
本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
2020年6月,OpenAI发布GPT-3,其千亿参数的规模和惊人的语言处理能力曾给国内AI界带来极大的震动。但由于GPT-3未对国内开放,一批提供文本生成服务的商业公司在海外诞生时,我们只能望洋兴叹。
今年8月,伦敦的开源公司Stability AI发布文生图模型Stable Diffusion,并免费开源了模型的权重和代码,这迅速引发了AI作画应用在全球范围内的爆炸式增长。
可以说,今年下半年的AIGC热潮,开源起到了直接的催化作用。
而当大模型成为所有人都能参与的游戏时,得益的并不仅仅是AIGC。
四年前,一个名为BERT的语言模型问世,以3亿的参数量从此改变了AI模型的游戏规则。
今天,AI模型的体量已经跃升至万亿的规模,但大模型的“垄断性”也随之日益凸显:
大公司、大算力、强算法、大模型,它们共同堆砌了一道普通开发者和中小企业难以闯进的围墙。
技术壁垒,以及训练和使用大模型所需的计算资源和基础设施,阻碍了我们从「炼」大模型走向「用」大模型的这条路。因此,开源迫在眉睫。通过开源让更多人参与大模型的这场游戏,将大模型从一种新兴的AI技术转变为稳健的基础设施,这正在成为许多大模型缔造者的共识。
也是在这样的共识下,前不久阿里巴巴达摩院在云栖大会上推出的中文模型开源社区“魔搭”(ModelScope)在AI界引起了很大的关注,目前国内的一些机构已经开始在该社区上贡献模型,或是建立自己的开源模型体系。
国外的大模型开源生态建设目前来看要领先于国内。Stability AI是私营公司出身但自带开源基因,有自己庞大的开发者社区,在开源的同时还有稳定的盈利模式。
今年7月发布的BLOOM有1760亿参数,是目前最大的开源语言模型,它背后的BigScience更是完美契合了开源精神,从头到脚透露着与科技巨头对弈的气势。BigScience由Huggingface带头发起的开放式协作组织,并非正式成立的实体,BLOOM的诞生,是来自70多个国家的1000多名研究人员在超级计算机上训练了117天的结果。
另外,科技巨头也并非没有参与大模型的开源。今年5月,Meta开源了1750亿参数的大模型OPT,除了允许OPT可被用于非商业用途外,还发布了其代码以及记录培训过程的100页日志,可谓开源得十分彻底。
研究团队在OPT的论文摘要里直截了当地指出,「考虑到计算成本,如果没有大量资金,这些模型是很难复制的。对于少数可通过API获得的模型,无法访问完整的模型权重,这致它们难以得到研究」。模型的全称「Open Pre-trained Transformers」也表明了Meta的开源态度。这可以说是暗讽了一把由并不「Open」的OpenAI发布的GPT-3(仅提供API付费服务)、以及今年4月谷歌推出的5400亿参数大模型PaLM(未开源)。
在垄断色彩一向浓厚的大厂中,Meta这番开源的举动是一股清流。当时斯坦福大学基础模型研究中心的负责人Percy Liang评价道:「这是朝着开辟研究新机遇迈出的令人兴奋的一步,一般而言,我们可以认为更强的开放能够使研究人员得以解决更深层次的问题。」
Percy Liang的这句话这也从学术层面回答了为何大模型一定要做开源的问题。
原创成果的诞生,需要开源来提供土壤。
一个研发团队训练出一个大模型,如果止步于在顶级会议上发表一篇论文,那么其他研究人员得到的就只是论文中各种「秀肌肉」的数字,而看不到模型训练技术的更多细节,只能花时间去复现,还不一定能复现成功。可复现性是科学研究结果可靠、可信的一个保证,有了开放的模型、代码和数据集,科研人员便能更及时地跟上最前沿的研究,站在巨人的肩膀上去触及一颗更高处的果实,这可以省下许多时间成本、加快技术创新的速度。
