

DeepMind新研究:transformer可以自我改进,无需人为干预

目前,Transformers 已经成为序列建模的强大神经网络架构。预训练 transformer 的一个显着特性是它们有能力通过提示 conditioning 或上下文学习来适应下游任务。经过大型离线数据集上的预训练之后,大规模 transformers 已被证明可以高效地泛化到文本补全、语言理解和图像生成方面的下游任务。
最近的工作表明,transformers 还可以通过将离线强化学习(RL)视作顺序预测问题,进而从离线数据中学习策略。 Chen et al. (2021)的工作表明,transformers 可以通过模仿学习从离线 RL 数据中学习单任务策略,随后的工作表明 transformers 可以在同领域和跨领域设置中提取多任务策略。这些工作都展示了提取通用多任务策略的范式,即首先收集大规模和多样化的环境交互数据集,然后通过顺序建模从数据中提取策略。这类通过模仿学习从离线 RL 数据中学习策略的方法被称为离线策略蒸馏(Offline Policy Distillation)或策略蒸馏(Policy Distillation, PD)。
PD 具有简单性和可扩展性,但它的一大缺点是生成的策略不会在与环境的额外交互中逐步改进。举例而言,谷歌的通才智能体Multi-Game Decision Transformers 学习了一个可以玩很多Atari 游戏的返回条件式(return-conditioned)策略,而DeepMind 的通才智能体Gato 通过上下文任务推理来学习一个解决多样化环境中任务的策略。遗憾的是,这两个智能体都不能通过试错来提升上下文中的策略。因此 PD 方法学习的是策略而不是强化学习算法。
在近日 DeepMind 的一篇论文中,研究者假设 PD 没能通过试错得到改进的原因是它训练用的数据无法显示学习进度。当前方法要么从不含学习的数据中学习策略(例如通过蒸馏固定专家策略),要么从包含学习的数据中学习策略(例如RL 智能体的重放缓冲区),但后者的上下文大小(太小)无法捕获策略改进。

论文地址:https://arxiv.org/pdf/2210.14215.pdf
