

人类没有足够的高质量语料给AI学了,2026年就用尽,网友:大型人类文本生成项目启动!

AI胃口太大,人类的语料数据已经不够吃了。
来自Epoch团队的一篇新论文表明,AI不出5年就会把所有高质量语料用光。

要知道,这可是把人类语言数据增长率考虑在内预测出的结果,换而言之,这几年人类新写的论文、新编的代码,哪怕全都喂给AI也不够。
照这么发展下去,依赖高质量数据提升水平的语言大模型,很快就要迎来瓶颈。
已经有网友坐不住了:
这太荒谬了。人类无需阅读互联网所有内容,就能高效训练自己。
我们需要更好的模型,而不是更多的数据。
还有网友调侃,都这样了不如让AI吃自己吐的东西:
可以把AI自己生成的文本当成低质量数据喂给AI。

让我们来看看,人类剩余的数据还有多少?
文本和图像数据“存货”如何?
论文主要针对文本和图像两类数据进行了预测。
首先是文本数据。
数据的质量通常有好有坏,作者们根据现有大模型采用的数据类型、以及其他数据,将可用文本数据分成了低质量和高质量两部分。
高质量语料,参考了Pile、PaLM和MassiveText等大型语言模型所用的训练数据集,包括维基百科、新闻、GitHub上的代码、出版书籍等。
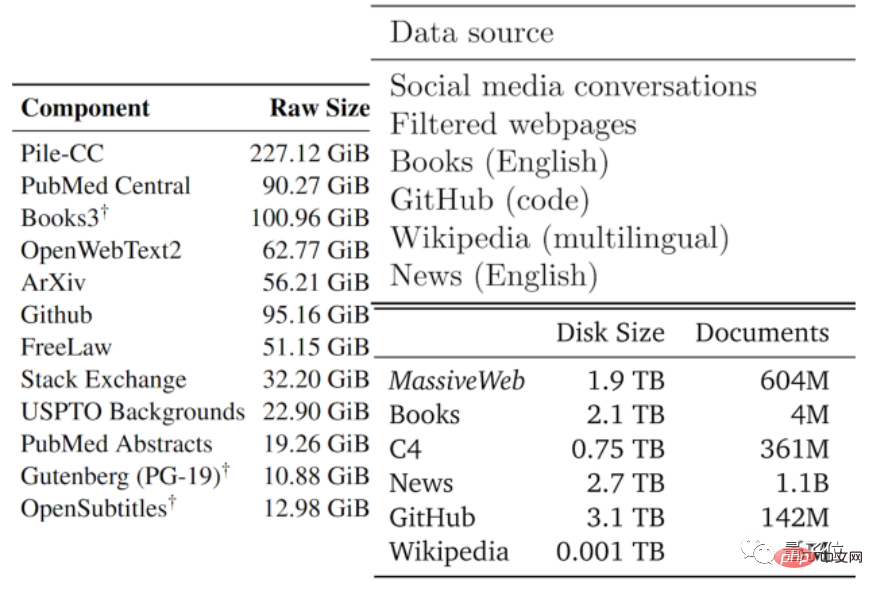
