

用 Python 实现十大经典排序算法


10种经典排序算法包括冒泡排序、选择排序、快速排序、归并排序、堆排序、插入排序、希尔排序、计数排序、桶排序、基数排序等。
当然,还有一些其他的排序算法,大家可以继续去研究下。
01冒泡排序
冒泡排序(Bubble Sort)是一种比较简单的排序算法,它重复地走访过要排序的元素,依次比较相邻两个元素,如果它们的顺序错误就把他们调换过来,直到没有元素再需要交换,排序完成。
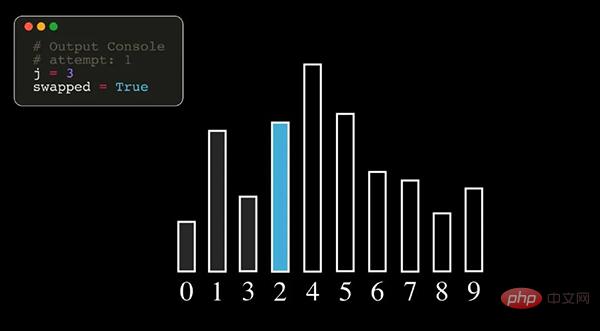
注:上图中,数字表示的是数据序列原始的索引号。
算法过程
- 比较相邻的元素,如果前一个比后一个大,就把它们两个对调位置。
- 对排序数组中每一对相邻元素做同样的工作,直到全部完成,此时最后的元素将会是本轮排序中最大的数。
- 对剩下的元素继续重复以上的步骤,直到没有任何一个元素需要比较。
冒泡排序每次找出一个最大的元素,因此需要遍历 n-1 次 (n为数据序列的长度)。
算法特点
什么时候最快(Best Cases):当输入的数据已经是正序时。
什么时候最慢(Worst Cases):当输入的数据是反序时。
Python代码
def bubble_sort(lst): n = len(lst) for i in range(n): for j in range(1, n - i): if lst[j - 1] > lst[j]: lst[j - 1], lst[j] = lst[j], lst[j - 1] return lst
02选择排序
选择排序原理
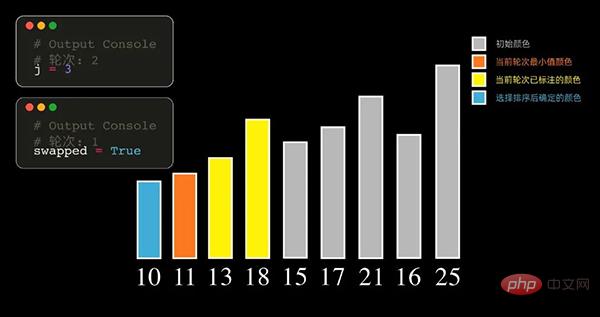
选择排序(Selection Sort)的原理,每一轮从待排序的记录中选出最小的元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。得到数值从小到达排序的数据序列。
也可以每一轮找出数值最大的元素,这样的话,排序完毕后的数组最终是从大到小排列。
选择排序每次选出最小(最大)的元素,因此需要遍历 n-1 次。
Python代码
def selection_sort(lst): for i in range(len(lst) - 1): min_index = i for j in range(i + 1, len(lst)): if lst[j] < lst[min_index]: min_index = j lst[i], lst[min_index] = lst[min_index], lst[i] return lst
03快速排序
快速排序(Quick Sort),是在上世纪60年代,由美国人东尼·霍尔提出的一种排序方法。这种排序方式,在当时已经是非常快的一种排序了。因此在命名上,才将之称为“快速排序”。