研究者的主要观察结果是,RL 算法训练中学习的顺序性在原则上可以将强化学习本身建模为一个因果序列预测问题。具体地,如果一个transformer 的上下文足够长,包含了由学习更新带来的策略改进,那么它不仅应该可以表示一个固定策略,而且能够通过关注之前episodes 的状态、动作和奖励来表示一个策略改进算子。 这样开启了一种可能性,即任何 RL 算法都可以通过模仿学习蒸馏成足够强大的序列模型如 transformer,并将这些模型转换为上下文 RL 算法。
研究者提出了算法蒸馏(Algorithm Distillation, AD),这是一种通过优化RL 算法学习历史中因果序列预测损失来学习上下文策略改进算子的方法。如下图 1 所示,AD 由两部分组成。首先通过保存 RL 算法在大量单独任务上的训练历史来生成大型多任务数据集,然后 transformer 模型通过将前面的学习历史用作其上下文来对动作进行因果建模。由于策略在源 RL 算法的训练过程中持续改进,因此 AD 不得不学习改进算子以便准确地建模训练历史中任何给定点的动作。至关重要的一点是,transformer 上下文必须足够大(即 across-episodic)才能捕获训练数据的改进。
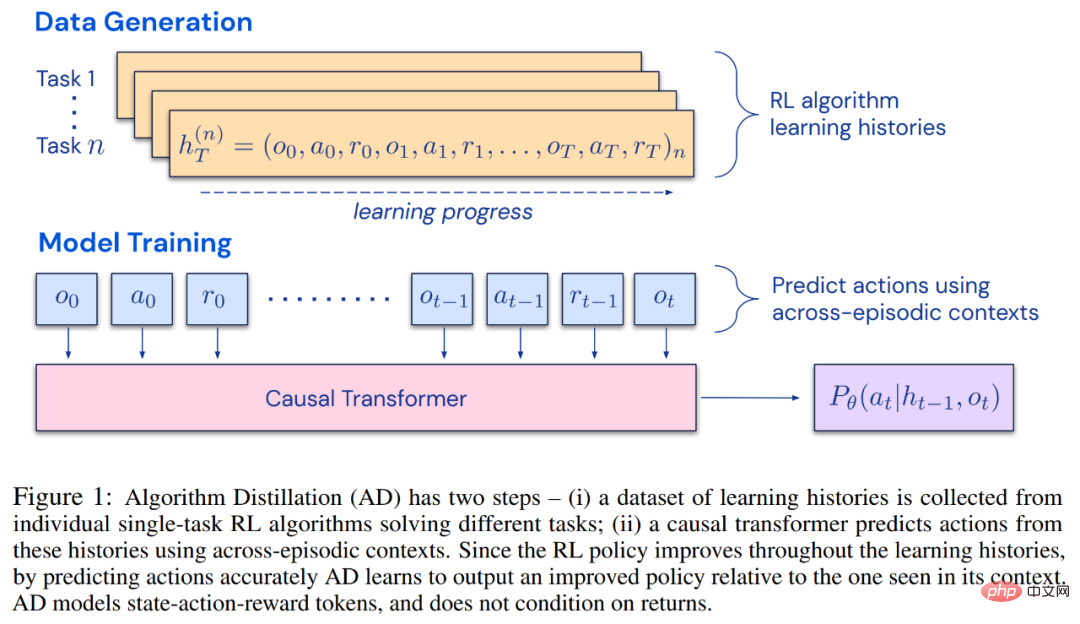
研究者表示,通过使用足够大上下文的因果transformer 来模仿基于梯度的RL 算法,AD 完全可以在上下文中强化新任务学习。研究者在很多需要探索的部分可观察环境中评估了 AD,包括来自 DMLab 的基于像素的 Watermaze,结果表明 AD 能够进行上下文探索、时序信度分配和泛化。此外,AD 学习到的算法比生成 transformer 训练源数据的算法更加高效。
最后值得关注的是,AD 是首个通过对具有模仿损失的离线数据进行顺序建模以展示上下文强化学习的方法。
方法
在生命周期内,强化学习智能体需要在执行复杂的动作方面表现良好。对智能体而言,不管它所处的环境、内部结构和执行情况如何,都可以被视为是在过去经验的基础上完成的。可用如下形式表示:
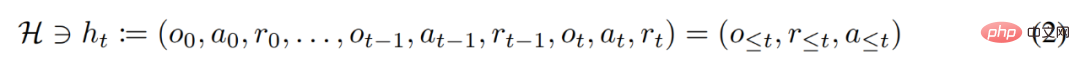
研究者同时将「长期历史条件, long history-conditioned」策略看作一种算法,得出:

其中∆(A)表示动作空间 A 上的概率分布空间。公式 (3) 表明,该算法可以在环境中展开,以生成观察、奖励和动作序列。为了简单起见,该研究将算法用 P 表示,将环境(即任务)用 的学习历史都是由算法
