

强化学习发现矩阵乘法算法,DeepMind再登Nature封面推出AlphaTensor

数千年来,算法一直在帮助数学家们进行基本运算。早在很久之前,古埃及人就发明了一种不需要乘法表就能将两个数字相乘的算法。希腊数学家欧几里得描述了一种计算最大公约数的算法,这种算法至今仍在使用。在伊斯兰的黄金时代,波斯数学家 Muhammad ibn Musa al-Khwarizmi 设计了一种求解线性方程和二次方程的新算法,这些算法都对后来的研究产生了深远的影响。
事实上,算法一词的出现,有这样一种说法:波斯数学家 Muhammad ibn Musa al-Khwarizmi 名字中的 al-Khwarizmi 一词翻译为拉丁语为 Algoritmi 的意思,从而引出了算法一词。不过,虽然今天我们对算法很熟悉,可以从课堂中学习、在科研领域也经常遇到,似乎整个社会都在使用算法,然而发现新算法的过程是非常困难的。
现在,DeepMind 用 AI 来发现新算法。
在最新一期 Nature 封面论文《Discovering faster matrix multiplication algorithms with reinforcement learning》中,DeepMind 提出了 AlphaTensor,并表示它是第一个可用于为矩阵乘法等基本任务发现新颖、高效且可证明正确的算法的人工智能系统。简单来说,使用 AlphaTensor 能够发现新算法。这项研究揭示了 50 年来在数学领域一个悬而未决的问题,即找到两个矩阵相乘最快方法。


- 论文地址 :https://www.nature.com/articles/s41586-022-05172-4
- GitHub 地址:https://github.com/deepmind/alphatensor
AlphaTensor 建立在 AlphaZero 的基础上,而 AlphaZero 是一种在国际象棋、围棋和将棋等棋盘游戏中可以打败人类的智能体。这项工作展示了 AlphaZero 从用于游戏到首次用于解决未解决的数学问题的一次转变。
矩阵乘法
矩阵乘法是代数中最简单的运算之一,通常在高中数学课上教授。但在课堂之外,这种不起眼的数学运算在当代数字世界中产生了巨大的影响,在现代计算中无处不在。
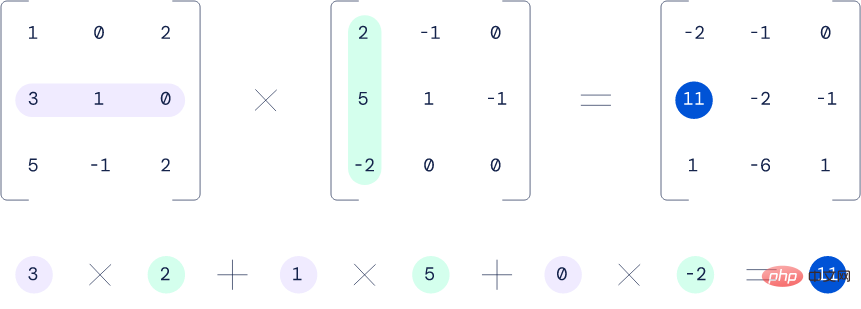
两个 3x3 矩阵相乘的例子。
你可能没注意到,我们生活中处处隐藏着矩阵相乘,如智能手机中的图像处理、识别语音命令、为电脑游戏生成图形等都有它在背后进行运算。遍布世界各地的公司都愿意花费大量的时间和金钱开发计算硬件以有效地解决矩阵相乘。因此,即使是对矩阵乘法效率的微小改进也会产生广泛的影响。
几个世纪以来,数学家认为标准矩阵乘法算法是效率最高的算法。但在 1969 年,德国数学家 Volken Strassen 通过证明确实存在更好的算法,这一研究震惊了整个数学界。