国内在大模型工作上的原创力不足,就主要体现为盲追模型尺寸、但在底层架构上无甚创新,这是从事大模型研究的业内专家的普遍共识。
清华大学计算机系的刘知远副教授向AI科技评论指出:国内在大模型的架构上有一些相对比较创新的工作,但基本上都还是以Transformer为基础,国内还比较缺乏像Transformer这种奠基式架构,以及BERT、GPT-3这样能够引起领域大变革的模型。
IDEA研究院(粤港澳大湾区数字经济研究院 )的首席科学家张家兴博士也告诉AI科技评论,从百亿、千亿到万亿,我们突破了各种系统上、工程上的挑战后,应该要有新的模型结构方面的思考,而不再是单纯地把模型做大。
另一方面,大模型在技术上要取得进步,还需有一套模型评估标准,标准的产生则要求公开和透明。最近的一些研究正在试图对众多大模型提出各种评估指标,但有一些优秀的模型由于不可访问而被排除在外,如谷歌在其Pathways架构下训练的大模型PaLM具备超强的语言理解能力,能轻松解释笑话的笑点,还有DeepMind的语言大模型Chinchilla,都没有开源。
但无论是从模型本身的出色能力还是从这些大厂的地位来看,它们都本不该缺席这样的公平竞技场。
一个令人遗憾的事实是,Percy Liang最近与其同事合作的一项研究表明,与非开源模型相比,目前的开源模型在许多核心场景上的表现都存在一定的差距。如OPT-175B、BLOOM-176B以及来自清华大学的GLM-130B等开源大模型,在各项任务上几乎全面输给了非开源的大模型,后者包括OpenAI的InstructGPT、Microsoft/NVIDIA的TNLG-530B等等(如下图)。
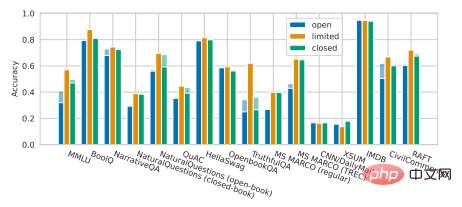
图注:Percy Liang et al. Holistic Evaluation of Language Models
要消解这种尴尬局面,需要各个领头羊们开源开放自家的优质大模型,这样大模型领域的整体进展才能更快地上一个台阶。
在大模型的产业落地方面,开源更是一条必经之路。
若以GPT-3的发布为起点,大模型经过两年多的你追我赶,在研发技术上已经较为成熟,但在全球范围内,大模型的落地都还处于早期阶段。国内各个大厂所研发的大模型固然有内部业务的落地场景,但整体上尚未有成熟的商业化模式。
在大模型落地正处蓄势待发之时,做好开源能够为将来大规模的落地生态打好基础。
大模型的本质决定了落地对开源的需求。阿里巴巴达摩院副院长周靖人告诉AI科技评论,「大模型是对人类知识体系的抽象与提炼,所以它能够应用的场景和产生的价值是巨大的。」而只有通过开源,大模型的应用潜力才能在众多有创造力的开发者那里得到最大限度的释放。
这是封闭了大模型内部技术细节的API模式所无法做到的。首先,这种模式的适用对象是低开发能力的模型使用者,对他们而言,大模型落地的成败相当于完全掌握在研发机构的手中。
以提供大模型API付费服务的最大赢家OpenAI为例,据OpenAI的统计,目前全世界已经有300多个使用了GPT-3技术的应用程序,但这个事实的前提是OpenAI的研发实力底气足、GPT-3也足够强大。如果模型本身性能不佳,那么这类开发者也就束手无策了。
更关键的是,大模型通过开放API所能提供的能力有限,难以承接复杂多样的应用需求。目前在市场上只是催生出一些具有创意的APP,但整体上还处于一种「玩具」的阶段,远没有达到大规模产业化的地步。