的学习历史都是由算法 表示,这样对于任何给定任务
表示,这样对于任何给定任务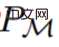 生成的。可以得到
生成的。可以得到
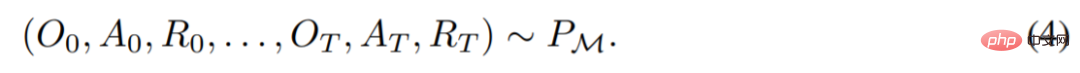
研究者用大写拉丁字母表示随机变量,例如 O、A、R 及其对应的小写形式 o,α,r。通过将算法视为长期历史条件策略,他们假设任何生成学习历史的算法都可以通过对动作执行行为克隆来转换成神经网络。接下来,该研究提出了一种方法,该方法提供了智能体在生命周期内学习具有行为克隆的序列模型,以将长期历史映射到动作分布。
实际执行
在实践中,该研究将算法蒸馏过程 ( algorithm distillation ,AD)实现为一个两步过程。首先,通过在许多不同的任务上运行单独的基于梯度的 RL 算法来收集学习历史数据集。接下来,训练具有多情节上下文的序列模型来预测历史中的动作。具体算法如下所示:

实验
实验要求所使用的环境都支持许多任务,而这些任务不能从观察中轻易的进行推断,并且情节(episodes)足够短,可以有效地训练跨情节因果 transformers。这项工作的主要目的是调查相对于先前工作,AD 强化在多大程度上是在上下文中学习的。实验将 AD、 ED( Expert Distillation) 、RL^2 等进行了比较。
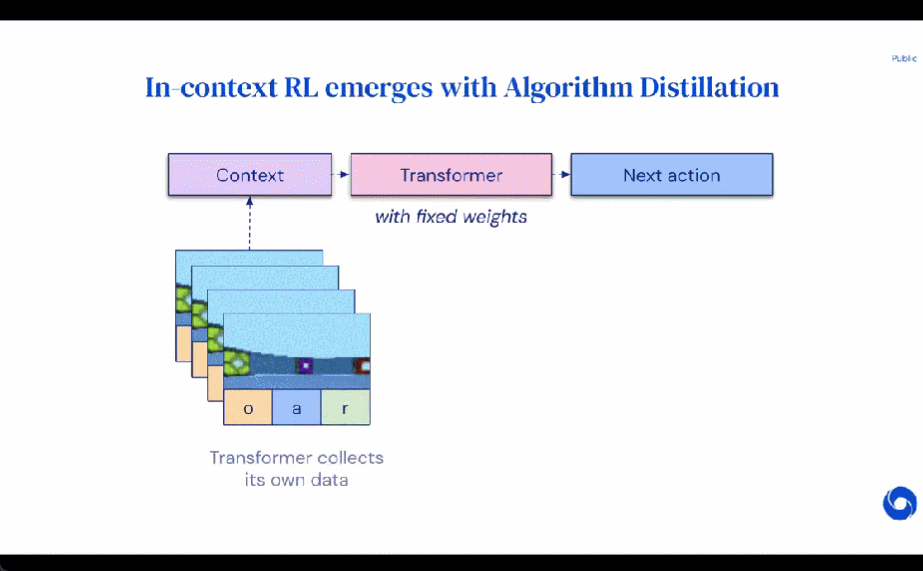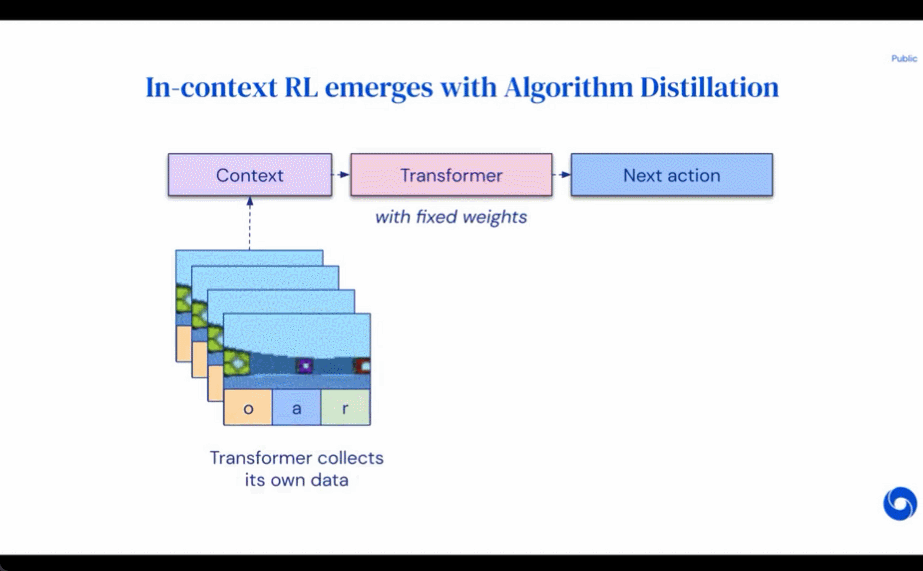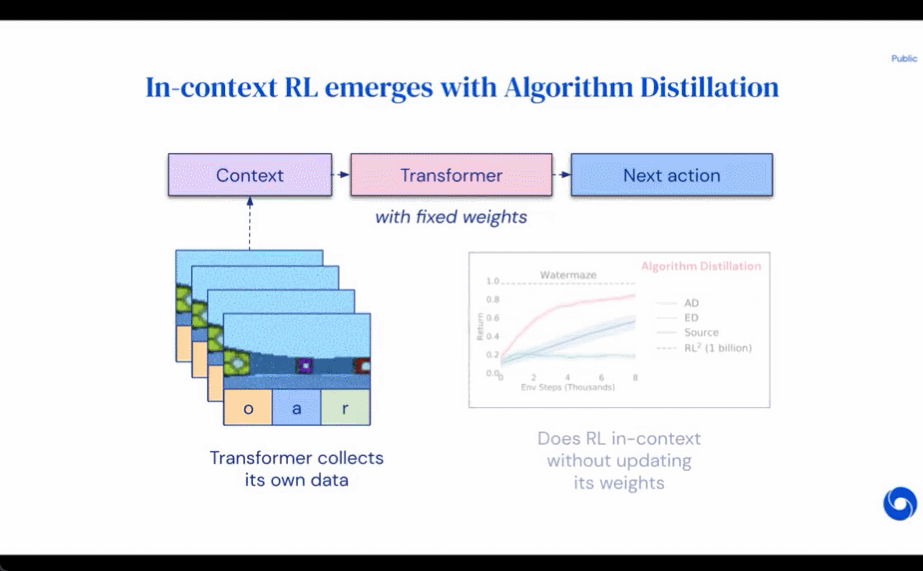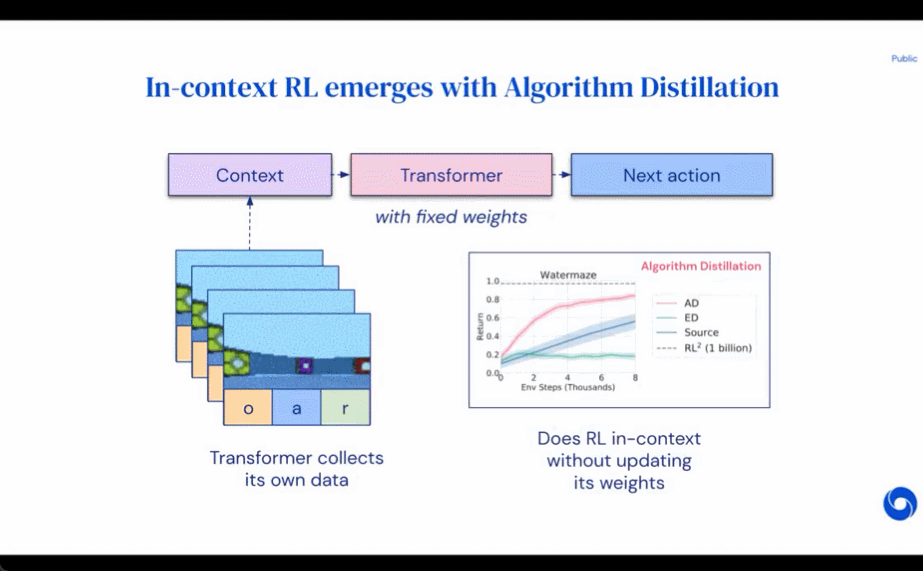
评估 AD、ED、 RL^2 结果如图 3 所示。该研究发现 AD 和 RL^2 都可以在上下文中学习从训练分布中采样的任务,而 ED 则不能,尽管 ED 在分布内评估时确实比随机猜测做得更好。
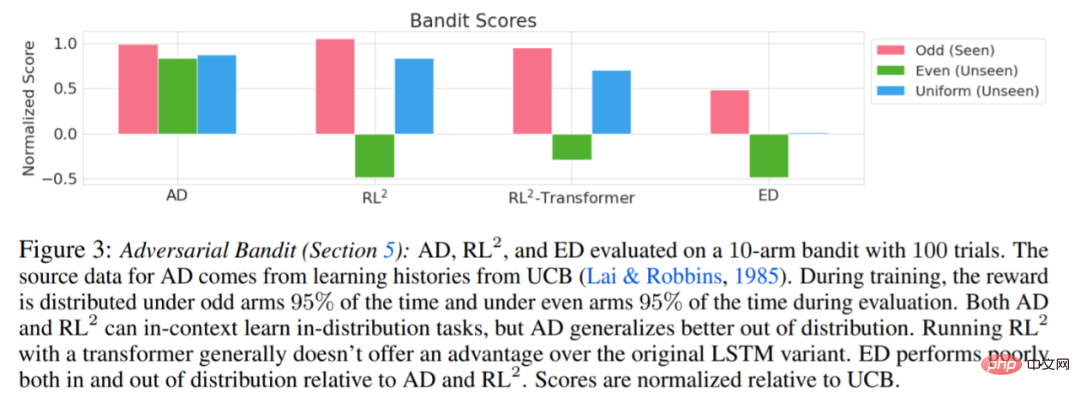
围绕下图 4,研究者回答了一系列问题。AD 是否表现出上下文强化学习?结果表明 AD 上下文强化学习在所有环境中都能学习,相比之下,ED 在大多数情况下都无法在上下文中探索和学习。