标准算法与 Strassen 算法对比,后者少进行了一次乘法运算,为 7 次,而前者需要 8 次,整体效率大幅提高。
通过研究非常小的矩阵(大小为 2x2),Strassen 发现了一种巧妙的方法来组合矩阵的项以产生更快的算法。之后数十年,研究者都在研究更大的矩阵,甚至找到 3x3 矩阵相乘的高效方法,都还没有解决。
DeepMind 的最新研究探讨了现代 AI 技术如何推动新矩阵乘法算法的自动发现。基于人类直觉(human intuition)的进步,对于更大的矩阵来说,AlphaTensor 发现的算法比许多 SOTA 方法更有效。该研究表明 AI 设计的算法优于人类设计的算法,这是算法发现领域向前迈出的重要一步。
算法发现自动化的过程和进展
首先将发现矩阵乘法高效算法的问题转换为单人游戏。其中,board 是一个三维度张量(数字数组),用于捕捉当前算法的正确程度。通过一组与算法指令相对应的所允许的移动,玩家尝试修改张量并将其条目归零。
当玩家设法这样做时,将为任何一对矩阵生成可证明是正确的矩阵乘法算法,并且其效率由将张量清零所采取的步骤数来衡量。
这个游戏非常具有挑战性,要考虑的可能算法的数量远远大于宇宙中原子的数量,即使对于矩阵乘法这样小的情况也是如此。与几十年来一直是人工智能挑战的围棋游戏相比,该游戏每一步可能的移动数量要多 30 个数量级(DeepMind 考虑的一种设置是 10^33 以上。)
为了解决这个与传统游戏明显不同的领域所面临的挑战,DeepMind 开发了多个关键组件,包括一个结合特定问题归纳偏置的全新神经网络架构、一个生成有用合成数据的程序以及一种利用问题对称性的方法。
接着,DeepMind 训练了一个利用强化学习的智能体 AlphaTensor 来玩这个游戏,该智能体在开始时没有任何现有矩阵乘法算法的知识。通过学习,AlphaTensor 随时间逐渐地改进,重新发现了历史上的快速矩阵算法(如 Strassen 算法),并且发现算法的速度比以往已知的要快。
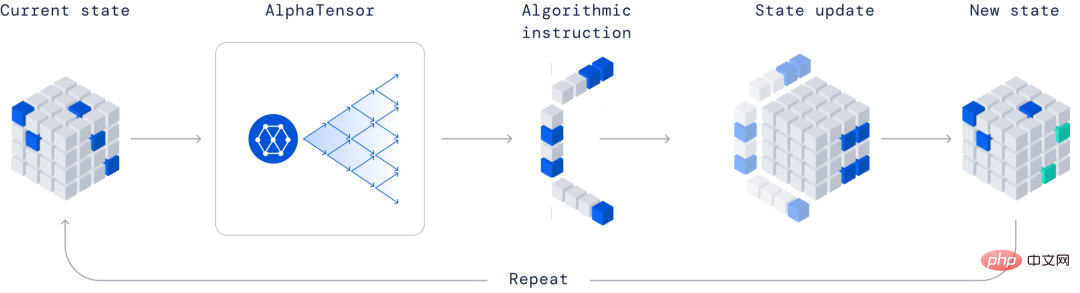
AlphaTensor 玩的单人游戏,目标是找到正确的矩阵乘法算法。游戏状态是一个由数字组成的立方数组(灰色表示 0,蓝色表示 1,绿色表示 - 1),它代表了要完成的剩余工作。
举例而言,如果学校里教的传统算法可以使用 100 次乘法完成 4x5 与 5x5 矩阵相乘,通过人类的聪明才智可以将这一数字降至 80 次。与之相比,AlphaTensor 发现的算法只需使用 76 次乘法即可完成相同的运算,如下图所示。

