

在程序设计中,创建物体模块主要是通过生成对象来实现。当对象使用结束后,则会成为不再需要的模块进行销毁。
而在系统进行对象的生成与销毁过程中会大量的增加内存的消耗,同时对象的销毁往往会留下残留的信息,这样将会伴随内存泄露的问题存在。
在实际的程序开发过程中,往往需要生成和销毁大量重复的对象,这就使得内存泄漏产生的信息过多而无法被系统回收,从而占用系统更多的内存,而且生成物体过多时无法确定被什么模块实例化实现,对系统造成负担,不利于管理及后续操作,长此以往最终将导致程序变慢甚至崩溃。
对象池是存放了一批已经创建好的对象的池,它是一个用来维护对象的结构。当程序需要使用对象的时候,可以直接从池中获取该对象,而不是实例化一个新的对象。
在程序设计过程中,大部分人关注的往往只是对象的使用和效果的实现,实际上创建和使用之间还有一个初始化的过程,不过系统会将初始化和创建这两步结合在了一起,这样使得设计者忽略了系统创建和销毁对象这一过程对系统的影响。
通常来讲,一个对象的创建和销毁过程开销很小,可以忽略不计,但是如果一个程序中涉及到一种对象多次创建,并且创建时间比较长,那就会能很明显的感觉到这部分的消耗所造成的系统速度受限。
对象池可以看作是减少 GC 压力的首选方法,同时也是最简单的方法。
Pond 是一个 Python 中高效的通用对象池,具有性能好、内存占用小、命中率高的特点。基于近似统计的根据频率自动回收的能力,能够自动调整每个对象池的空闲对象数量。
因为目前 Python 目前没有比较好的、测试用例完备、代码注释完备、文档完善的对象池化库,同时目前的主流对象池库也没有比较智能的自动回收机制。
Pond 可能是 Python 中第一个社区公开的测试用例完整,覆盖率 90% 以上、代码注释完备、文档完善的对象池化库。
Pond 灵感来自于 Apache Commons Pool、Netty Recycler、HikariCP、Caffeine,集合了多家的优点。
其次 Pond 通过使用近似计数的方式以极小的内存空间统计每个对象池的使用频率,并且自动回收。
流量较为随机平均的情况下,默认策略和权重可以降低 48.85% 内存占用,借取命中率 100%。
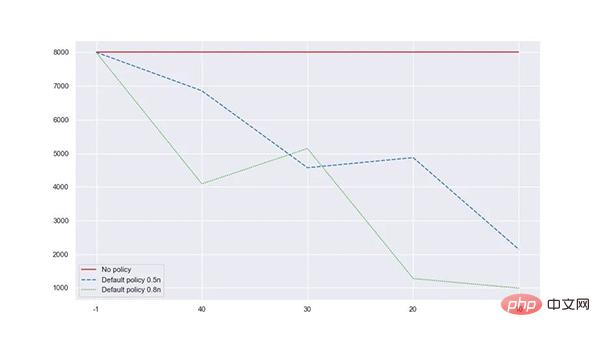
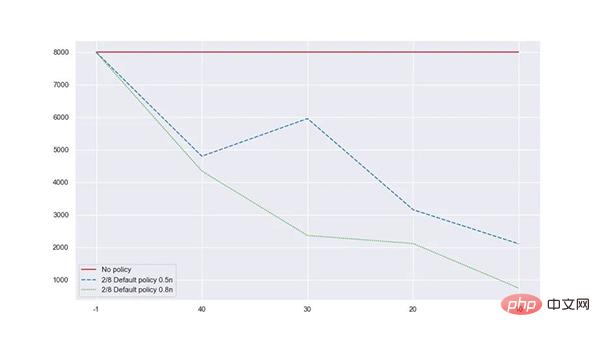
流量较为符合 2/8 定律的情况下,默认策略和权重可以降低 45.7% 内存占用, 借取命中率 100%。
Pond 主要由 FactoryDict、Counter、PooledObjectTree 三部分以及一个单独的回收线程构成。
使用 Pond 需要实现对象工厂 PooledObjectFactory,PooledObjectFactory 提供对象的创建、初始化、销毁、验证等操作,由 Pond 调用。
所以为了让对象池支持存放完全不同的对象,Pond 使用了一个字典来记录每个工厂类的名称和自己实现的工厂类的实例化对象。
每个 PooledObjectFactory 应该具备创建对象、销毁对象、验证对象是否还可用、重置对象四个功能。
比较特别的是 Pond 支持自动重置对象,因为某些场景下可能会存在对象中要先赋值进行传递,传递完又被回收的情况,为了避免污染建议这种场景下无比实现这个功能。
Counter 中保存了一个近似计数器。
PooleedObjectTree 是个字典,每个 key 对应着一个先进先出的队列,这些队列都是线程安全的。
每个队列中保存着多个 PooleedObject。PooledObejct 保存了创建时间、最后借出的时间以及实际需要的对象。
Pond 的借用和回收都是线程安全的。Python 的 queue 模块提供了一个适用于多线程编程的先进先出(FIFO)数据结构。它可以用来安全地在生产者和消费者线程之间传递消息或其他数据。
锁是调用者来处理的,所有多个线程能够安全且容易的使用同样的 Queue 实例工作。而 Pond 的借用和回收都是在操作 queue,所以基本可以认为是线程安全的。
在使用 Pond 借出一个对象时,会先检查想要借出的对象的种类是否已经在 PooledObjectTree 存在,如果存在会检查这个对象的对象池是否为空,如果为空会创建一个新的。
如果对象池中有多余的对象,会利用 queue 弹出一个对象并验证这个对象是否可用。如果不可用会自动调用所属的 Factory 清理销毁该对象,同时清理它在 Python 中的 GC 计数,让它更快被 GC 回收,不断拿取下一个直至有可用的。
如果这个对象可用,则会直接返回。当然无论是从对象池中取出对象还是新创建了一个对象,都会利用 Counter 增加一个计数。
回收一个对象时会判断目标对象池存不存在,如果存在会检查对象池是否已经满了,满了的话会自动销毁要归还的这个对象。
