

Diffusion+目标检测=可控图像生成!华人团队提出GLIGEN,完美控制对象的空间位置

随着Stable Diffusion的开源,用自然语言进行图像生成也逐渐普及,许多AIGC的问题也暴露了出来,比如AI不会画手、无法理解动作关系、很难控制物体的位置等。
其主要原因还是在于「输入接口」只有自然语言,无法做到对画面的精细控制。
最近来自威斯康星大学麦迪逊分校、哥伦比亚大学和微软的研究热源提出了一个全新的方法GLIGEN,以grounding输入为条件,对现有「预训练文本到图像扩散模型」的功能进行扩展。

论文链接:https://arxiv.org/pdf/2301.07093.pdf
项目主页:https://gligen.github.io/
体验链接:https://huggingface.co/spaces/gligen/demo
为了保留预训练模型的大量概念知识,研究人员没有选择对模型进行微调,而是通过门控机制将输入的不同grounding条件注入到新的可训练层中,以实现对开放世界图像生成的控制。
目前GLIGEN支持四种输入。

(左上)文本实体+box (右上)图像实体+box
(左下)图像风格+文本+box (右下)文本实体+关键点
实验结果也显示,GLIGEN 在 COCO 和 LVIS 上的zero-shot性能大大优于目前有监督layout-to-image基线。
可控图像生成
在扩散模型之前,生成对抗网络(GANs)一直是图像生成领域的一哥,其潜空间和条件输入在「可控操作」和「生成」方面得到了充分的研究。
文本条件自回归和扩散模型表现出惊人的图像质量和概念覆盖率,得益于其更稳定的学习目标和对网络图像-文本配对数据的大规模训练,并迅速出圈,成为辅助艺术设计和创作的工具。
但现有的大规模文本-图像生成模型不能以「文本之外」的其他输入模式为条件,缺乏精确定位概念或使用参考图像来控制生成过程的能力,限制了信息的表达。
比如说,使用文本很难描述一个物体的精确位置,而边界框(bounding
boxes)或关键点(keypoints)则可以很容易实现。

现有的一些工具如inpainting, layout2img生成等可以利用除文本以外的模态输入,但却很少将这些输入结合起来用于可控的text2img生成。
此外,先前的生成模型通常是在特定任务的数据集上独立训练的,而在图像识别领域,长期以来的范式是通过从「大规模图像数据」或「图像-文本对」上预训练的基础模型开始建立特定任务的模型。
扩散模型已经在数十亿的图像-文本对上进行了训练,一个很自然的问题是:我们能否在现有的预训练的扩散模型的基础上,赋予它们新的条件输入模式?
由于预训练模型所具有的大量概念知识,可能能够在其他生成任务上取得更好的性能,同时获得比现有文本-图像生成模型更多的可控性。
GLIGEN
基于上述目的和想法,研究人员提出的GLIGEN模型仍然保留文本标题作为输入,但也启用了其他输入模态,如grounding概念的边界框、grounding参考图像和grounding部分的关键点。
这里面的关键难题是在学习注入新的grounding信息的同时,还保留预训练模型中原有的大量概念知识。
为了防止知识遗忘,研究人员提出冻结原来的模型权重,并增加新的可训练的门控Transformer层以吸收新的grouding输入,下面以边界框为例。
指令输入

每个grouding文本实体都被表示为一个边界框,包含左上角和右下角的坐标值。
需要注意的是,现有的layout2img相关工作通常需要一个概念词典,在评估阶段只能处理close-set的实体(如COCO类别),研究人员发现使用编码图像描述的文本编码器即可将训练集中的定位信息泛化到其他概念上。
训练数据
用于生成grounding图像的训练数据需要文本c和grounding实体e作为条件,在实践中可以通过考虑更灵活的输入来放松对数据的要求。

主要有三种类型的数据
1. grounding数据
每张图片都与描述整张图片的标题相关联;名词实体从标题中提取,并标上边界框。
由于名词实体直接取自自然语言的标题,它们可以涵盖更丰富的词汇,有利于开放世界词汇的grounding生成。
2. 检测数据 Detection data
名词实体是预先定义的close-set类别(例如COCO中的80个物体类别),选择使用classifier-free引导中的空标题token作为标题。
检测数据的数量(百万级)大于基础数据(千级),因此可以大大增加总体训练数据。
3. 检测和标题数据 Detection and Caption data
名词实体与检测数据中的名词实体相同,而图像是单独用文字标题描述的,可能存在名词实体与标题中的实体不完全一致的情况。
比如标题只给出了对客厅的高层次描述,没有提到场景中的物体,而检测标注则提供了更精细的物体层次的细节。
门控注意力机制
研究人员的目标是为现有的大型语言-图像生成模型赋予新的空间基础能力,
大型扩散模型已经在网络规模的图像文本上进行了预训练,以获得基于多样化和复杂的语言指令合成现实图像所需的知识,由于预训练的成本很高,性能也很好,在扩展新能力的同时,在模型权重中保留这些知识是很重要的,可以通过调整新的模块来逐步适应新能力。

