi两种上网方法,OPPO手机也不例外,但是我们在使用时打不开wifi功能了要怎么办呢?先不要着急,不妨看下本期教程,就能帮助到您了!手机wifi功能无法开启怎么办可能是因为WLAN开关开启时会略有延迟,请等待2秒后观察是否开启,请勿连续点击。1、可尝试进入「设置>WLAN」,尝试重新打开WLAN开关。2、请打开/关闭一下飞行模式,尝试重新打开WLAN开关。3、重启手机尝试是否能正常打开WLAN。4、建议备份数据后恢复出厂设置尝试。若以上方法均未能解决您的问题,请携带购
 更新Win11后连不上Wifi怎么解决_更新Win11后连不上Wifi如何解决
Mar 20, 2024 pm 05:50 PM
更新Win11后连不上Wifi怎么解决_更新Win11后连不上Wifi如何解决
Mar 20, 2024 pm 05:50 PM
windows11系统是目前最受关注的系统,很多用户升级了Win11,很多电脑操作都要联网之后才能完成,但是如果更新win11后连不上wifi怎么办呢,下面小编就来为大家讲一讲更新win11后连不上wifi解决方法。1、首先,打开开始菜单,进入“设置”,点击“疑难解答”。2、然后选择“其他疑难解答”,点击Internet连接右边的运行即可。3、最终系统会自动协助你处理wifi没法连接的问题。
 win11电脑wifi图标消失解决方法
Jan 07, 2024 pm 12:33 PM
win11电脑wifi图标消失解决方法
Jan 07, 2024 pm 12:33 PM
在新更新的win11系统中有许多的用户都发现自己找不到wifi的图标了,为此我们专给大家带来了win11电脑wifi图标消失解决方法,将设置的开关开启就可以开启wifi设置了。win11电脑wifi图标消失怎么办:1、首先右击下方任务栏,然后点击“任务栏设置”。2、然后点击左侧任务栏中的“任务栏”选项。3、下拉之后就可以看到通知区域,点击“选择哪些图标显示在任务栏上”。4、最后就可以看到下方的网络设置,将后面的开关打开即可。