算法过程
- 先从数据序列中取出一个数作为基准数(baseline,习惯取第一个数)。
- 分区过程,将比基准数小的数全放到它的左边,大于或等于它的数全放到它的右边。
- 再对左右区间递归(recursive)重复第二步,直到各区间只有一个数。
因为数据序列之间的顺序都是固定的。最后将这些子序列一次组合起来,整体的排序就完成了。
如下图,对于数据序列,先取第一个数据 15为基准数,将比 15 小的数放在左边,比 15 大(大于或等于)的数放在右边
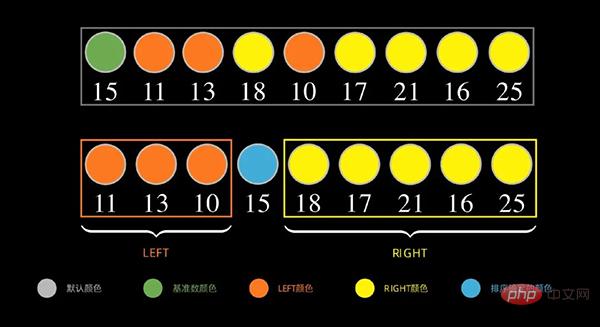
接下来,对于左边部分,重复上面的步骤,如下图,取左边序列的第一个数据 11 为基准数,将比 11 小的数放在左边,比 11 大(大于或等于)的数放在右边。
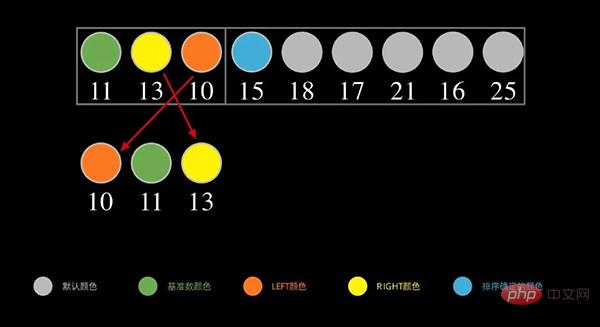
继续递归重复上述过程,直到每个区间只有一个数。这样就会完成排序
Python代码
def quick_sort(lst): n = len(lst) if n <= 1: return lst baseline = lst[0] left = [lst[i] for i in range(1, len(lst)) if lst[i] < baseline] right = [lst[i] for i in range(1, len(lst)) if lst[i] >= baseline] return quick_sort(left) + [baseline] + quick_sort(right)
04归并排序
算法思想
归并排序(Merge Sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法的一个非常典型的应用,归并排序将两个已经有序的子序列合并成一个有序的序列。
算法流程
主要两步(拆分,合并)
- 步骤1:进行序列拆分,一直拆分到只有一个元素;
- 步骤2:拆分完成后,开始递归合并。
思路:假设我们有一个没有排好序的序列,那么我们首先使用拆分的方法将这个序列分割成一个个已经排好序的子序列(直到剩下一个元素)。然后再利用归并方法将一个个有序的子序列合并成排好序的序列。
图解算法
拆分
对于数据序列 [15,11,13,18,10] ,我们从首先从数据序列的中间位置开始拆分,中间位置的设置为
首次拆分如下:
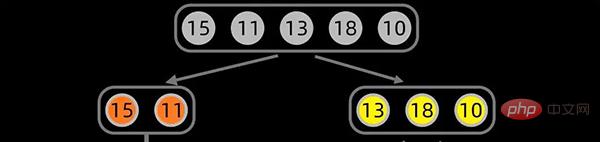
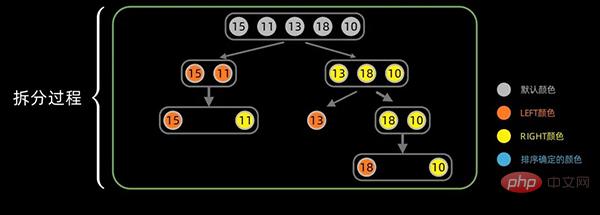
第一次拆分后,依次对子序列进行拆分,拆分过程如下:
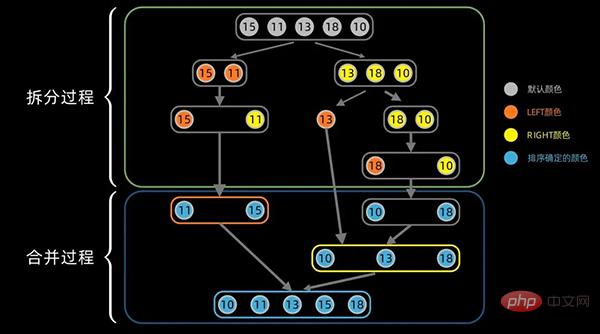
