

九个超级实用的数据科学Python库

在本文中,我们会研究一些用于数据科学任务的 Python 库,而不是常见的比如 panda、scikit-learn 和 matplotlib 等的库。尽管像 panda 和 scikit-learn 这样的库,是在机器学习任务中经常出现的,但是了解这个领域中的其它 Python 产品总是很有好处的。
一、Wget
从网络上提取数据是数据科学家的重要任务之一。Wget 是一个免费的实用程序,可以用于从网络上下载非交互式的文件。它支持 HTTP、HTTPS 和 FTP 协议,以及通过 HTTP 的代理进行文件检索。由于它是非交互式的,即使用户没有登录,它也可以在后台工作。所以下次当你想要下载一个网站或者一个页面上的所有图片时,wget 可以帮助你。
安装:
$ pip install wget
例子:
import wget url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3' filename = wget.download(url) 100% [................................................] 3841532 / 3841532 filename 'razorback.mp3'
二、Pendulum
对于那些在 python 中处理日期时间时会感到沮丧的人来说,Pendulum 很适合你。它是一个简化日期时间操作的 Python 包。它是 Python 原生类的简易替代。请参阅文档深入学习。
安装:
$ pip install pendulum
例子:
import pendulum dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto') dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver') print(dt_vancouver.diff(dt_toronto).in_hours()) 3
三、imbalanced-learn
可以看出,当每个类的样本数量基本相同时,大多数分类算法的效果是最好的,即需要保持数据平衡。但现实案例中大多是不平衡的数据集,这些数据集对机器学习算法的学习阶段和后续预测都有很大影响。幸运的是,这个库就是用来解决此问题的。它与 scikit-learn 兼容,是 scikit-lear-contrib 项目的一部分。下次当你遇到不平衡的数据集时,请尝试使用它。
安装:
$ pip install -U imbalanced-learn # 或者 $ conda install -c conda-forge imbalanced-learn
例子:
使用方法和例子请参考文档。
四、FlashText
在 NLP 任务中,清理文本数据往往需要替换句子中的关键字或从句子中提取关键字。通常,这种操作可以使用正则表达式来完成,但是如果要搜索的术语数量达到数千个,这就会变得很麻烦。Python 的 FlashText 模块是基于 FlashText 算法为这种情况提供了一个合适的替代方案。FlashText 最棒的一点是,不管搜索词的数量如何,运行时间都是相同的。你可以在这里了解更多内容。
安装:
$ pip install flashtext
例子:
提取关键字
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
['New York', 'Bay Area']替换关键字
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
'I love New York and NCR region.'
Fuzzywuzzy五、fuzzywuzzy
这个库的名字听起来很奇怪,但是在字符串匹配方面,fuzzywuzzy 是一个非常有用的库。可以很方便地实现计算字符串匹配度、令牌匹配度等操作,也可以很方便地匹配保存在不同数据库中的记录。
安装:
$ pip install fuzzywuzzy
例子:
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# 简单匹配度
fuzz.ratio("this is a test", "this is a test!")
97
# 模糊匹配度
fuzz.partial_ratio("this is a test", "this is a test!")
100更多有趣例子可以在 GitHub 仓库找到。
六、PyFlux
时间序列分析是机器学习领域中最常见的问题之一。PyFlux 是 Python 中的一个开源库,它是为处理时间序列问题而构建的。该库拥有一系列优秀的现代时间序列模型,包括但不限于 ARIMA、GARCH 和 VAR 模型。简而言之,PyFlux 为时间序列建模提供了一种概率方法。值得尝试一下。
安装
pip install pyflux
例子
详细用法和例子请参考官方文档。
七、Ipyvolume
结果展示也是数据科学中的一个重要方面。能够将结果进行可视化将具有很大优势。IPyvolume 是一个可以在 Jupyter notebook 中可视化三维体和图形(例如三维散点图等)的 Python 库,并且只需要少量配置。但它目前还是 1.0 之前的版本阶段。用一个比较恰当的比喻来解释就是:IPyvolume 的 volshow 对于三维数组就像 matplotlib 的 imshow 对于二维数组一样好用。可以在这里获取更多。
使用 pip
$ pip install ipyvolume
使用 Conda/Anaconda
$ conda install -c conda-forge ipyvolume
例子
动画
体绘制
八、Dash
Dash 是一个高效的用于构建 web 应用程序的 Python 框架。它是在 Flask、Plotly.js 和 React.js 基础上设计而成的,绑定了很多比如下拉框、滑动条和图表的现代 UI 元素,你可以直接使用 Python 代码来写相关分析,而无需再使用 javascript。Dash 非常适合构建数据可视化应用程序。然后,这些应用程序可以在 web 浏览器中呈现。用户指南可以在这里获取。
安装
pip install dash==0.29.0# 核心 dash 后端 pip install dash-html-components==0.13.2# HTML 组件 pip install dash-core-components==0.36.0# 增强组件 pip install dash-table==3.1.3# 交互式 DataTable 组件(最新!)