「产生的价值没有那么大,成本又收不回来,所以基于GPT-3 API的应用场景非常受限,很多工业界的人其实并不认可这种方式。」张家兴说道。的确,像国外的copy.ai、Jasper这些公司是选择做AI辅助写作业务,用户市场相对更大,所以才能产生比较大的商业价值,而更多应用还只是小打小闹。
相比之下,开源开放做的是「授人以渔」。
在开源模式下,企业凭借公开的源代码,在已有的基础框架上进行符合自己业务需求的训练、二次开发,这能够发挥大模型的通用性优势,释放远超于现在的生产力,最终带来大模型技术在产业中的真正落地。
作为目前大模型商业化落地最清晰可见的一条赛道,AIGC的这一波起飞已经印证了大模型开源模式的成功,然而在其他更多应用场景上,大模型的开源开放仍属少数,国内外皆是如此。西湖大学深度学习实验室的负责人蓝振忠曾向AI科技评论表示,目前大模型的成果虽然有很多,但开源极少,普通研究者的访问有限,这一点很令人惋惜。
贡献、参与、协作,以这些关键词为核心的开源,能够汇聚大量怀抱热情的开发者,共同打造一个可能具有变革意义的大模型项目,让大模型更快地从实验室走向产业。
大模型开源的重要性是共识,但通往开源的路上还有一个巨大的拦路虎:算力。
这也正是当前大模型落地所面临的最大挑战。即便Meta开源了OPT,但到目前为止它似乎还没有在应用市场上泛起大的涟漪,究其根本,算力成本仍然是小型开发者的不可承受之重,先不说对大模型做微调、二次开发,仅仅是做推理都很困难。
正因如此,在对拼参数的反思潮下,不少研发机构转向了做轻量模型的思路,将模型的参数控制在几亿至几十亿之间。澜舟科技推出的「孟子」模型、IDEA研究院开源的「封神榜」系列模型,都是国内走这条路线的代表。他们将超大模型的各种能力拆分到参数相对更小的模型上,已经在一些单项任务上证明了自身超越千亿模型的能力。
但毫无疑问,大模型的路必然不会就此停下,多位业内专家都向AI科技评论表示,大模型的参数依然有上升空间,肯定还要有人去继续探索更大规模的模型。所以我们不得不直面大模型开源后的窘境,那么,有哪些解决办法?
我们首先从算力本身的角度来考虑。未来大规模计算机群、算力中心的建设肯定是一个趋势,毕竟端上的计算资源终归难以满足需求。但如今摩尔定律已经趋缓,业界也不乏摩尔定律将要走向终结的论调,如果单纯地寄希望于算力的提升,是远水解不了近渴。
「现在一张卡可以跑(就推理而言)一个十亿模型,按目前算力的增长速度,等到一张卡可以跑一个千亿模型也就是算力要得到百倍提升,可能需要十年。」张家兴解释。
大模型的落地等不了这么久。
另一个方向是在训练技术上做文章,加快大模型推理速度、降低算力成本、减少能耗,以此来提高大模型的易用性。
比如Meta的OPT(对标GPT-3)只需要16块英伟达v100 GPU就可以训练和部署完整模型的代码库,这个数字是GPT-3的七分之一。最近,清华大学与智谱AI联合开源的双语大模型GLM-130B,通过快速推理方法,已经将模型压缩到可以在一台A100(40G*8)或V100(32G*8)服务器上进行单机推理。
在这个方向上努力当然是很有意义的,大厂们不愿意开源大模型一个不言自明的原因,就是高昂的训练成本。此前有专家估计,GPT-3的训练使用了上万块英伟达v100 GPU,总成本高达2760万美元,个人如果要训练出一个PaLM也要花费900至1700万美元。大模型的训练成本若能降下来,自然也就能提高他们的开源意愿。
但归根结底,这只能从工程上对算力资源的约束起到缓解作用,而并非终极方案。尽管目前许多千亿级、万亿级的大模型已经开始宣传自己的「低能耗」优势,但算力的围墙仍然太高。
最终,我们还是要回到大模型自身寻找突破点,一个十分被看好的方向便是稀疏动态大模型。