合并
合并过程中,对于左右分区以及其子区间,递归使用合并方法。先从左边最小的子区间开始,对于每个区间,依次将最小的数据放在最左边,然后对右边区间也执行同样的操作。
合并过程的完整图示如下:
Python代码
def merge_sort(lst): def merge(left,right): i = 0 j = 0 result = [] while i < len(left) and j < len(right): if left[i] <= right[j]: result.append(left[i]) i += 1 else: result.append(right[j]) j += 1 result = result + left[i:] + right[j:] return result n = len(lst) if n <= 1: return lst mid = n // 2 left = merge_sort(lst[:mid]) right = merge_sort(lst[mid:]) return merge(left,right)
05堆排序
要理解堆排序(Heap Sort)算法,首先要知道什么是“堆”。
堆的定义
对于 n 个元素的数据序列
,当且仅当满足下列情形之一时,才称之为 堆:
情形1:
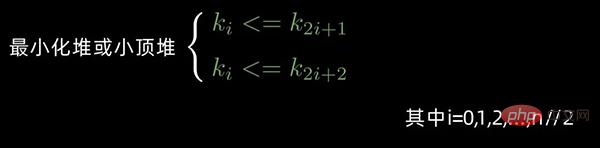
情形2:
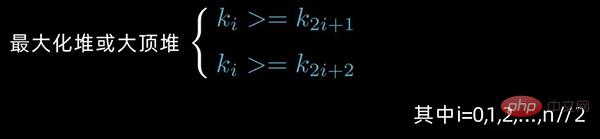
若序列
是堆,则堆顶元素必为序列中n个元素的最小值或最大值。
小顶堆如下图所示:
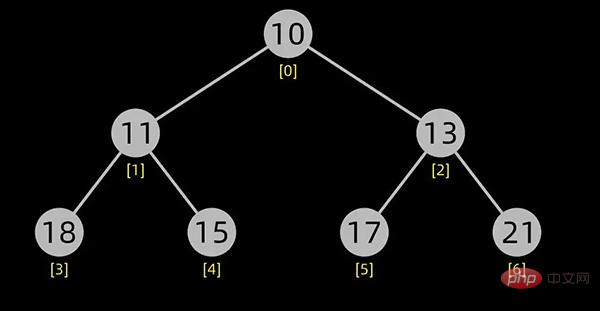
小顶堆
大顶堆如下图所示:
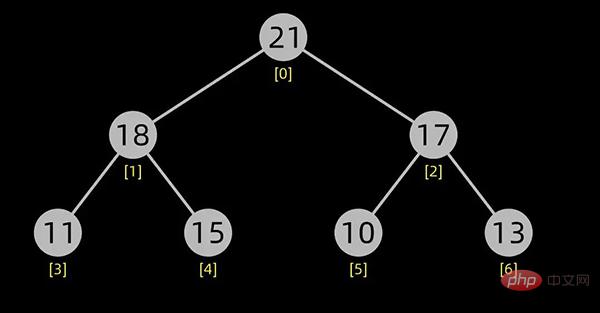
大顶堆
若在输出堆顶的最小值(或最大值)之后,使得剩余n-1个元素的序列重又建成一个堆,则得到n个元素的次小值(或次大值)。如此反复执行,便能得到一个有序序列,这个过程称之为 堆排序。
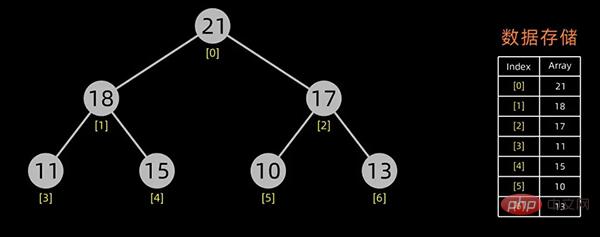
堆的存储
一般用数组来表示堆,若根结点存在序号 0 处, i 结点的父结点下标就为 (i-1)/2。i 结点的左右子结点下标分别为 2*i+1和 2*i+2 。
对于上面提到的小顶堆和大顶堆,其数据存储情况如下:
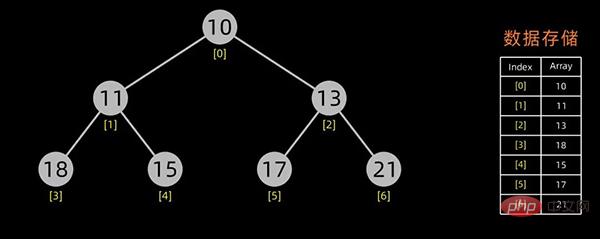
小顶堆
大顶堆
每幅图的右边为其数据存储结构,左边为其逻辑结构。
堆排序
实现堆排序需要解决两个问题:
- 如何由一个无序序列建成一个堆?
- 如何在输出堆顶元素之后,调整剩余元素成为一个新的堆?