低质量语料,则来源于Reddit等社交媒体上的推文、以及非官方创作的同人小说(fanfic)等。
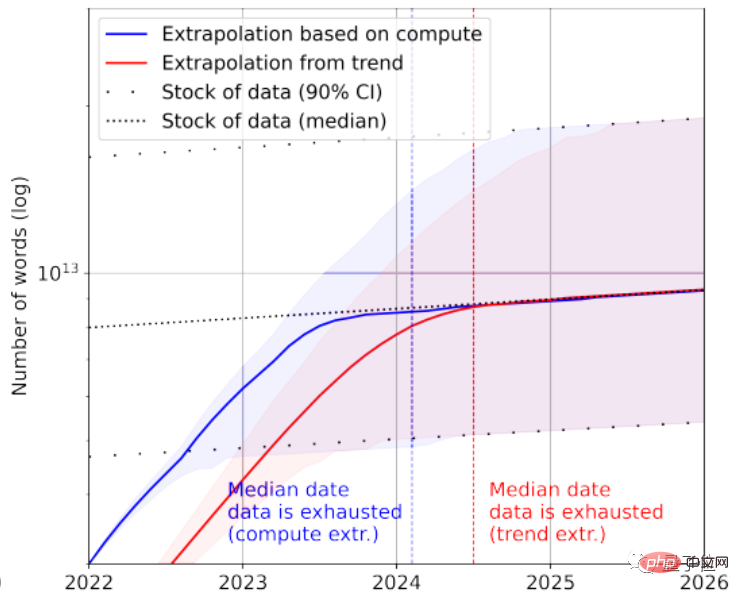
根据统计,高质量语言数据存量只剩下约4.6×10^12~1.7×10^13个单词,相比当前最大的文本数据集大了不到一个数量级。
结合增长率,论文预测高质量文本数据会在2023~2027年间被AI耗尽,预估节点在2026年左右。
看起来实在有点快……
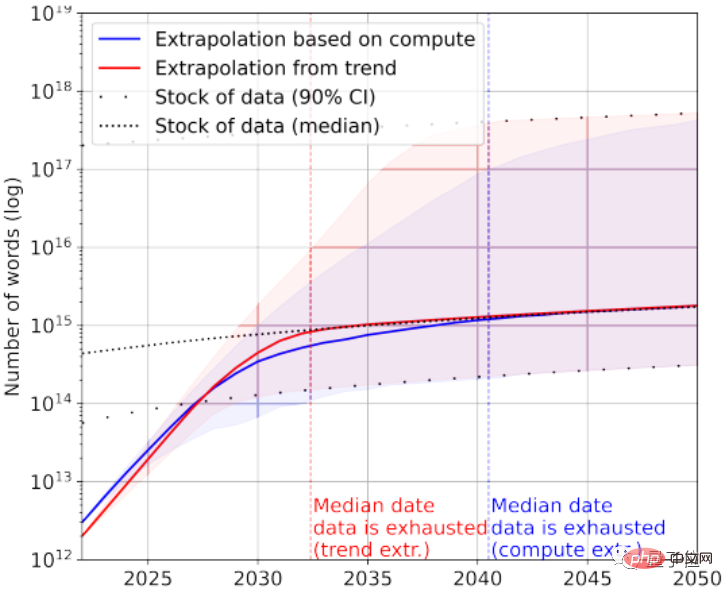
当然,可以再加上低质量文本数据来救急。根据统计,目前文本数据整体存量还剩下7×10^13~7×10^16个单词,比最大的数据集大1.5~4.5个数量级。
如果对数据质量要求不高,那么AI会在2030年~2050年之间才用完所有文本数据。
再看看图像数据,这里论文没有区分图像质量。
目前最大的图像数据集拥有3×10^9张图片。
据统计,目前图片总量约有8.11×10^12~2.3×10^13张,比最大的图像数据集大出3~4个数量级。
论文预测AI会在2030~2070年间用完这些图片。
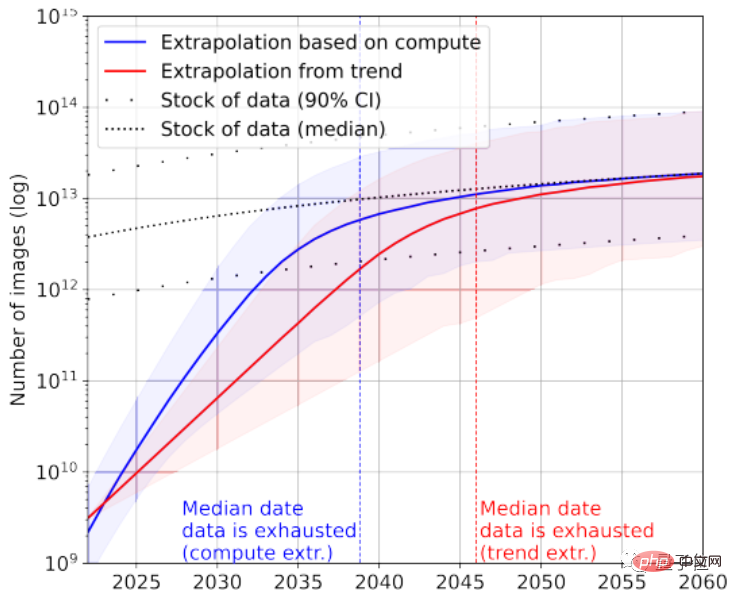
显然,大语言模型比图像模型面临着更紧张的“缺数据”情况。
那么这一结论是如何得出的呢?
