

一文浅谈深度学习泛化能力


一、DNN泛化能力的问题
论文主要探讨的是, 为什么过参数的神经网络模型还能有不错的泛化性?即并不是简单记忆训练集,而是从训练集中总结出一个通用的规律,从而可以适配于测试集(泛化能力)。

以经典的决策树模型为例, 当树模型学习数据集的通用规律时:一种好的情况,假如树第一个分裂节点时,刚好就可以良好区分开不同标签的样本,深度很小,相应的各叶子上面的样本数是够的(即统计规律的数据量的依据也是比较多的),那这会得到的规律就更有可能泛化到其他数据。(即:拟合良好, 有泛化能力)。
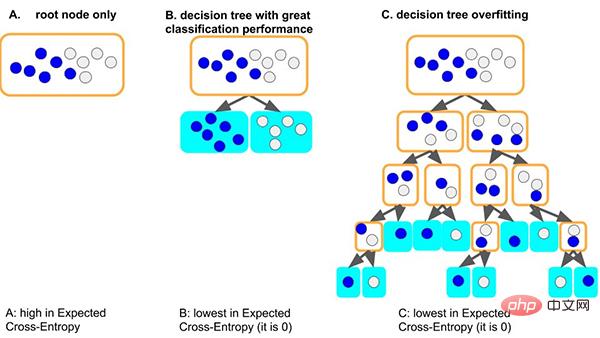
另外一种较差的情况,如果树学习不好一些通用的规律,为了学习这个数据集,那树就会越来越深,可能每个叶子节点分别对应着少数样本(少数据带来统计信息可能只是噪音),最后,死记硬背地记住所有数据(即:过拟合 无泛化能力)。我们可以看到过深(depth)的树模型很容易过拟合。
那么过参数化的神经网络如何达到良好的泛化性呢?
二、 DNN泛化能力的原因
本文是从一个简单通用的角度解释——在神经网络的梯度下降优化过程上,探索泛化能力的原因:
我们总结了梯度相干理论 :来自不同样本的梯度产生相干性,是神经网络能有良好的泛化能力原因。当不同样本的梯度在训练过程中对齐良好,即当它们相干时,梯度下降是稳定的,可以很快收敛,并且由此产生的模型可以有良好的泛化性。否则,如果样本太少或训练时间过长,可能无法泛化。

基于该理论,我们可以做出如下解释。
2.1 宽度神经网络的泛化性
更宽的神经网络模型具有良好的泛化能力。这是因为,更宽的网络都有更多的子网络,对比小网络更有产生梯度相干的可能,从而有更好的泛化性。换句话说,梯度下降是一个优先考虑泛化(相干性)梯度的特征选择器,更广泛的网络可能仅仅因为它们有更多的特征而具有更好的特征。
- 论文原文:Generalization and width. Neyshabur et al. [2018b] found that wider networks generalize better. Can we now explain this? Intuitively, wider networks have more sub-networks at any given level, and so the sub-network with maximum coherence in a wider network may be more coherent than its counterpart in a thinner network, and hence generalize better. In other words, since—as discussed in Section 10—gradient descent is a feature selector that prioritizes well-generalizing (coherent) features, wider networks are likely to have better features simply because they have more features. In this connection, see also the Lottery Ticket Hypothesis [Frankle and Carbin, 2018]
- 论文链接:https://github.com/aialgorithm/Blog
但是个人觉得,这还是要区分下网络输入层/隐藏层的宽度。特别对于数据挖掘任务的输入层,由于输入特征是通常是人工设计的,需要考虑下做下特征选择(即减少输入层宽度),不然直接输入特征噪音,对于梯度相干性影响不也是有干扰的。
2.2 深度神经网络的泛化性
越深的网络,梯度相干现象被放大,有更好的泛化能力。

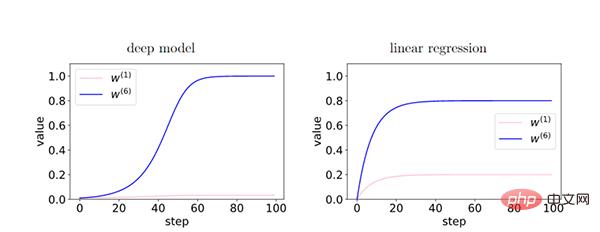
在深度模型中,由于层之间的反馈加强了有相干性的梯度,存在相干性梯度的特征(W6)和非相干梯度的特征(W1)之间的相对差异在训练过程中呈指数放大。从而使得更深的网络更偏好相干梯度,从而更好泛化能力。
2.3 早停(early-stopping)
通过早停我们可以减少非相干梯度的过多影响,提高泛化性。
在训练的时候,一些容易样本比其他样本(困难样本)更早地拟合。训练前期,这些容易样本的相干梯度做主导,并很容易拟合好。训练后期,以困难样本的非相干梯度主导了平均梯度g(wt),从而导致泛化能力变差,这个时候就需要早停。