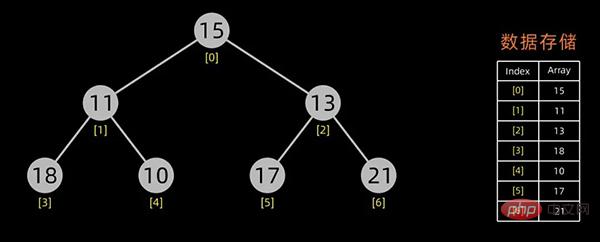
堆的初始化
第一个问题实际上就是堆的初始化,下面来阐述下如何构造初始堆,假设初始的数据序列如下:

咱们首先需要将其以树形结构来展示,如下:
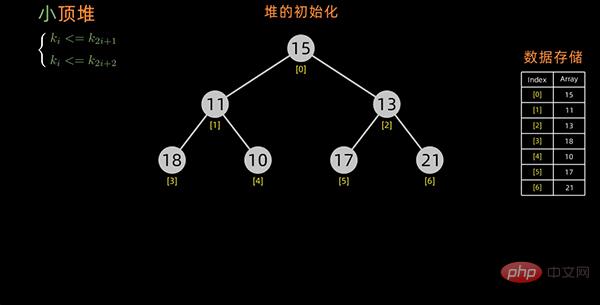
初始化堆的时候是对所有的非叶子结点进行筛选。
最后一个非终端元素的下标是 [n/2] 向下取整,所以筛选只需要从第 [n/2] 向下取整个元素开始,从后往前进行调整。
从最后一个非叶子结点开始,每次都是从父结点、左边子节点、右边子节点中进行比较交换,交换可能会引起子结点不满足堆的性质,所以每次交换之后需要重新对被交换的子结点进行调整。
以小顶堆为例,构造初始堆的过程如下:
进行堆排序
有了初始堆之后就可以进行排序了。
堆排序是一种选择排序。建立的初始堆为初始的无序区。
排序开始,首先输出堆顶元素(因为它是最值),将堆顶元素和最后一个元素交换,这样,第n个位置(即最后一个位置)作为有序区,前n-1个位置仍是无序区,对无序区进行调整,得到堆之后,再交换堆顶和最后一个元素,这样有序区长度变为2。。。
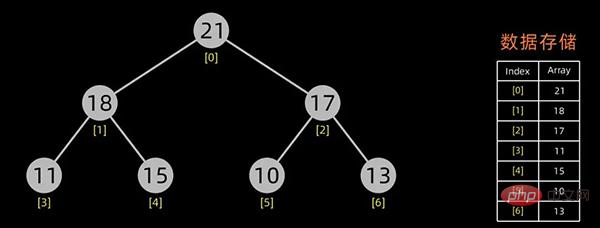
大顶堆
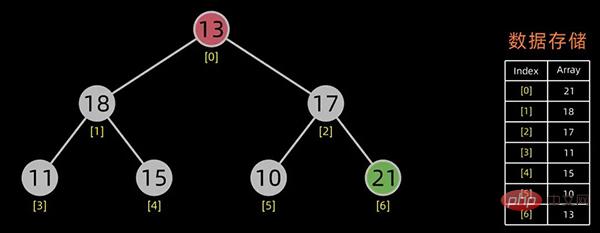
交换堆顶元素和最后的元素
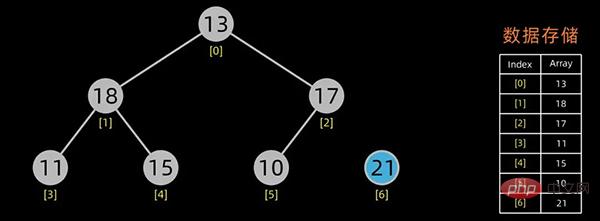
无序区-1,有序区+1
不断进行此操作,将剩下的元素重新调整为堆,然后输出堆顶元素到有序区。每次交换都导致无序区-1,有序区+1。不断重复此过程直到有序区长度增长为n-1,排序完成。
Python代码
def heap_sort(lst): def adjust_heap(lst, i, size): left_index = 2 * i + 1 right_index = 2 * i + 2 largest_index = i if left_index < size and lst[left_index] > lst[largest_index]: largest_index = left_index if right_index < size and lst[right_index] > lst[largest_index]: largest_index = right_index if largest_index != i: lst[largest_index], lst[i] = lst[i], lst[largest_index] adjust_heap(lst, largest_index, size) def built_heap(lst, size): for i in range(len(lst)//2)[::-1]: adjust_heap(lst, i, size) size = len(lst) built_heap(lst, size) for i in range(len(lst))[::-1]: lst[0], lst[i] = lst[i], lst[0] adjust_heap(lst, 0, i) return lst
06插入排序
插入排序(Insertion Sort)就是每一步都将一个需要排序的数据按其大小插入到已经排序的数据序列中的适当位置,直到全部插入完毕。