AD 能从基于像素的观察中学习吗?结果表明 AD 通过上下文 RL 最大化了情景回归,而 ED 则不能学习。
AD 是否可以学习一种比生成源数据的算法更有效的 RL 算法?结果表明 AD 的数据效率明显高于源算法(A3C 和 DQN)。
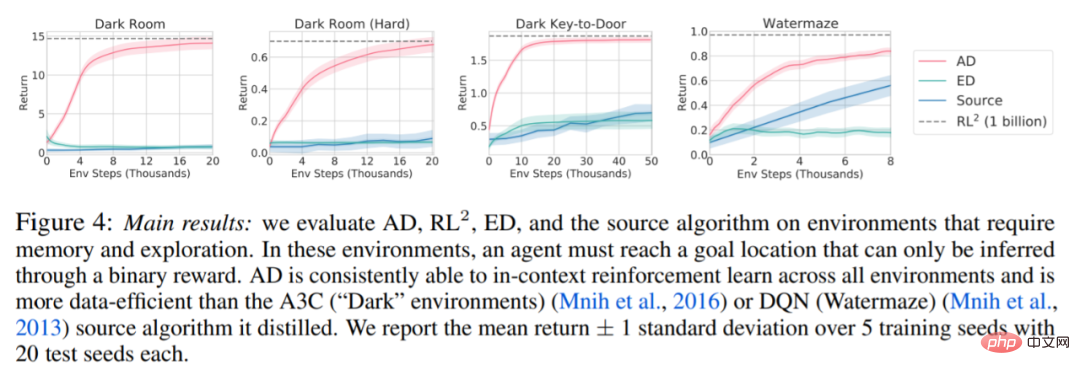
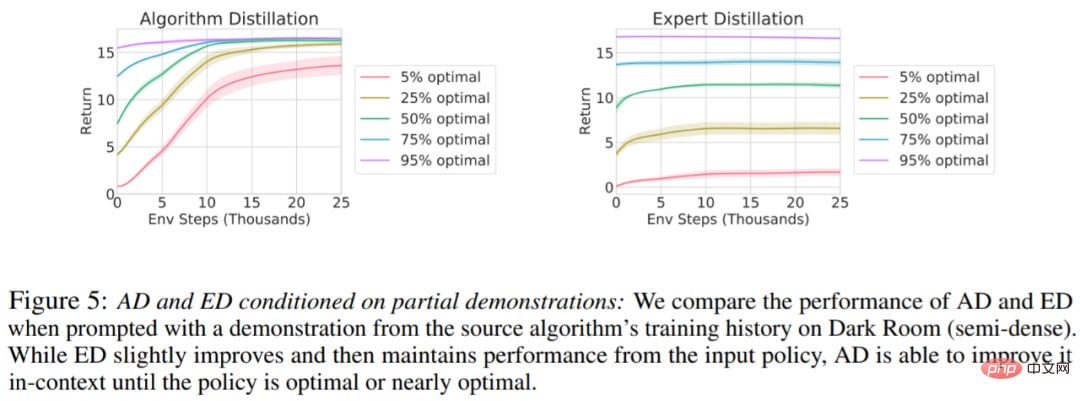
是否可以通过演示来加速 AD?为了回答这个问题,该研究保留测试集数据中沿源算法历史的不同点采样策略,然后,使用此策略数据预先填充 AD 和 ED 的上下文,并在 Dark Room 的环境中运行这两种方法,将结果绘制在图 5 中。虽然 ED 保持了输入策略的性能,AD 在上下文中改进每个策略,直到它接近最优。重要的是,输入策略越优化,AD 改进它的速度就越快,直到达到最优。
更多细节,请参考原论文。
以上是DeepMind新研究:transformer可以自我改进,无需人为干预的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 使用ddrescue在Linux上恢复数据
Mar 20, 2024 pm 01:37 PM
使用ddrescue在Linux上恢复数据
Mar 20, 2024 pm 01:37 PM
DDREASE是一种用于从文件或块设备(如硬盘、SSD、RAM磁盘、CD、DVD和USB存储设备)恢复数据的工具。它将数据从一个块设备复制到另一个块设备,留下损坏的数据块,只移动好的数据块。ddreasue是一种强大的恢复工具,完全自动化,因为它在恢复操作期间不需要任何干扰。此外,由于有了ddasue地图文件,它可以随时停止和恢复。DDREASE的其他主要功能如下:它不会覆盖恢复的数据,但会在迭代恢复的情况下填补空白。但是,如果指示工具显式执行此操作,则可以将其截断。将数据从多个文件或块恢复到单
 开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
0.这篇文章干了啥?提出了DepthFM:一个多功能且快速的最先进的生成式单目深度估计模型。除了传统的深度估计任务外,DepthFM还展示了在深度修复等下游任务中的最先进能力。DepthFM效率高,可以在少数推理步骤内合成深度图。下面一起来阅读一下这项工作~1.论文信息标题:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 如何多条件使用Excel过滤功能