例子下面的例子展示了一个具有下拉功能的高度交互式图表。当用户在下拉菜单中选择一个值时,应用程序代码将动态地将数据从 Google Finance 导出到 panda DataFrame。
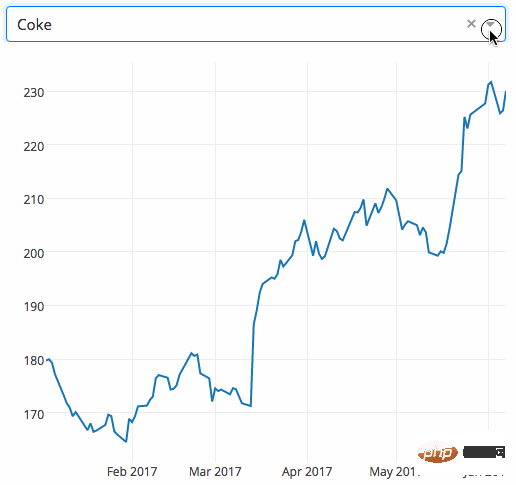
九、Gym
OpenAI 的 Gym 是一款用于增强学习算法的开发和比较工具包。它兼容任何数值计算库,如 TensorFlow 或 Theano。Gym 库是测试问题集合的必备工具,这个集合也称为环境 —— 你可以用它来开发你的强化学习算法。这些环境有一个共享接口,允许你进行通用算法的编写。
安装
pip install gym
例子这个例子会运行CartPole-v0环境中的一个实例,它的时间步数为 1000,每一步都会渲染整个场景。
总结
以上这些有用的数据科学 Python 库都是我精心挑选出来的,不是常见的如 numpy 和 pandas 等库。如果你知道其它库,可以添加到列表中来,请在下面的评论中提一下。另外别忘了先尝试运行一下它们。
以上是九个超级实用的数据科学Python库的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 神秘的JavaScript:它的作用以及为什么重要
Apr 09, 2025 am 12:07 AM
神秘的JavaScript:它的作用以及为什么重要
Apr 09, 2025 am 12:07 AM
JavaScript是现代Web开发的基石,它的主要功能包括事件驱动编程、动态内容生成和异步编程。1)事件驱动编程允许网页根据用户操作动态变化。2)动态内容生成使得页面内容可以根据条件调整。3)异步编程确保用户界面不被阻塞。JavaScript广泛应用于网页交互、单页面应用和服务器端开发,极大地提升了用户体验和跨平台开发的灵活性。
 mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
mysql 是否要付费
Apr 08, 2025 pm 05:36 PM
MySQL 有免费的社区版和收费的企业版。社区版可免费使用和修改,但支持有限,适合稳定性要求不高、技术能力强的应用。企业版提供全面商业支持,适合需要稳定可靠、高性能数据库且愿意为支持买单的应用。选择版本时考虑的因素包括应用关键性、预算和技术技能。没有完美的选项,只有最合适的方案,需根据具体情况谨慎选择。
 HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:轻量级、高水平可扩展的Python数据库HadiDB(hadidb)是一个用Python编写的轻量级数据库,具备高度水平的可扩展性。安装HadiDB使用pip安装:pipinstallhadidb用户管理创建用户:createuser()方法创建一个新用户。authentication()方法验证用户身份。fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB数据库密码的方法
Apr 08, 2025 pm 09:39 PM
直接通过 Navicat 查看 MongoDB 密码是不可能的,因为它以哈希值形式存储。取回丢失密码的方法:1. 重置密码;2. 检查配置文件(可能包含哈希值);3. 检查代码(可能硬编码密码)。
 mysql workbench 可以连接到 mariadb 吗
Apr 08, 2025 pm 02:33 PM
mysql workbench 可以连接到 mariadb 吗
Apr 08, 2025 pm 02:33 PM
MySQL Workbench 可以连接 MariaDB,前提是配置正确。首先选择 "MariaDB" 作为连接器类型。在连接配置中,正确设置 HOST、PORT、USER、PASSWORD 和 DATABASE。测试连接时,检查 MariaDB 服务是否启动,用户名和密码是否正确,端口号是否正确,防火墙是否允许连接,以及数据库是否存在。高级用法中,使用连接池技术优化性能。常见错误包括权限不足、网络连接问题等,调试错误时仔细分析错误信息和使用调试工具。优化网络配置可以提升性能
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
 mysql 无法连接到本地主机怎么解决
Apr 08, 2025 pm 02:24 PM
mysql 无法连接到本地主机怎么解决
Apr 08, 2025 pm 02:24 PM
无法连接 MySQL 可能是由于以下原因:MySQL 服务未启动、防火墙拦截连接、端口号错误、用户名或密码错误、my.cnf 中的监听地址配置不当等。排查步骤包括:1. 检查 MySQL 服务是否正在运行;2. 调整防火墙设置以允许 MySQL 监听 3306 端口;3. 确认端口号与实际端口号一致;4. 检查用户名和密码是否正确;5. 确保 my.cnf 中的 bind-address 设置正确。
 可以mysql 数据库存储图像吗
Apr 08, 2025 pm 05:27 PM
可以mysql 数据库存储图像吗
Apr 08, 2025 pm 05:27 PM
在 MySQL 数据库中存储图像可行,但并非最佳实践。MySQL 存储图像时使用 BLOB 类型,但会导致数据库体积膨胀、查询速度下降和备份复杂。更佳方案是将图像存储在文件系统上,并在数据库中仅存储图片路径,以优化查询性能和数据库体积。