插入排序如同打扑克牌一样,每次将后面的牌插到前面已经排好序的牌中。

Python代码
def insertion_sort(lst): for i in range(len(lst) - 1): cur_num, pre_index = lst[i+1], i while pre_index >= 0 and cur_num < lst[pre_index]: lst[pre_index + 1] = lst[pre_index] pre_index -= 1 lst[pre_index + 1] = cur_num return lst
07希尔排序
基本原理
希尔排序(Shell Sort)是插入排序的一种更高效率的实现。
希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。
这里以动态间隔序列为例来描述。初始间隔(gap值)为数据序列长度除以2取整,后续间隔以 前一个间隔数值除以2取整为循环,直到最后一个间隔值为 1 。
对于下面这个数据序列,初始间隔数值为5
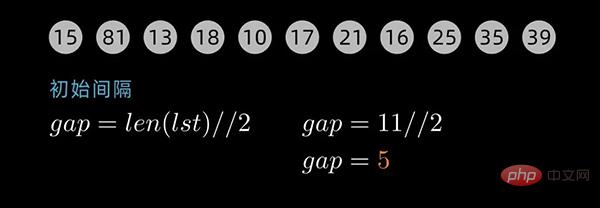
先将数据序列按间隔进行子序列分组,第一个子序列的索引为[0,5,10],这里分成了5组。

为方便大家区分不同的子序列,对同一个子序列标注相同的颜色,分组情况如下:
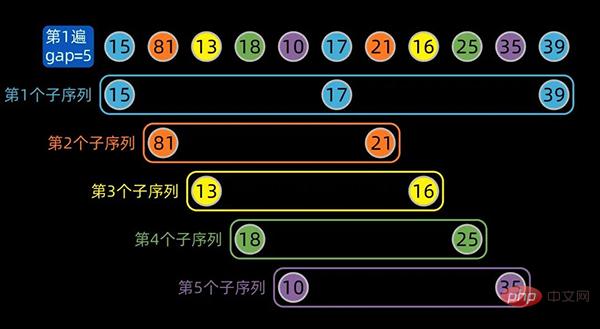
分组结束后,子序列内部进行插入排序,gap为5的子序列内部排序后如下:
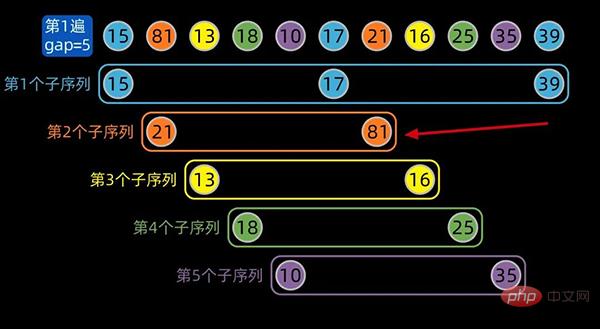

注:红色箭头标注的地方,是子序列内部排序后的状态
接下来选取第二个间隔值,按照间隔值进行子序列分组,同样地,子序列内部分别进行插入排序;
如果数据序列比较长,则会选取第3个、第4个或者更多个间隔值,重复上述的步骤。
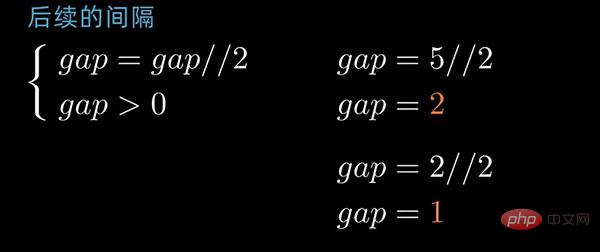
gap为2的排序情况前后对照如下:

最后一个间隔值为1,这一次相当于简单的插入排序。但是经过前几次排序,序列已经基本有序,因此最后一次排序时间效率就提高了很多。

Python代码
def shell_sort(lst): n = len(lst) gap = n // 2 while gap > 0: for i in range(gap, n): for j in range(i, gap - 1, -gap): if lst[j] < lst[j - gap]: lst[j], lst[j - gap] = lst[j - gap], lst[j] else: break gap //= 2 return lst
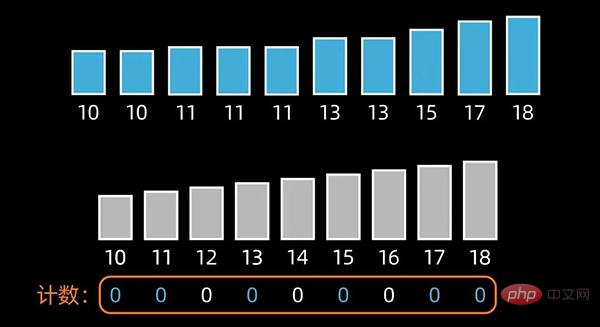
08计数排序
基本原理
计数排序(Counting Sort)的核心在于将输入的数据值转化为键,存储在额外开辟的数组空间中。计数排序要求输入的数据必须是有确定范围的整数。
算法的步骤如下:
先找出待排序的数组中最大和最小的元素,新开辟一个长度为 最大值-最小值+1 的数组;
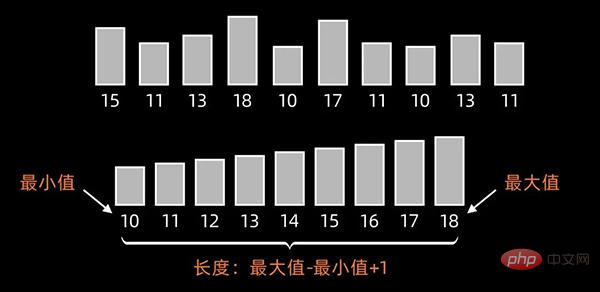