- (注:简单的样本,是那些在数据集里面有很多梯度共同点的样本,正由于这个原因,大多数梯度对它有益,收敛也比较快。)
2.4 全梯度下降 VS 学习率
我们发现全梯度下降也可以有很好的泛化能力。此外,仔细的实验表明随机梯度下降并不一定有更优的泛化,但这并不排除随机梯度更易跳出局部最小值、起着正则化等的可能性。
- Based on our theory, finite learning rate, and mini-batch stochasticity are not necessary for generalization
我们认为较低的学习率可能无法降低泛化误差,因为较低的学习率意味着更多的迭代次数(与早停相反)。
- Assuming a small enough learning rate, as training progresses, the generalization gap cannot decrease. This follows from the iterative stability analysis of training: with 40 more steps, stability can only degrade. If this is violated in a practical setting, it would point to an interesting limitation of the theory
2.5 L2、L1正则化
目标函数加入L2、L1正则化,相应的梯度计算, L1正则项需增加的梯度为sign(w) ,L2梯度为w。以L2正则为例,相应的梯度W(i+1)更新公式为:图片
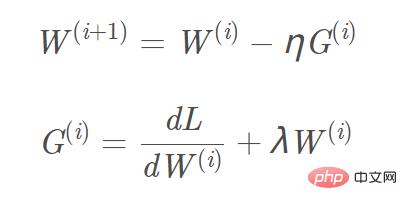
我们可以把“L2正则化(权重衰减)”看作是一种“背景力”,可将每个参数推近于数据无关的零值 ( L1容易得到稀疏解,L2容易得到趋近0的平滑解) ,来消除在弱梯度方向上影响。只有在相干梯度方向的情况下,参数才比较能脱离“背景力”,基于数据完成梯度更新。

2.6 梯度下降算法的进阶
- Momentum 、Adam等梯度下降算法
Momentum 、Adam等梯度下降算法,其参数W更新方向不仅由当前的梯度决定,也与此前累积的梯度方向有关(即,保留累积的相干梯度的作用)。这使得参数中那些梯度方向变化不大的维度可以加速更新,并减少梯度方向变化较大的维度上的更新幅度,由此产生了加速收敛和减小震荡的效果。
- 抑制弱梯度方向的梯度下降
我们可以通过优化批次梯度下降算法,来抑制弱梯度方向的梯度更新,进一步提高了泛化能力。比如,我们可以使用梯度截断(winsorized gradient descent),排除梯度异常值后的再取平均值。或者取梯度的中位数代替平均值,以减少梯度异常值的影响。