稀疏大模型的特点是容量非常大,但只有用于给定任务、样本或标记的某些部分被激活。也就是说,这种稀疏动态结构能够让大模型在参数量上再跃升几个层级,同时又不必付出巨大的计算代价,一举两得。这与GPT-3这样的稠密大模型相比有着极大的优势,后者需要激活整个神经网络才能完成即使是最简单的任务,资源浪费巨大。
谷歌是稀疏动态结构的先行者,他们于2017年首次提出了MoE(Sparsely-Gated Mixture-of-Experts Layer,稀疏门控的专家混合层),去年推出的1.6万亿参数大模型Switch Transformers就融合了MoE风格的架构,训练效率与他们之前的稠密模型T5-Base Transformer相比提升了7倍。
而今年的PaLM所基于的Pathways统一架构,更是稀疏动态结构的典范:模型能够动态地学习网络中的特定部分擅长何种任务,我们根据需要调用经过网络的小路径即可,而无需激活整个神经网络才能完成一项任务。

图注:Pathways架构
这本质上与人脑的运作方式类似,人脑中有百亿个神经元,但在执行特定任务中只激活特定功能的神经元,否则巨大的能耗是人难以承受的。
大、通用,且高效,这种大模型路线无疑具有很强的吸引力。
「以后有了稀疏动态的加持,计算代价就不会那么大,但是模型参数一定会越来越大,稀疏动态结构或许会为大模型打开一个新天地,再往十万亿、百万亿走也没问题。」张家兴相信,稀疏动态结构将是解决大模型尺寸与算力代价之间矛盾的最终途径。但他也补充说,在当下这种模型结构还未普及的情况下,再盲目将模型继续做大确实意义不大。
目前国内在这个方向上的尝试还比较少,且不如谷歌做得更彻底。大模型结构上的探索创新与开源相互促进,我们需要更多开源来激发大模型技术的变革。
阻碍大模型开源的,除了大模型的算力成本导致的低可用性,还有安全问题。
对于大模型尤其是生成大模型开源后带来的滥用风险,国外担忧的声音似乎更多,争议也不少,这成了许多机构选择不开源大模型的凭据,但或许也是他们拒绝慷慨的一个借口。
OpenAI已经因此招致了许多批评。他们在2019年发布GPT-2时就声称,模型的文本生成能力过于强大,可能会带来伦理方面的危害,因而不适合开源。一年后公开GPT-3时也仅仅提供了API试用,目前GPT-3的开源版本实际上是由开源社区自行复现的。
事实上,对大模型的访问限制反而会不利于大模型提高稳健性、减少偏见和毒性。Meta AI的负责人Joelle Pineau在谈到开源OPT的决定时,曾诚恳地表示,单靠自家团队解决不了全部问题,比如文本生成过程中可能产生的伦理偏见和恶意词句。他们认为,如果做足功课,就可以在负责任的情况下让大模型变得可以公开访问。
在防范滥用风险的同时保持开放获取和足够的透明度,这并非易事。作为打开了「潘多拉魔盒」的人,Stability AI享受了主动开源带来的好名声,但最近也遭遇了开源带来的反噬,在版权归属等方面引起了争议。
开源背后的「自由与安全」这一古老的辩证命题由来已久,或许并没有一个绝对正确的答案,但是在大模型开始走向落地的当下,一个清楚的事实是:大模型开源,我们做得还远远不够。
两年多过去,我们已经拥有了自己的万亿级别大模型,在接下来大模型从「读万卷书」到「行万里路」的转变过程中,开源是一个必然的选择。
最近,GPT-4正呼之欲出,所有人都对它能力上的飞跃抱着极大的期待,但我们不知道,未来它能给多少人释放多大的生产力?
以上是AI 大模型开源困境:垄断、围墙与算力之殇的详细内容。更多信息请关注PHP中文网其他相关文章!






