然后,统计原数组中每个元素出现的次数,存入到新开辟的数组中;
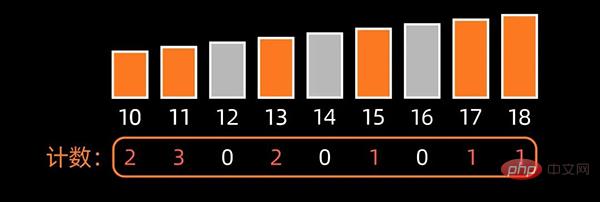
接下来,根据每个元素出现的次数,按照新开辟数组中从小到大的秩序,依次填充到原来待排序的数组中,完成排序。
Python代码
def counting_sort(lst): nums_min = min(lst) bucket = [0] * (max(lst) + 1 - nums_min) for num in lst: bucket[num - nums_min] += 1 i = 0 for j in range(len(bucket)): while bucket[j] > 0: lst[i] = j + nums_min bucket[j] -= 1 i += 1 return lst
09桶排序
基本思想
简单来说,桶排序(Bucket Sort)就是把数据分组,放在一个个的桶中,对每个桶里面的数据进行排序,然后将桶进行数据合并,完成桶排序。
该算法分为四步,包括划分桶、数据入桶、桶内排序、数据合并。
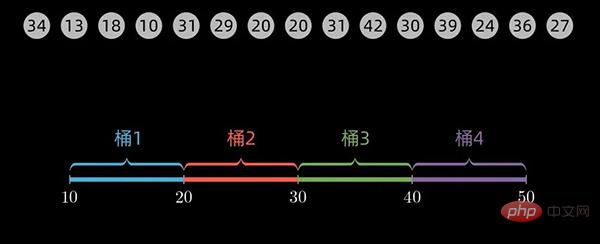
桶的划分过程
这里详细介绍下桶的划分过程。
对于一个数值范围在10到 49范围内的数组,我们取桶的大小为10 (defaultBucketSize = 10),则第一个桶的范围为 10到20,第二个桶的数据范围是20到30,依次类推。最后,我们一共需要4个桶来放入数据。

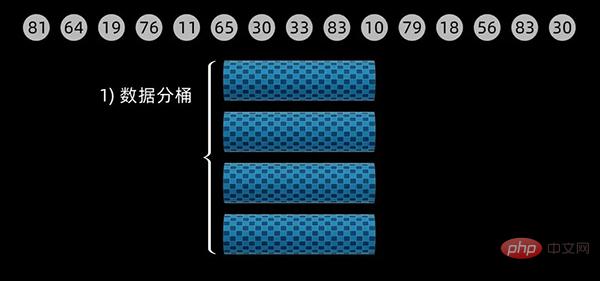
排序过程
对于下面这个数据序列,初始设定桶的大小为 20 (defaultBucketSize = 20),经计算,一共需要4个桶来放入数据。
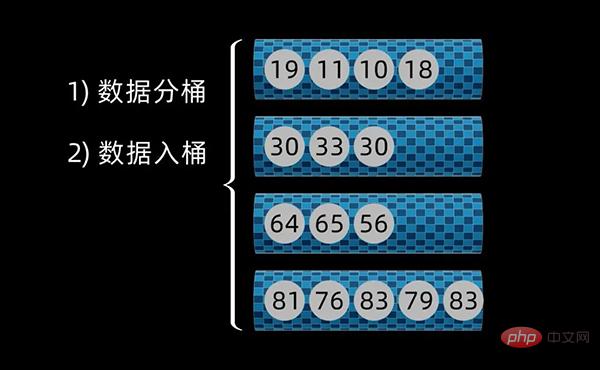
然后将原始数组按数值大小放入到对应的桶中,完成数据分组。
对于桶内的数据序列,这时可以用冒泡排序、选择排序等多种排序算法来对数据进行排序。这些算法,在之前的视频里已有介绍,大家可以去了解下。
这里,我选用 冒泡排序 来对桶内数据进行排序。
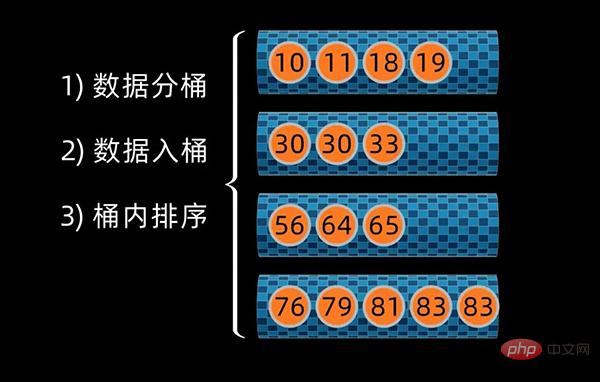
桶内排序完成后,将数据按桶的顺序进行合并,这样就得到所有数值排好序的数据序列了

Python代码
def bucket_sort(lst, defaultBucketSize=4): maxVal, minVal = max(lst), min(lst) bucketSize = defaultBucketSize bucketCount = (maxVal - minVal) // bucketSize + 1 buckets = [[] for i in range(bucketCount)] for num in lst: buckets[(num - minVal) // bucketSize].append(num) lst.clear() for bucket in buckets: bubble_sort(bucket) lst.extend(bucket) return lst
10基数排序