小结
文末说两句,对于深度学习的理论,有兴趣可以看下论文提及的相关研究。
以上是一文浅谈深度学习泛化能力的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Python中使用BERT进行情感分析的方法及步骤
Jan 22, 2024 pm 04:24 PM
Python中使用BERT进行情感分析的方法及步骤
Jan 22, 2024 pm 04:24 PM
BERT是由Google在2018年提出的一种预训练的深度学习语言模型。全称为BidirectionalEncoderRepresentationsfromTransformers,它基于Transformer架构,具有双向编码的特点。相比于传统的单向编码模型,BERT在处理文本时能够同时考虑上下文的信息,因此在自然语言处理任务中表现出色。它的双向性使得BERT能够更好地理解句子中的语义关系,从而提高了模型的表达能力。通过预训练和微调的方法,BERT可以用于各种自然语言处理任务,如情感分析、命名
 YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度学习方法专注于设计最适合的目标函数,以使模型的预测结果与实际情况最接近。同时,必须设计一个合适的架构,以便为预测获取足够的信息。现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。本文将深入探讨数据通过深度网络传输时的重要问题,即信息瓶颈和可逆函数。基于此提出了可编程梯度信息(PGI)的概念,以应对深度网络实现多目标所需的各种变化。PGI可以为目标任务提供完整的输入信息,以计算目标函数,从而获得可靠的梯度信息以更新网络权重。此外设计了一种新的轻量级网络架
 潜藏空间嵌入:解释与示范
Jan 22, 2024 pm 05:30 PM
潜藏空间嵌入:解释与示范
Jan 22, 2024 pm 05:30 PM
潜在空间嵌入(LatentSpaceEmbedding)是将高维数据映射到低维空间的过程。在机器学习和深度学习领域中,潜在空间嵌入通常是通过神经网络模型将高维输入数据映射为一组低维向量表示,这组向量通常被称为“潜在向量”或“潜在编码”。潜在空间嵌入的目的是捕捉数据中的重要特征,并将其表示为更简洁和可理解的形式。通过潜在空间嵌入,我们可以在低维空间中对数据进行可视化、分类、聚类等操作,从而更好地理解和利用数据。潜在空间嵌入在许多领域中都有广泛的应用,如图像生成、特征提取、降维等。潜在空间嵌入的主要
 超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
写在前面今天我们探讨下深度学习技术如何改善在复杂环境中基于视觉的SLAM(同时定位与地图构建)性能。通过将深度特征提取和深度匹配方法相结合,这里介绍了一种多功能的混合视觉SLAM系统,旨在提高在诸如低光条件、动态光照、弱纹理区域和严重抖动等挑战性场景中的适应性。我们的系统支持多种模式,包括拓展单目、立体、单目-惯性以及立体-惯性配置。除此之外,还分析了如何将视觉SLAM与深度学习方法相结合,以启发其他研究。通过在公共数据集和自采样数据上的广泛实验,展示了SL-SLAM在定位精度和跟踪鲁棒性方面优
 一文搞懂:AI、机器学习与深度学习的联系与区别
Mar 02, 2024 am 11:19 AM
一文搞懂:AI、机器学习与深度学习的联系与区别
Mar 02, 2024 am 11:19 AM
在当今科技日新月异的浪潮中,人工智能(ArtificialIntelligence,AI)、机器学习(MachineLearning,ML)与深度学习(DeepLearning,DL)如同璀璨星辰,引领着信息技术的新浪潮。这三个词汇频繁出现在各种前沿讨论和实际应用中,但对于许多初涉此领域的探索者来说,它们的具体含义及相互之间的内在联系可能仍笼罩着一层神秘面纱。那让我们先来看看这张图。可以看出,深度学习、机器学习和人工智能之间存在着紧密的关联和递进关系。深度学习是机器学习的一个特定领域,而机器学习
 超强!深度学习Top10算法!
Mar 15, 2024 pm 03:46 PM
超强!深度学习Top10算法!
Mar 15, 2024 pm 03:46 PM
自2006年深度学习概念被提出以来,20年快过去了,深度学习作为人工智能领域的一场革命,已经催生了许多具有影响力的算法。那么,你所认为深度学习的top10算法有哪些呢?以下是我心目中深度学习的顶尖算法,它们在创新性、应用价值和影响力方面都占据重要地位。1、深度神经网络(DNN)背景:深度神经网络(DNN)也叫多层感知机,是最普遍的深度学习算法,发明之初由于算力瓶颈而饱受质疑,直到近些年算力、数据的爆发才迎来突破。DNN是一种神经网络模型,它包含多个隐藏层。在该模型中,每一层将输入传递给下一层,并
 1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显着的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 AlphaFold 3 重磅问世,全面预测蛋白质与所有生命分子相互作用及结构,准确性远超以往水平
Jul 16, 2024 am 12:08 AM
AlphaFold 3 重磅问世,全面预测蛋白质与所有生命分子相互作用及结构,准确性远超以往水平
Jul 16, 2024 am 12:08 AM
编辑|萝卜皮自2021年发布强大的AlphaFold2以来,科学家们一直在使用蛋白质结构预测模型来绘制细胞内各种蛋白质结构的图谱、发现药物,并绘制每种已知蛋白质相互作用的「宇宙图」 。就在刚刚,GoogleDeepMind发布了AlphaFold3模型,该模型能够对包括蛋白质、核酸、小分子、离子和修饰残基在内的复合物进行联合结构预测。 AlphaFold3的准确性对比过去许多专用工具(蛋白质-配体相互作用、蛋白质-核酸相互作用、抗体-抗原预测)有显着提高。这表明,在单个统一的深度学习框架内,可以实现