计算网民日均发文量得出
论文从两个角度,分别对文本图像数据生成效率、以及训练数据集增长情况进行了分析。
值得注意的是,论文统计的不都是标注数据,考虑到无监督学习比较火热,把未标注数据也算进去了。
以文本数据为例,大部分数据会从社交平台、博客和论坛生成。
为了估计文本数据生成速度,有三个因素需要考虑,即总人口、互联网普及率和互联网用户平均生成数据量。
例如,这是根据历史人口数据和互联网用户数量,估计得到的未来人口和互联网用户增长趋势:
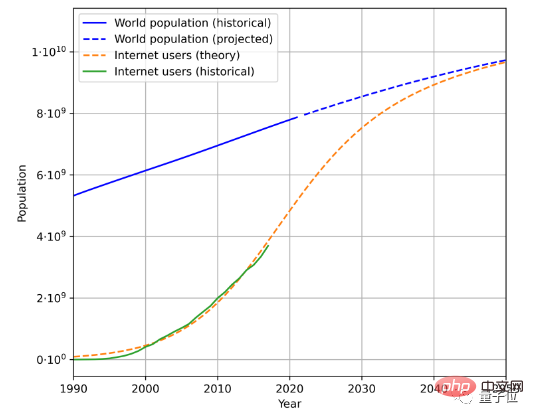
再结合用户生成的平均数据量,就能计算出生成数据的速率。(由于地理和时间变化复杂,论文简化了用户平均生成数据量计算方法)
根据这一方法,计算得出语言数据增长率在7%左右,然而这一增长率会随着时间延长逐渐下降。
预计到2100年,我们的语言数据增长率会降低到1%。
同样类似的方法分析图像数据,当前增长率在8%左右,然而到2100年图像数据增长率同样会放缓至1%左右。
论文认为,如果数据增长率没有大幅提高、或是出现新的数据来源,无论是靠高质量数据训练的图像还是文本大模型,都可能在某个阶段迎来瓶颈期。
对此有网友调侃,未来或许会有像科幻故事情节一样的事情发生:
人类为了训练AI,启动大型文本生成项目,大家为了AI拼命写东西。
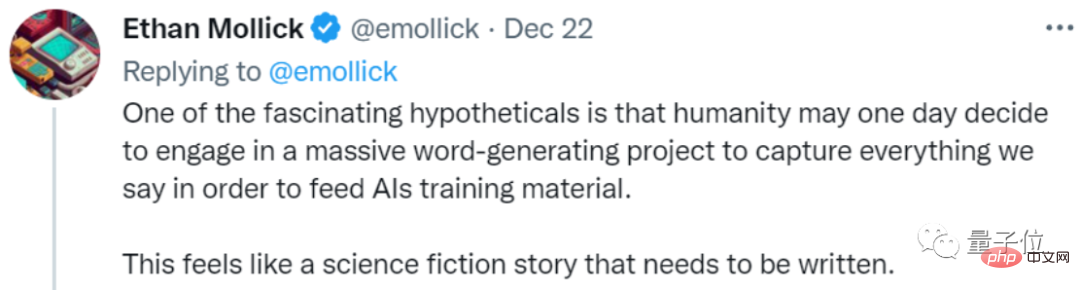
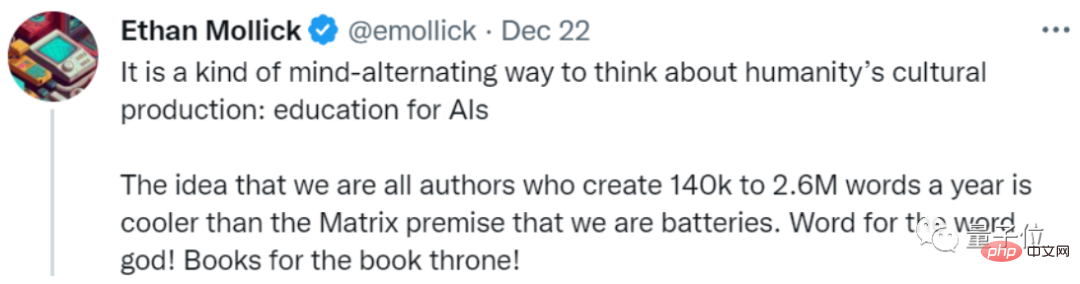
他称之为一种“对AI的教育”:
我们每年给AI送14万到260万单词量的文本数据,听起来似乎比人类当电池要更酷?
你觉得呢?
