

从BERT到ChatGPT,北航等9大顶尖研究机构全面综述:那些年一起追过的「预训练基础模型」

ChatGPT在few-shot和zero-shot场景下展现出的惊人性能,让研究人员们更坚定「预训练」是一条正确的路线。
预训练基础模型(Pretrained Foundation Models, PFM)被认为是不同数据模式下各种下游任务的基础,即基于大规模数据,对 BERT、 GPT-3、 MAE、 DALLE-E 和 ChatGPT 等预训练基础模型进行训练,为下游应用提供了合理的参数初始化。
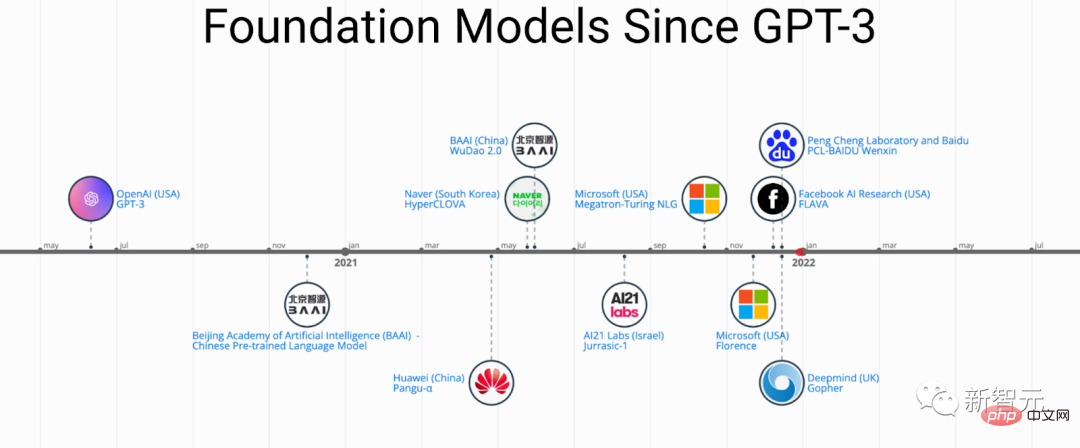
PFM 背后的预训练思想在大型模型的应用中起着重要作用,与以往采用卷积和递归模块进行特征提取的方法不同,生成预训练(GPT)方法采用 Transformer 作为特征提取器,在大型数据集上进行自回归训练。
随着 PFM 在各个领域获得巨大成功,近几年发表的论文中提出了大量的方法、数据集和评价指标,行业内需要一篇从BERT开始一直追踪到ChatGPT发展过程的全面综述。
最近,来自北航、密歇根州立大学、理海大学、南洋理工、杜克等国内外多所知名院校、企业的研究人员联合写了一篇关于预训练基础模型的综述,提供了在文本、图像和图(graph)等领域的最近的研究进展,以及目前和未来的挑战、机遇。

论文链接:https://arxiv.org/pdf/2302.09419.pdf
研究人员首先回顾了自然语言处理、计算机视觉和图形学习的基本组成部分和现有的预训练;然后讨论了其他先进的 PFM 的其他数据模式和统一的 PFM 考虑数据质量和数量;以及PFM 基本原理的相关研究,包括模型效率和压缩、安全性和隐私性;最后,文中列出了几个关键的结论,包括未来的研究方向、挑战和开放的问题。
从BERT到ChatGPT
预训练基础模型(PFMs)是大数据时代构建人工智能系统的重要组成部分,其在自然语言处理(NLP)、计算机视觉(CV)和图学习(GL)三大人工智能领域得到广泛的研究和应用。
PFMs是通用模型,在各个领域内或跨领域任务中都很有效,在各种学习任务中学习特征表示方面表现出巨大的潜力,如文本分类、文本生成、图像分类、物体检测和图分类等。
PFMs在用大规模语料库训练多个任务并对类似的小规模任务进行微调方面表现出卓越的性能,使得启动快速数据处理成为可能。
PFMs和预训练
PFMs是基于预训练技术的,其目的是利用大量的数据和任务来训练一个通用模型,在不同的下游应用中可以很容易地进行微调。
预训练的想法起源于CV任务中的迁移学习,在认识到预训练在CV领域的有效性后,人们开始使用预训练技术来提高其他领域的模型性能。当把预训练技术应用于NLP领域时,经过良好训练的语言模型(LMs)可以捕捉到对下游任务有益的丰富知识,如长期依赖关系、层次关系等。
此外,预训练在NLP领域的显著优势是,训练数据可以来自任何未标记的文本语料库,也就是说,在预训练过程中存在着无限量的训练数据。
早期的预训练是一种静态方法,如NNLM和Word2vec,很难适应不同的语义环境;后来有研究人员提出了动态预训练技术,如BERT、XLNet等。

PFMs在NLP、CV和GL领域的历史和演变
基于预训练技术的PFMs使用大型语料库来学习通用语义表征,随着这些开创性工作的引入,各种PFMs已经出现,并被应用于下游的任务和应用。
一个显著的PFM应用案例就是最近爆火的ChatGPT。
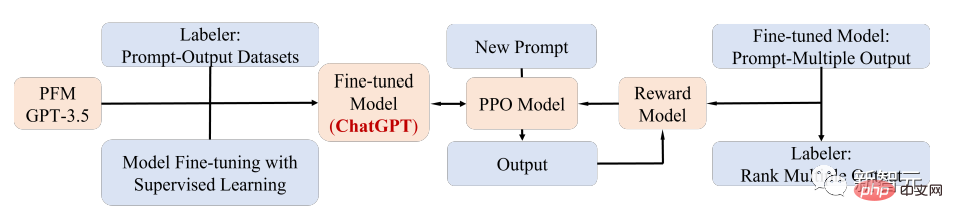