基数排序(radix sort)属于“分配式排序”(distribution sort),它是透过键值的部份信息,将要排序的元素分配至某些“桶”中,以达到排序的作用。
基数排序适用于所有元素均为正整数的数组。
基本思想
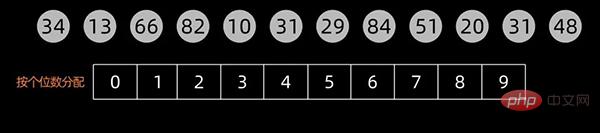
排序过程分为“分配”和“收集”。
排序过程中,将元素分层为多个关键码进行排序(一般按照数值的个位、十位、百位、…… 进行区分),多关键码排序按照从最主位关键码到最次位关键码或从最次位到最主位关键码的顺序逐次排序。
基数排序的方式可以采用最低位优先LSD(Least sgnificant digital)法或最高位优先MSD(Most sgnificant digital)法,LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
LSD的基数排序适用于位数小的数列,如果位数多的话,使用MSD的效率会比较好,MSD的方式恰与LSD相反,是由高位数为基底开始进行分配,其他的演算方式则都相同。
算法流程
这里以最低位优先LSD为例。
先根据个位数的数值,在扫描数值时将它们分配至编号0到9的桶中,然后将桶子中的数值串接起来。
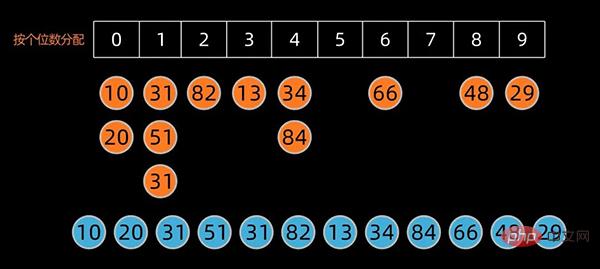
将这些桶子中的数值重新串接起来,成为新的序列,接着再进行一次分配,这次是根据十位数来分配。

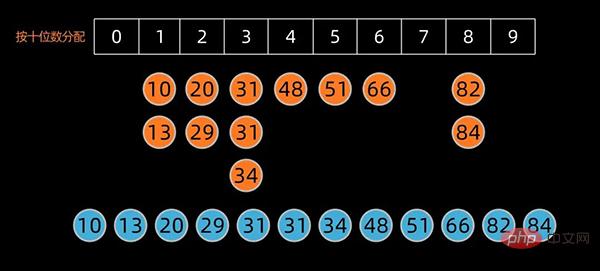
如果排序的对象有三位数以上,则持续进行以上的动作直至最高位数为止。
Python代码
# LSD Radix Sort def radix_sort(lst): mod = 10 div = 1 mostBit = len(str(max(lst))) buckets = [[] for row in range(mod)] while mostBit: for num in lst: buckets[num // div % mod].append(num) i = 0 for bucket in buckets: while bucket: lst[i] = bucket.pop(0) i += 1 div *= 10 mostBit -= 1 return lst
11小结
以上就是用 Python 来实现10种经典排序算法的相关内容。
对于这些排序算法的实现,代码其实并不是最主要的,重要的是需要去理解各种算法的基本思想、基本原理以及其内部的实现过程。
对于每种算法,用其他编程语言同样是可以去实现的。
并且,对于同一种算法,即使只用 Python 语言,也有多种不同的代码方式可以来实现,但其基本原理是一致的。
以上是用 Python 实现十大经典排序算法的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 PHP和Python:代码示例和比较
Apr 15, 2025 am 12:07 AM
PHP和Python:代码示例和比较
Apr 15, 2025 am 12:07 AM
PHP和Python各有优劣,选择取决于项目需求和个人偏好。1.PHP适合快速开发和维护大型Web应用。2.Python在数据科学和机器学习领域占据主导地位。