论文地址:https://arxiv.org/abs/2211.04325
参考链接:https://twitter.com/emollick/status/1605756428941246466
以上是人类没有足够的高质量语料给AI学了,2026年就用尽,网友:大型人类文本生成项目启动!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 分享PyCharm项目打包的简易方法
Dec 30, 2023 am 09:34 AM
分享PyCharm项目打包的简易方法
Dec 30, 2023 am 09:34 AM
简单易懂的PyCharm项目打包方法分享随着Python的流行,越来越多的开发者使用PyCharm作为Python开发的主要工具。PyCharm是功能强大的集成开发环境,它提供了许多方便的功能来帮助我们提高开发效率。其中一个重要的功能就是项目的打包。本文将介绍如何在PyCharm中简单易懂地打包项目,并提供具体的代码示例。为什么要打包项目?在Python开发
 AI攻克费马大定理?数学家放弃5年职业生涯,将100页证明变代码
Apr 09, 2024 pm 03:20 PM
AI攻克费马大定理?数学家放弃5年职业生涯,将100页证明变代码
Apr 09, 2024 pm 03:20 PM
费马大定理,即将被AI攻克?而且整件事最意味深长的地方在于,AI即将解决的费马大定理,正是为了证明AI无用。曾经,数学属于纯粹的人类智力王国;如今,这片疆土正被先进的算法所破译,所践踏。图片费马大定理,是一个「臭名昭著」的谜题,在几个世纪以来,一直困扰着数学家们。它在1993年被证明,而现在,数学家们有一个伟大计划:用计算机把证明过程重现。他们希望在这个版本的证明中,如果有任何逻辑上的错误,都可由计算机检查出来。项目地址:https://github.com/riccardobrasca/flt
 用于时间序列概率预测的分位数回归
May 07, 2024 pm 05:04 PM
用于时间序列概率预测的分位数回归
May 07, 2024 pm 05:04 PM
不要改变原内容的意思,微调内容,重写内容,不要续写。“分位数回归满足这一需求,提供具有量化机会的预测区间。它是一种统计技术,用于模拟预测变量与响应变量之间的关系,特别是当响应变量的条件分布命令人感兴趣时。与传统的回归方法不同,分位数回归侧重于估计响应变量变量的条件量值,而不是条件均值。”图(A):分位数回归分位数回归概念分位数回归是估计⼀组回归变量X与被解释变量Y的分位数之间线性关系的建模⽅法。现有的回归模型实际上是研究被解释变量与解释变量之间关系的一种方法。他们关注解释变量与被解释变量之间的关
 深入了解PyCharm:快速删除项目的方法
Feb 26, 2024 pm 04:21 PM
深入了解PyCharm:快速删除项目的方法
Feb 26, 2024 pm 04:21 PM
标题:深入了解PyCharm:删除项目的高效方式近年来,Python作为一种强大而灵活的编程语言,受到越来越多开发者的青睐。在Python项目的开发中,选择一个高效的集成开发环境至关重要。PyCharm作为一款功能强大的集成开发环境,为Python开发者提供了诸多便利的功能和工具,其中包括快速、高效地删除项目目录。下面将着重介绍如何使用PyCharm中的删除
 PyCharm实用技巧:将项目转换为可执行EXE文件
Feb 23, 2024 am 09:33 AM
PyCharm实用技巧:将项目转换为可执行EXE文件
Feb 23, 2024 am 09:33 AM
PyCharm是一款功能强大的Python集成开发环境,提供了丰富的开发工具和环境配置,让开发者能够更高效地编写和调试代码。在使用PyCharm进行Python项目开发的过程中,有时候我们需要将项目打包成可执行的EXE文件,以便在没有安装Python环境的计算机上运行。本文将介绍如何使用PyCharm将项目转换为可执行的EXE文件,同时给出具体的代码示例。首
 SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准
Feb 20, 2024 am 11:48 AM
SIMPL:用于自动驾驶的简单高效的多智能体运动预测基准
Feb 20, 2024 am 11:48 AM
原标题:SIMPL:ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving论文链接:https://arxiv.org/pdf/2402.02519.pdf代码链接:https://github.com/HKUST-Aerial-Robotics/SIMPL作者单位:香港科技大学大疆论文思路:本文提出了一种用于自动驾驶车辆的简单高效的运动预测基线(SIMPL)。与传统的以代理为中心(agent-cent
 制作 iPhone 上 iOS 17 提醒应用程序中的购物清单的方法
Sep 21, 2023 pm 06:41 PM
制作 iPhone 上 iOS 17 提醒应用程序中的购物清单的方法
Sep 21, 2023 pm 06:41 PM
如何在iOS17中的iPhone上制作GroceryList在“提醒事项”应用中创建GroceryList非常简单。你只需添加一个列表,然后用你的项目填充它。该应用程序会自动将您的商品分类,您甚至可以与您的伴侣或扁平伙伴合作,列出您需要从商店购买的东西。以下是执行此操作的完整步骤:步骤1:打开iCloud提醒事项听起来很奇怪,苹果表示您需要启用来自iCloud的提醒才能在iOS17上创建GroceryList。以下是它的步骤:前往iPhone上的“设置”应用,然后点击[您的姓名]。接下来,选择i
 如何使用MySQL数据库进行预测和预测分析?
Jul 12, 2023 pm 08:43 PM
如何使用MySQL数据库进行预测和预测分析?
Jul 12, 2023 pm 08:43 PM
如何使用MySQL数据库进行预测和预测分析?概述:预测和预测分析在数据分析中扮演着重要角色。MySQL作为一种广泛使用的关系型数据库管理系统,也可以用于预测和预测分析任务。本文将介绍如何使用MySQL进行预测和预测分析,并提供相关的代码示例。数据准备:首先,我们需要准备相关的数据。假设我们要进行销售预测,我们需要具有销售数据的表。在MySQL中,我们可以使用