Feb 26, 2024 am 10:19 AM
如何多条件使用Excel过滤功能
Feb 26, 2024 am 10:19 AM
如果您需要了解如何在Excel中使用具有多个条件的筛选功能,以下教程将指导您完成相应步骤,确保您可以有效地对数据进行筛选和排序。Excel的筛选功能是非常强大的,能够帮助您从大量数据中提取所需的信息。这个功能可以根据您设定的条件,过滤数据并只显示符合条件的部分,让数据的管理变得更加高效。通过使用筛选功能,您可以快速找到目标数据,节省了查找和整理数据的时间。这个功能不仅可以应用在简单的数据列表上,还可以根据多个条件进行筛选,帮助您更精准地定位所需信息。总的来说,Excel的筛选功能是一个非常实用的
 DeepMind机器人打乒乓球,正手、反手溜到飞起,全胜人类初学者
Aug 09, 2024 pm 04:01 PM
DeepMind机器人打乒乓球,正手、反手溜到飞起,全胜人类初学者
Aug 09, 2024 pm 04:01 PM
但可能打不过公园里的老大爷?巴黎奥运会正在如火如荼地进行中,乒乓球项目备受关注。与此同时,机器人打乒乓球也取得了新突破。刚刚,DeepMind提出了第一个在竞技乒乓球比赛中达到人类业余选手水平的学习型机器人智能体。论文地址:https://arxiv.org/pdf/2408.03906DeepMind这个机器人打乒乓球什么水平呢?大概和人类业余选手不相上下:正手反手都会:对手采用多种打法,该机器人也能招架得住:接不同旋转的发球:不过,比赛激烈程度似乎不如公园老大爷对战。对机器人来说,乒乓球运动
 谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基准测试中性能已经超过Pytorch和TensorFlow,7项指标排名第一。而且测试并不是在JAX性能表现最好的TPU上完成的。虽然现在在开发者中,Pytorch依然比Tensorflow更受欢迎。但未来,也许有更多的大模型会基于JAX平台进行训练和运行。模型最近,Keras团队为三个后端(TensorFlow、JAX、PyTorch)与原生PyTorch实现以及搭配TensorFlow的Keras2进行了基准测试。首先,他们为生成式和非生成式人工智能任务选择了一组主流