在训练过程中,使用门控机制逐渐将新的grounding信息融合到预训练的模型中,这种设计使生成过程中的采样过程具有灵活性,以提高质量和可控性。
实验中也证明了,在采样步骤的前半部分使用完整的模型(所有层),在后半部分只使用原始层(没有门控Transformer层),生成的结果能够更准确反映grounding条件,同时具有较高的图像质量。
实验部分
在开放集合grounded文本到图像生成任务中,首先只用COCO(COCO2014CD)的基础标注进行训练,并评估GLIGEN是否能生成COCO类别以外的基础实体。

可以看到,GLIGEN可以学会新的概念如「蓝鸦」、「羊角面包」,或新的物体属性如「棕色木桌」,而这些信息没有出现在训练类别中。
研究人员认为这是因为GLIGEN的门控自注意力学会了为接下来的交叉注意力层重新定位与标题中的接地实体相对应的视觉特征,并且由于这两层中的共享文本空间而获得了泛化能力。
实验中还定量评估了该模型在LVIS上的zero-shot生成性能,该模型包含1203个长尾物体类别。使用GLIP从生成的图像中预测边界框并计算AP,并将其命名为GLIP得分;将其与为layout2img任务设计的最先进的模型进行比较,

可以发现,尽管GLIGEN模型只在COCO标注上进行了训练,但它比有监督的基线要好得多,可能因为从头开始训练的基线很难从有限的标注中学习,而GLIGEN模型可以利用预训练模型的大量概念知识。

