

在软件缺陷预测中使用软件可视化和迁移学习

文章的动机是避开源代码的中间表示,将源代码表示为图像,直接提取代码的语义信息以改进缺陷预测的性能。
首先,看到如下图所示的motivation示例。File1.java和File2.java两个示例中,虽然都包含了1个if语句、2个for语句和4个函数调用,但代码的语义和结构特征是不相同的。为验证将源代码转换成图像是否有助于区分不同的代码,作者进行了实验:将源代码根据字符的ASCII十进制数对应到像素,排列成像素矩阵,获取源代码的图像。作者指出,不同的源代码图像存在差异。

Fig. 1 Motivation Example
文章主要的贡献如下:
将代码转换成图像,从中提取语义和结构信息;
提出一种端到端的框架,结合自注意力机制和迁移学习实现缺陷预测。
文章提出的模型框架如图2所示,分为两个阶段:源代码可视化和深度迁移学习建模。
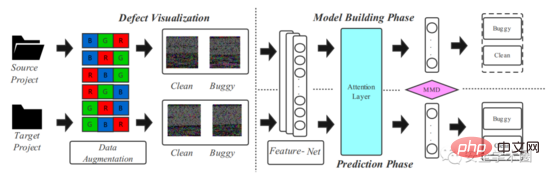
Fig. 2 Framework
1.源代码可视化
文章将源代码转换成6个图像,过程如图3所示。将源代码字符的10进制ASCII码转换成8bit无符号整数向量,按行和列对这些向量进行排列,生成图像矩阵。8bit整数直接对应到灰度等级。为解决原始数据集较小的问题,作者在文章中提出了一种基于颜色增强的数据集扩充方法:对R、G、B三个颜色通道的值进行排列组合,产生6个彩色图。这里看着挺迷的,变换了通道值后,语义和结构信息应该有所改变吧?但是作者在脚注上进行了解释,如图4所示。
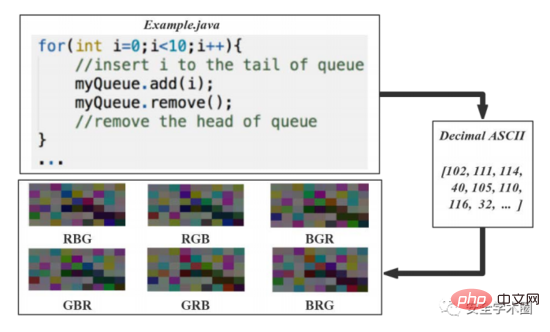
Fig. 3 源代码可视化流程

Fig. 4 文章脚注2
2.深度迁移学习建模
文章使用DAN网络来捕获源代码的语义和结构信息。为增强模型对重要信息的表达能力,作者在原始DAN结构中加入了Attention层。训练与测试流程如图5所示,其中conv1-conv5来自于AlexNet,4个全连接层fc6-fc9作为分类器。作者提到,对于一个新的项目,训练深度学习模型需要有大量的标签数据,这是困难的。所以,作者首先在ImageNet 2012上训练了一个预训练模型,使用预训练模型的参数作为初始参数来微调所有卷积层,进而减少代码图像和ImageNet 2012中图像的差异。
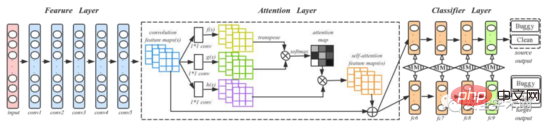
Fig. 5 训练与测试流程
3.模型训练和预测
对Source项目中有标签的代码和Target项目中无标签的代码生成代码图像,同时送入模型;二者共享卷积层和Attention层来提取各自的特征。在全连接层计算Source和Target之间的MK-MDD(Multi Kernel Variant Maximum Mean Discrepancy)。由于Target没有标签,所以只对Source计算交叉熵。模型使用mini-batch随机梯度下降沿着损失函数训练模型。对每一个
在实验部分,作者选择了PROMISE数据仓库中所有开源的Java项目,收集了它们的版本号、class name、是否存在bug的标签。根据版本号和class name在github中下载源码。最终,共采集了10个Java项目的数据。数据集结构如图6所示。
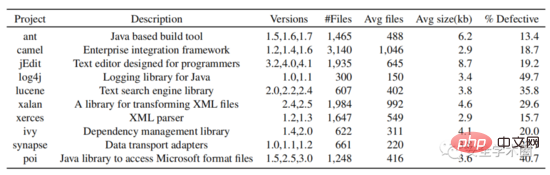
Fig. 6 数据集结构
对于项目内缺陷预测,文章选择如下baseline模型进行对比:

对于跨项目缺陷预测,文章选择如下baseline模型进行对比:

总结一下,虽然是两年前的论文了,但感觉思路还是比较新奇的,避开AST等一系列代码中间表示,直接将代码转换成图像提取特征。但是还是比较疑惑,代码转换成的图像真的包含源代码语义和结构信息吗?感觉可解释性不太强,哈哈。后面需要做实验分析下吧。
以上是在软件缺陷预测中使用软件可视化和迁移学习的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 bonjour是什么软件能卸载吗
Feb 20, 2024 am 09:33 AM
bonjour是什么软件能卸载吗
Feb 20, 2024 am 09:33 AM
标题:探究Bonjour软件及其卸载方法摘要:本文将介绍Bonjour软件的功能、使用范围以及如何卸载该软件。同时,还将解释如何使用其他工具来替代Bonjour,以满足用户的需求。引言:在计算机和网络技术领域中,Bonjour是一种常见的软件。尽管某些用户可能对此不熟悉,但它在一些特定情况下非常有用。如果你碰巧安装了Bonjour软件,但现在想要卸载它,那么
 WPS Office无法打开PPT文件怎么办-WPS Office无法打开PPT文件的解决方法
Mar 04, 2024 am 11:40 AM
WPS Office无法打开PPT文件怎么办-WPS Office无法打开PPT文件的解决方法
Mar 04, 2024 am 11:40 AM
近期有很多小伙伴咨询小编WPSOffice无法打开PPT文件怎么办,接下来就让我们一起学习一下WPSOffice无法打开PPT文件的解决方法吧,希望可以帮助到大家。1、首先打开WPSOffice,进入首页,如下图所示。2、然后在上方搜索栏输入关键词“文档修复”,然后点击打开文档修复工具,如下图所示。3、接着导入PPT文件进行修复就可以了,如下图所示。
 crystaldiskmark是什么软件?-crystaldiskmark如何使用?
Mar 18, 2024 pm 02:58 PM
crystaldiskmark是什么软件?-crystaldiskmark如何使用?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark是一款适用于硬盘的小型HDD基准测试工具,可以快速测量顺序和随机读/写速度。接下来就让小编为大家介绍一下CrystalDiskMark,以及crystaldiskmark如何使用吧~一、CrystalDiskMark介绍CrystalDiskMark是一款广泛使用的磁盘性能测试工具,用于评估机械硬盘和固态硬盘(SSD)的读写速度和随机I/O性能。它是一款免费的Windows应用程序,并提供用户友好的界面和各种测试模式来评估硬盘驱动器性能的不同方面,并被广泛用于硬件评
![海盗船iCUE软件不检测RAM [修复]](https://img.php.cn/upload/article/000/465/014/170831448976874.png?x-oss-process=image/resize,m_fill,h_207,w_330) 海盗船iCUE软件不检测RAM [修复]
Feb 19, 2024 am 11:48 AM
海盗船iCUE软件不检测RAM [修复]
Feb 19, 2024 am 11:48 AM
本文将探讨当CorsairiCUE软件无法识别Windows系统中的RAM时,用户可以采取的措施。尽管CorsairiCUE软件旨在让用户控制计算机的RGB照明,但一些用户发现软件无法正常运行,导致无法检测RAM模块。为什么ICUE不拿起我的内存?ICUE无法正确识别RAM的主要原因通常是与后台软件冲突有关,另外错误的SPD写入设置也可能导致这个问题的发生。修复了CorsairIcue软件无法检测到RAM的问题如果CorsairIcue软件未在Windows计算机上检测到RAM,请使用以下建议。
 CrystalDiskinfo使用教程-CrystalDiskinfo是什么软件?
Mar 18, 2024 pm 04:50 PM
CrystalDiskinfo使用教程-CrystalDiskinfo是什么软件?
Mar 18, 2024 pm 04:50 PM
CrystalDiskInfo是一款用来查看电脑硬件设备的软件,在这款软件中我们可以对自己的电脑硬件进行查看,例如读取速度、传输模式以及接口等!那么除了这些功能之外,CrystalDiskInfo怎么使用,CrystalDiskInfo究竟是什么呢,下面就让小编为大家整理一下吧!一、CrystalDiskInfo的由来作为电脑主机三大件之一,固态硬盘是电脑的存储媒介,负责电脑的数据存储,一块好的固态硬盘能加快文件的读取速度,影响消费者使用体验。当消费者收到新设备时,可通过第三方软件或其他固态硬盘
 Adobe Illustrator CS6怎样设置键盘增量-Adobe Illustrator CS6设置键盘增量的方法
Mar 04, 2024 pm 06:04 PM
Adobe Illustrator CS6怎样设置键盘增量-Adobe Illustrator CS6设置键盘增量的方法
Mar 04, 2024 pm 06:04 PM
很多用户办公中都在使用AdobeIllustratorCS6软件,那么你们知道AdobeIllustratorCS6怎样设置键盘增量吗?接着,小编就为大伙带来了AdobeIllustratorCS6设置键盘增量的方法,感兴趣的用户快来下文看看吧。第一步:启动AdobeIllustratorCS6软件,如下图所示。第二步:在菜单栏中,依次单击【编辑】→【首选项】→【常规】命令。第三步:弹出【键盘增量】对话框,在【键盘增量】文本框中输入需要的数字,最后单击【确定】按钮。第四步:使用快捷键【Ctrl】
 一个不兼容的软件尝试与Edge加载怎么解决?
Mar 15, 2024 pm 01:34 PM
一个不兼容的软件尝试与Edge加载怎么解决?
Mar 15, 2024 pm 01:34 PM
我们在使用Edge浏览器的时候有时候会出现不兼容的软件尝试一起加载,那么这是怎么回事?下面就让本站来为用户们来仔细的介绍一下一个不兼容的软件尝试与Edge加载怎么解决吧。 一个不兼容的软件尝试与Edge加载怎么解决 解决方案一: 开始菜单搜IE,直接用IE访问即可。 解决方案二: 注意:修改注册表可能会导致系统故障,谨慎操作。 修改注册表参数。 1、运行中输入regedit。 2、找到路径\HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Micros
 bonjour是什么软件有用吗
Feb 22, 2024 pm 08:39 PM
bonjour是什么软件有用吗
Feb 22, 2024 pm 08:39 PM
Bonjour是由苹果公司推出的一项网络协议和软件,用于在局域网内发现和配置网络服务。它的主要作用是在同一网络中连接的设备之间自动发现和通信。Bonjour最早在2002年的MacOSX10.2版本中引入,并且现在已经在苹果的操作系统中被默认安装和启用了。此后,苹果公司将Bonjour的技术开放给其他厂商使用,因此许多其他操作系统和设备也能够支持Bon