 Python vs. JavaScript:社区,图书馆和资源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社区,图书馆和资源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社区、库和资源方面的对比各有优劣。1)Python社区友好,适合初学者,但前端开发资源不如JavaScript丰富。2)Python在数据科学和机器学习库方面强大,JavaScript则在前端开发库和框架上更胜一筹。3)两者的学习资源都丰富,但Python适合从官方文档开始,JavaScript则以MDNWebDocs为佳。选择应基于项目需求和个人兴趣。
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
在 VS Code 中,可以通过以下步骤在终端运行程序:准备代码和打开集成终端确保代码目录与终端工作目录一致根据编程语言选择运行命令(如 Python 的 python your_file_name.py)检查是否成功运行并解决错误利用调试器提升调试效率
 Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python在自动化、脚本编写和任务管理中表现出色。1)自动化:通过标准库如os、shutil实现文件备份。2)脚本编写:使用psutil库监控系统资源。3)任务管理:利用schedule库调度任务。Python的易用性和丰富库支持使其在这些领域中成为首选工具。
 vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
VS Code 扩展存在恶意风险,例如隐藏恶意代码、利用漏洞、伪装成合法扩展。识别恶意扩展的方法包括:检查发布者、阅读评论、检查代码、谨慎安装。安全措施还包括:安全意识、良好习惯、定期更新和杀毒软件。
 vscode是什么 vscode是干什么用的
Apr 15, 2025 pm 06:45 PM
vscode是什么 vscode是干什么用的
Apr 15, 2025 pm 06:45 PM
VS Code 全称 Visual Studio Code,是一个由微软开发的免费开源跨平台代码编辑器和开发环境。它支持广泛的编程语言,提供语法高亮、代码自动补全、代码片段和智能提示等功能以提高开发效率。通过丰富的扩展生态系统,用户可以针对特定需求和语言添加扩展程序,例如调试器、代码格式化工具和 Git 集成。VS Code 还包含直观的调试器,有助于快速查找和解决代码中的 bug。
 centos如何安装nginx
Apr 14, 2025 pm 08:06 PM
centos如何安装nginx
Apr 14, 2025 pm 08:06 PM
CentOS 安装 Nginx 需要遵循以下步骤:安装依赖包,如开发工具、pcre-devel 和 openssl-devel。下载 Nginx 源码包,解压后编译安装,并指定安装路径为 /usr/local/nginx。创建 Nginx 用户和用户组,并设置权限。修改配置文件 nginx.conf,配置监听端口和域名/IP 地址。启动 Nginx 服务。需要注意常见的错误,如依赖问题、端口冲突和配置文件错误。性能优化需要根据具体情况调整,如开启缓存和调整 worker 进程数量。