 iPhone上的蜂窝数据互联网速度慢:修复
May 03, 2024 pm 09:01 PM
iPhone上的蜂窝数据互联网速度慢:修复
May 03, 2024 pm 09:01 PM
在iPhone上面临滞后,缓慢的移动数据连接?通常,手机上蜂窝互联网的强度取决于几个因素,例如区域、蜂窝网络类型、漫游类型等。您可以采取一些措施来获得更快、更可靠的蜂窝互联网连接。修复1–强制重启iPhone有时,强制重启设备只会重置许多内容,包括蜂窝网络连接。步骤1–只需按一次音量调高键并松开即可。接下来,按降低音量键并再次释放它。步骤2–该过程的下一部分是按住右侧的按钮。让iPhone完成重启。启用蜂窝数据并检查网络速度。再次检查修复2–更改数据模式虽然5G提供了更好的网络速度,但在信号较弱
 超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂炼大模型,一互联网的数据不够用,根本不够用。训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。尤其在多模态任务中,这一问题尤为突出。一筹莫展之际,来自人大系的初创团队,用自家的新模型,率先在国内把“模型生成数据自己喂自己”变成了现实。而且还是理解侧和生成侧双管齐下,两侧都能生成高质量、多模态的新数据,对模型本身进行数据反哺。模型是啥?中关村论坛上刚刚露面的多模态大模型Awaker1.0。团队是谁?智子引擎。由人大高瓴人工智能学院博士生高一钊创立,高
 特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人Optimus最新视频出炉,已经可以在厂子里打工了。正常速度下,它分拣电池(特斯拉的4680电池)是这样的:官方还放出了20倍速下的样子——在小小的“工位”上,拣啊拣啊拣:这次放出的视频亮点之一在于Optimus在厂子里完成这项工作,是完全自主的,全程没有人为的干预。并且在Optimus的视角之下,它还可以把放歪了的电池重新捡起来放置,主打一个自动纠错:对于Optimus的手,英伟达科学家JimFan给出了高度的评价:Optimus的手是全球五指机器人里最灵巧的之一。它的手不仅有触觉