然后会检查这个对象是否已经被借出太长时间,如果超过了配置的最长时间同样会被清理掉。
自动回收时每隔一段时间,默认是 300 s,就会执行一次。自动清理不经常使用的对象池中的对象。
你可以先安装 Pond 的库并且在你的项目中引用。
pip install pondpond
from pond import Pond, PooledObjectFactory, PooledObject
首先你需要声明一个你想要放入的类型的对象的工厂类,比如下面的例子我们希望池化的对象是 Dog,所以我们先声明一个 PooledDogFactory 类,并且实现 PooledObjectFactory。
class Dog: name: str validate_result:bool = True class PooledDogFactory(PooledObjectFactory): def creatInstantce(self) -> PooledObject: dog = Dog() dog.name = "puppy" return PooledObject(dog) def destroy(self, pooled_object: PooledObject): del pooled_object def reset(self, pooled_object: PooledObject) -> PooledObject: pooled_object.keeped_object.name = "puppy" return pooled_object def validate(self, pooled_object: PooledObject) -> bool: return pooled_object.keeped_object.validate_result
接着你需要创建 Pond 的对象:
pond = Pond(borrowed_timeout=2, time_between_eviction_runs=-1, thread_daemon=True, eviction_weight=0.8)
Pond 可以传递一些参数进去,分别代表:
borrowed_timeout :单位为秒,借出对象的最长期限,超过期限的对象归还时会自动销毁不会放入对象池。
time_between_eviction_runs :单位为秒,自动回收的间隔时间。
thread_daemon :守护线程,如果为 True,自动回收的线程会随着主线程关闭而关闭。
eviction_weight :自动回收时权重,会将这个权重与最大使用频次想乘,使用频次小于这个值的对象池中的对象都会进入清理步骤。
实例化工厂类:
factory = PooledDogFactory(pooled_maxsize=10, least_one=False)
所有继承了 PooledObjectFactory 都会自带构造函数,可以传递 pooled_maxsize 和 least_one 两个参数。
pooled_maxsize:这个工厂类生成出的对象的对象池的最大能放置的数量。
least_one:如果为 True,在进入自动清理时,这个工厂类生成出的对象的对象池会至少保留一个对象。
向 Pond 注册这个工厂对象,默认会使用 factory 的类名作为 PooledObjectTree 的 key :
pond.register(factory)
当然你也可以自定义它的名字,名字会作为 PooledObjectTree 的 key:
pond.register(factory, name="PuppyFactory")
注册成功后,Pond 会自动根据 factory 中设置的 pooled_maxsize 自动开始创建对象直至填满这个对象池。
借用和归还对象:
pooled_object: PooledObject = pond.borrow(factory) dog: Dog = pooled_object.use() pond.recycle(pooled_object, factory)
当然你可以用名字来进行借用和归还:
pooled_object: PooledObject = pond.borrow(name="PuppyFactory") dog: Dog = pooled_object.use() pond.recycle(pooled_object, name="PuppyFactory")
完全清理一个对象池:
pond.clear(factory)
通过名字清理一个对象池:
pond.clear(name="PuppyFactory")
正常情况下,你只需要使用上面的这些方法,生成对象和回收对象都是全自动的。
以上是最新开源:高效的 Python 通用对象池化库的详细内容。更多信息请关注PHP中文网其他相关文章!





