除了上述例子之外,AlphaTensor 发现的算法还首次在一个有限域中改进了 Strassen 的二阶算法。这些用于小矩阵相乘的算法可以当做原语来乘以任意大小的更大矩阵。
AlphaTensor 还发现了具有 SOTA 复杂性的多样化算法集,其中每种大小的矩阵乘法算法多达数千,表明矩阵乘法算法的空间比以前想象的要丰富。
在这个丰富空间中的算法具有不同的数学和实用属性。利用这种多样性,DeepMind 对 AlphaTensor 进行了调整,以专门发现在给定硬件(如 Nvidia V100 GPU、Google TPU v2)上运行速度快的算法。这些算法在相同硬件上进行大矩阵相乘的速度比常用算法快了 10-20%,表明了 AlphaTensor 在优化任意目标方面具备了灵活性。
AlphaTensor 具有一个对应于算法运行时的目标。当发现正确的矩阵乘法算法时,它会在指定硬件上进行基准测试,然后反馈给 AlphaTensor,以便在指定硬件上学习更高效的算法。
对未来研究和应用的影响
从数学的角度来看,对于旨在确定解决计算问题的最快算法的复杂性理论而言,DeepMind 的结果可以指导它的进一步研究。通过较以往方法更高效地探索可能的算法空间,AlphaTensor 有助于加深我们对矩阵乘法算法丰富性的理解。
此外,由于矩阵乘法是计算机图形学、数字通信、神经网络训练和科学计算等很多计算任务的核心组成部分,AlphaTensor 发现的算法可以显著提升这些领域的计算效率。
虽然本文只专注于矩阵乘法这一特定问题,但 DeepMind 希望能够启发更多的人使用 AI 来指导其他基础计算任务的算法发现。并且,DeepMind 的研究还表明,AlphaZero 这种强大的算法远远超出了传统游戏的领域,可以帮助解决数学领域的开放问题。
未来,DeepMind 希望基于他们的研究,更多地将人工智能用来帮助社会解决数学和科学领域的一些最重要的挑战。
以上是强化学习发现矩阵乘法算法,DeepMind再登Nature封面推出AlphaTensor的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian邮件服务器的防火墙是确保服务器安全性的重要步骤。以下是几种常用的防火墙配置方法,包括iptables和firewalld的使用。使用iptables配置防火墙安装iptables(如果尚未安装):sudoapt-getupdatesudoapt-getinstalliptables查看当前iptables规则:sudoiptables-L配置
 Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
本文介绍如何在Debian系统中调整ApacheWeb服务器的日志记录级别。通过修改配置文件,您可以控制Apache记录的日志信息的详细程度。方法一:修改主配置文件定位配置文件:Apache2.x的配置文件通常位于/etc/apache2/目录下,文件名可能是apache2.conf或httpd.conf,具体取决于您的安装方式。编辑配置文件:使用文本编辑器(例如nano)以root权限打开配置文件:sudonano/etc/apache2/apache2.conf
 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
 debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
在Debian系统中,readdir函数用于读取目录内容,但其返回的顺序并非预先定义的。要对目录中的文件进行排序,需要先读取所有文件,再利用qsort函数进行排序。以下代码演示了如何在Debian系统中使用readdir和qsort对目录文件进行排序:#include#include#include#include//自定义比较函数,用于qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系统中的readdir函数是用于读取目录内容的系统调用,常用于C语言编程。本文将介绍如何将readdir与其他工具集成,以增强其功能。方法一:C语言程序与管道结合首先,编写一个C程序调用readdir函数并输出结果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
在Debian邮件服务器上安装SSL证书的步骤如下:1.安装OpenSSL工具包首先,确保你的系统上已经安装了OpenSSL工具包。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私钥和证书请求接下来,使用OpenSSL生成一个2048位的RSA私钥和一个证书请求(CSR):openss
 Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
在Debian系统中,OpenSSL是一个重要的库,用于加密、解密和证书管理。为了防止中间人攻击(MITM),可以采取以下措施:使用HTTPS:确保所有网络请求使用HTTPS协议,而不是HTTP。HTTPS使用TLS(传输层安全协议)加密通信数据,确保数据在传输过程中不会被窃取或篡改。验证服务器证书:在客户端手动验证服务器证书,确保其可信。可以通过URLSession的委托方法来手动验证服务器
 Debian Hadoop日志管理怎么做
Apr 13, 2025 am 10:45 AM
Debian Hadoop日志管理怎么做
Apr 13, 2025 am 10:45 AM
在Debian上管理Hadoop日志,可以遵循以下步骤和最佳实践:日志聚合启用日志聚合:在yarn-site.xml文件中设置yarn.log-aggregation-enable为true,以启用日志聚合功能。配置日志保留策略:设置yarn.log-aggregation.retain-seconds来定义日志的保留时间,例如保留172800秒(2天)。指定日志存储路径:通过yarn.n