总的来说,这篇论文:
1. 提出了一种新的text2img生成方法,赋予了现有text2img扩散模型新的grounding可控性;
2. 通过保留预训练的权重和学习逐渐整合新的定位层,该模型实现了开放世界的grounded text2img生成与边界框输入,即综合了训练中未观察到的新的定位概念;
3. 该模型在layout2img任务上的zero-shot性能明显优于之前的最先进水平,证明了大型预训练生成模型可以提高下游任务的性能
以上是Diffusion+目标检测=可控图像生成!华人团队提出GLIGEN,完美控制对象的空间位置的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何在 Windows 11 中清除桌面背景最近的图像历史记录
Apr 14, 2023 pm 01:37 PM
如何在 Windows 11 中清除桌面背景最近的图像历史记录
Apr 14, 2023 pm 01:37 PM
Windows 11 改进了系统中的个性化功能,这使用户可以查看之前所做的桌面背景更改的近期历史记录。当您进入windows系统设置应用程序中的个性化部分时,您可以看到各种选项,更改背景壁纸也是其中之一。但是现在可以看到您系统上设置的背景壁纸的最新历史。如果您不喜欢看到此内容并想清除或删除此最近的历史记录,请继续阅读这篇文章,它将帮助您详细了解如何使用注册表编辑器进行操作。如何使用注册表编辑
 i7-7700无法升级至Windows 11的解决方案
Dec 26, 2023 pm 06:52 PM
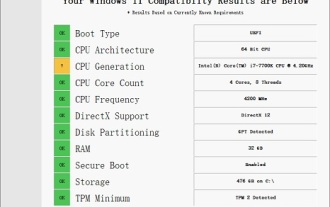
i7-7700无法升级至Windows 11的解决方案
Dec 26, 2023 pm 06:52 PM
i77700的性能运行win11完全足够,但是用户却发现自己的i77700不能升级win11,这主要是受到了微软硬性条件的限制,所以只要跳过该限制就能安装了。i77700不能升级win11:1、因为微软限制了cpu的版本。2、intel只有第八代及以上版本可以直升win11。3、而i77700作为7代,无法满足win11的升级需求。4、但是i77700在性能上是完全能流畅使用win11的。5、所以大家可以使用本站的win11直装系统。6、下载完成后,右键“装载”该文件。7、再双击运行其中的“一键
 摔倒检测,基于骨骼点人体动作识别,部分代码用 Chatgpt 完成
Apr 12, 2023 am 08:19 AM
摔倒检测,基于骨骼点人体动作识别,部分代码用 Chatgpt 完成
Apr 12, 2023 am 08:19 AM
哈喽,大家好。今天给大家分享一个摔倒检测项目,准确地说是基于骨骼点的人体动作识别。大概分为三个步骤识别人体识别人体骨骼点动作分类项目源码已经打包好了,获取方式见文末。0. chatgpt首先,我们需要获取监控的视频流。这段代码比较固定,我们可以直接让chatgpt完成chatgpt写的这段代码是没有问题的,可以直接使用。但后面涉及到业务型任务,比如:用mediapipe识别人体骨骼点,chatgpt给出的代码是不对的。我觉得chatgpt可以作为一个工具箱,能独立于业务逻辑,都可以试着交给c
 如何在电脑上下载 Windows 聚光灯壁纸图像
Aug 23, 2023 pm 02:06 PM
如何在电脑上下载 Windows 聚光灯壁纸图像
Aug 23, 2023 pm 02:06 PM
窗户从来不是一个忽视美学的人。从XP的田园绿场到Windows11的蓝色漩涡设计,默认桌面壁纸多年来一直是用户愉悦的源泉。借助WindowsSpotlight,您现在每天都可以直接访问锁屏和桌面壁纸的美丽、令人敬畏的图像。不幸的是,这些图像并没有闲逛。如果您爱上了Windows聚光灯图像之一,那么您将想知道如何下载它们,以便将它们作为背景保留一段时间。以下是您需要了解的所有信息。什么是WindowsSpotlight?窗口聚光灯是一个自动壁纸更新程序,可以从“设置”应用中的“个性化>
 如何在Python中使用图像语义分割技术?
Jun 06, 2023 am 08:03 AM
如何在Python中使用图像语义分割技术?
Jun 06, 2023 am 08:03 AM
随着人工智能技术的不断发展,图像语义分割技术已经成为图像分析领域的热门研究方向。在图像语义分割中,我们将一张图像中的不同区域进行分割,并对每个区域进行分类,从而达到对这张图像的全面理解。Python是一种著名的编程语言,其强大的数据分析和数据可视化能力使其成为了人工智能技术研究领域的首选。本文将介绍如何在Python中使用图像语义分割技术。一、前置知识在深入
 如何在Windows上使用PowerToys批量调整图像大小
Aug 23, 2023 pm 07:49 PM
如何在Windows上使用PowerToys批量调整图像大小
Aug 23, 2023 pm 07:49 PM
那些必须每天处理图像文件的人经常不得不调整它们的大小以适应他们的项目和工作的需求。但是,如果要处理的图像太多,则单独调整它们的大小会消耗大量时间和精力。在这种情况下,像PowerToys这样的工具可以派上用场,除其他外,可以使用其图像调整大小器实用程序批量调整图像文件的大小。以下是设置图像调整器设置并开始使用PowerToys批量调整图像大小的方法。如何使用PowerToys批量调整图像大小PowerToys是一个多合一的程序,具有各种实用程序和功能,可帮助您加快日常任务。它的实用程序之一是图像
 MIT最新力作:用GPT-3.5解决时间序列异常检测问题
Jun 08, 2024 pm 06:09 PM
MIT最新力作:用GPT-3.5解决时间序列异常检测问题
Jun 08, 2024 pm 06:09 PM
今天给大家介绍一篇MIT上周发表的文章,使用GPT-3.5-turbo解决时间序列异常检测问题,初步验证了LLM在时间序列异常检测中的有效性。整个过程没有进行finetune,直接使用GPT-3.5-turbo进行异常检测,文中的核心是如何将时间序列转换成GPT-3.5-turbo可识别的输入,以及如何设计prompt或者pipeline让LLM解决异常检测任务。下面给大家详细介绍一下这篇工作。图片论文标题:Largelanguagemodelscanbezero-shotanomalydete
 iOS 17:如何在照片中使用一键裁剪
Sep 20, 2023 pm 08:45 PM
iOS 17:如何在照片中使用一键裁剪
Sep 20, 2023 pm 08:45 PM
借助iOS17照片应用,Apple可以更轻松地根据您的规格裁剪照片。继续阅读以了解如何操作。以前在iOS16中,在“照片”应用程序中裁剪图像涉及几个步骤:点击编辑界面,选择裁剪工具,然后通过捏合缩放手势或拖动裁剪工具的角来调整裁剪。在iOS17中,值得庆幸的是,苹果简化了这个过程,这样当你放大照片库中任何选定的照片时,一个新的“裁剪”按钮会自动出现在屏幕的右上角。点击它会弹出完整的裁剪界面,其中包含您选择的缩放级别,因此您可以裁剪到您喜欢的图像部分,旋转图像,反转图像,或应用屏幕比例,或使用标记