ChatGPT是从生成式预训练Transformer,即GPT-3.5在文本和代码的混合语料训练后,再微调得到的;ChatGPT使用了来自人类反馈的强化学习(RLHF)技术,也是目前将大型LM与人类的意图相匹配的一种最有前景的方法。
ChatGPT的优越性能可能会导致每一类PFMs的训练范式转变的临界点,即应用指令对齐(instruction aligning)技术,包括强化学习(RL)、prompt tuning和思维链(chain-of-thought),并最终走向通用人工智能。
这篇文章中,研究人员主要回顾了文本、图像和图(graph)相关的PFM,也是一个相对成熟的研究分类方法。
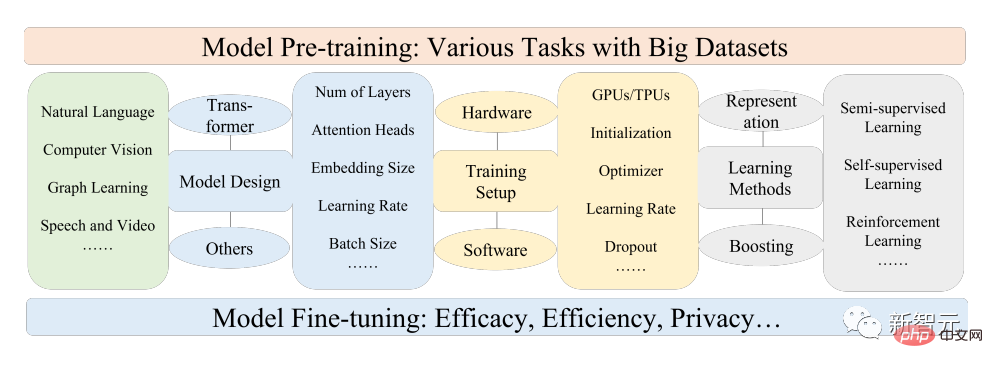
对于文本来说,语言模型通过预测下一个单词或字符即可实现多种任务,例如,PFMs可用于机器翻译、问题回答系统、主题建模、情感分析等。
对于图像来说,类似于文本中的PFMs,使用大规模的数据集来训练一个适合多个CV任务的大模型。
对于图来说,相似的预训练思路也被用于获得PFMs,可用于诸多下游任务。
除了针对特定数据域的PFMs,文中还回顾并阐述了其他一些先进的PFMs,如针对语音、视频和跨域数据的PFMs,以及多模态PFMs。
此外,一个能够处理多模态的PFMs的大融合趋势正在出现,也就是所谓的统一(unified)PFMs;研究人员首先定义了统一PFMs的概念,然后回顾了近期研究中最先进的统一PFMs,包括OFA、UNIFIED-IO、FLAVA、BEiT-3等。
根据这三个领域现有的PFMs的特点,研究人员得出结论,PFMs有以下两大优势:
1. 只需要进行极少的微调就可以提高模型在下游任务上的表现;
2. PFMs已经在质量方面通过了考验。
与其从头开始建立一个模型来解决类似的问题,更好的选择是将PFMs应用于与任务相关的数据集。
PFMs的巨大前景激发了大量的相关工作来关注模型的效率、安全性和压缩等问题。
这篇综述的特点在于:
- 研究人员跟踪了最新的研究成果,对PFM在NLP、CV和GL中的发展进行了扎实的总结,讨论并提供了关于这三个主要应用领域中通用的PFM设计和预训练方法的思考结果。
- 总结了PFMs在其他多媒体领域的发展,如语音和视频,还进一步讨论了关于PFMs的更深层次的话题,包括统一的PFMs、模型效率和压缩,以及安全和隐私。
- 通过对各种模态下不同任务的PFMs的回顾,讨论了在大数据时代对超大型模型未来研究的主要挑战和机遇,将引导开发新一代基于PFMs的协作和交互智能。
参考资料:https://arxiv.org/abs/2302.09419
以上是从BERT到ChatGPT,北航等9大顶尖研究机构全面综述:那些年一起追过的「预训练基础模型」的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 于 2023 年 9 月正式推出,是比其前身大幅改进的型号。它被认为是迄今为止最好的人工智能图像生成器之一,能够创建具有复杂细节的图像。然而,在推出时,它不包括
 ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人引言:在当今信息时代,智能客服系统已经成为企业与客户之间重要的沟通工具。而为了提供更好的客户服务体验,许多企业开始转向采用聊天机器人的方式来完成客户咨询、问题解答等任务。在这篇文章中,我们将介绍如何使用OpenAI的强大模型ChatGPT和Python语言结合,来打造一个智能客服聊天机器人,以提高
 手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
安装步骤:1、在ChatGTP官网或手机商店上下载ChatGTP软件;2、打开后在设置界面中,选择语言为中文;3、在对局界面中,选择人机对局并设置中文相谱;4、开始后在聊天窗口中输入指令,即可与软件进行交互。
 如何使用ChatGPT和Java开发智能聊天机器人
Oct 28, 2023 am 08:54 AM
如何使用ChatGPT和Java开发智能聊天机器人
Oct 28, 2023 am 08:54 AM
在这篇文章中,我们将介绍如何使用ChatGPT和Java开发智能聊天机器人,并提供一些具体的代码示例。ChatGPT是由OpenAI开发的困境预测转换(GenerativePre-trainingTransformer)的最新版本,它是一种基于神经网络的人工智能技术,可以理解自然语言并生成人类类似的文本。使用ChatGPT,我们可以轻松地创建自适应的聊天
 chatgpt国内可以使用吗
Mar 05, 2024 pm 03:05 PM
chatgpt国内可以使用吗
Mar 05, 2024 pm 03:05 PM
chatgpt在国内可以使用,但不能注册,港澳也不行,用户想要注册的话,可以使用国外的手机号进行注册,注意注册过程中要将网络环境切换成国外ip。
 如何利用ChatGPT和Python实现用户意图识别功能
Oct 27, 2023 am 09:04 AM
如何利用ChatGPT和Python实现用户意图识别功能
Oct 27, 2023 am 09:04 AM
如何利用ChatGPT和Python实现用户意图识别功能引言:在当今的数字化时代,人工智能技术逐渐成为各个领域中不可或缺的一部分。其中,自然语言处理(NaturalLanguageProcessing,NLP)技术的发展使得机器能够理解和处理人类语言。ChatGPT(Chat-GeneratingPretrainedTransformer)是一种基于
 如何使用ChatGPT PHP构建智能客服机器人
Oct 28, 2023 am 09:34 AM
如何使用ChatGPT PHP构建智能客服机器人
Oct 28, 2023 am 09:34 AM
如何使用ChatGPTPHP构建智能客服机器人引言:随着人工智能技术的发展,机器人在客服领域的应用越来越广泛。使用ChatGPTPHP构建智能客服机器人,可以帮助企业提供更高效、更个性化的客户服务。本文将介绍如何使用ChatGPTPHP构建智能客服机器人,并提供具体的代码示例。一、安装ChatGPTPHP要使用ChatGPTPHP构建智能客服机器人
 ChatGPT和Python的完美结合:打造实时聊天机器人
Oct 28, 2023 am 08:37 AM
ChatGPT和Python的完美结合:打造实时聊天机器人
Oct 28, 2023 am 08:37 AM
ChatGPT和Python的完美结合:打造实时聊天机器人导言:随着人工智能技术的快速发展,聊天机器人在各个领域中扮演着越来越重要的角色。聊天机器人可以帮助用户提供即时且个性化的帮助,同时也可以为企业提供高效的客户服务。本文将介绍如何使用OpenAI的ChatGPT模型和Python语言相结合,打造一个实时聊天机器人,并提供具体的代码示例。一、ChatGPT
