

使用Python实现一个简单的四则运算解释器

计算功能演示
这里先展示了程序的帮助信息,然后是几个简单的四则运算测试,看起来是没问题了(我可不敢保证,程序没有bug!)。
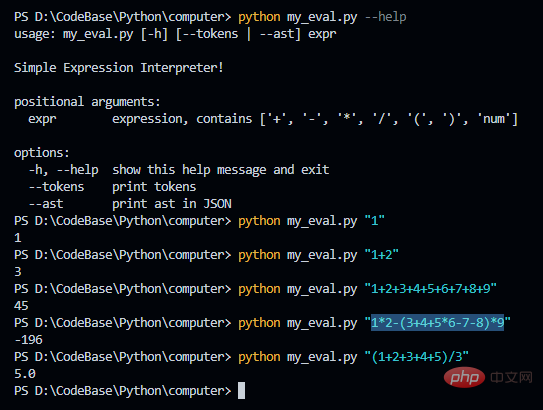
输出 tokens
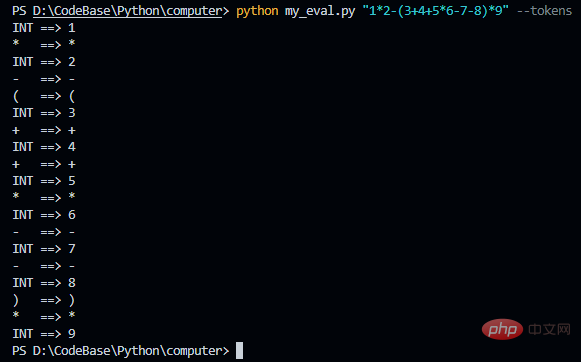
输出 AST
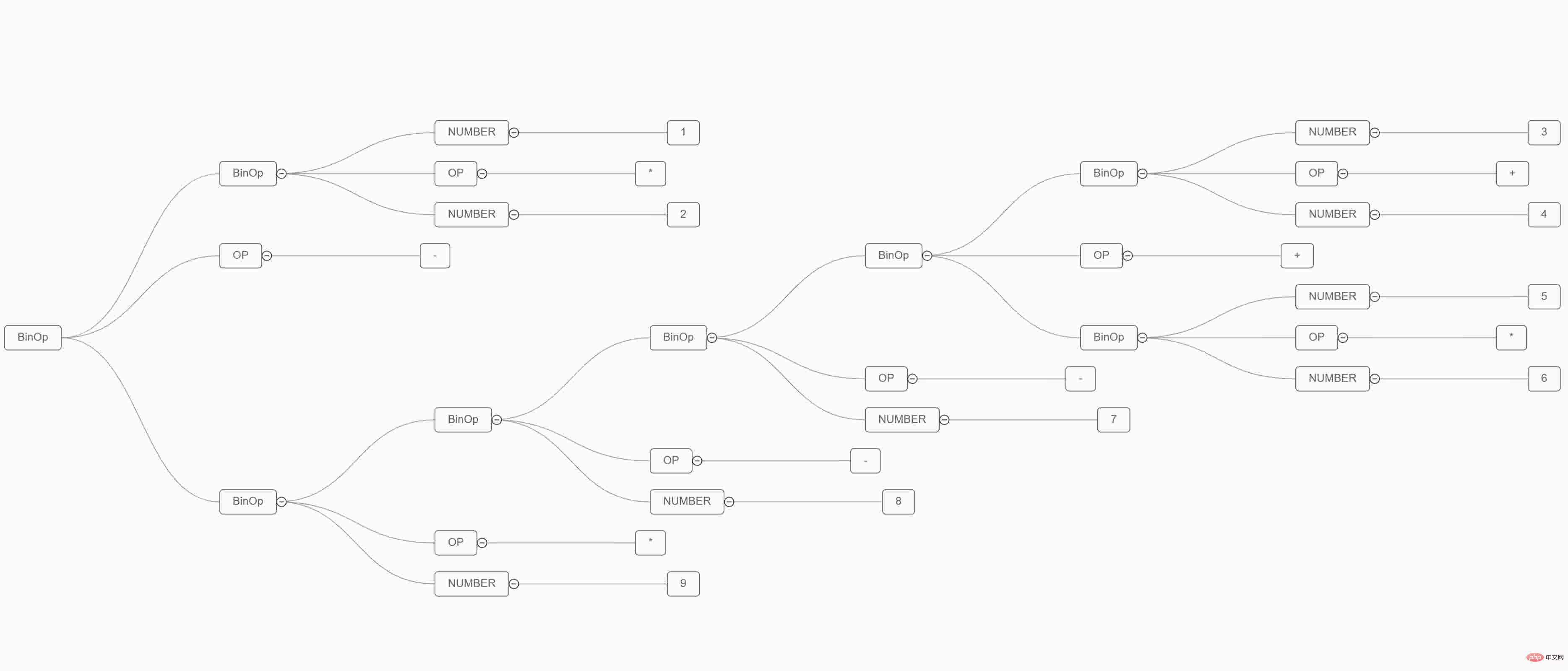
这个格式化的 JSON 信息太长了,不利于直接看到。我们将它渲染出来看最后生成的树形图(方法见前两个博客)。保存下面这个 JSON 在一个文件中,这里我叫做 demo.json,然后执行如下命令:pytm-cli -d LR -i demo.json -o demo.html,然后再浏览器打开生成的 html 文件。

代码
所有的代码都在这里了,只需要一个文件 my_eval.py,想要运行的话,复制、粘贴,然后按照演示的步骤执行即可。
Node、BinOp、Constan 是用来表示节点的类.
Calculator 中 lexizer 方法是进行分词的,本来我是打算使用正则的,如果你看过我前面的博客的话,可以发现我是用的正则来分词的(因为 Python 的官方文档正则表达式中有一个简易的分词程序)。不过我看其他人都是手写的分词,所以我也这样做了,不过感觉并不是很好,很繁琐,而且容易出错。
parse 方法是进行解析的,主要是解析表达式的结构,判断是否符合四则运算的文法,最终生成表达式树(它的 AST)。
"""
Grammar
G -> E
E -> T E'
E' -> '+' T E' | '-' T E' | ɛ
T -> F T'
T' -> '*' F T' | '/' F T' | ɛ
F -> '(' E ')' | num | name
"""
import json
import argparse
class Node:
"""
简单的抽象语法树节点,定义一些需要使用到的具有层次结构的节点
"""
def eval(self) -> float: ... # 节点的计算方法
def visit(self): ... # 节点的访问方法
class BinOp(Node):
"""
BinOp Node
"""
def __init__(self, left, op, right) -> None:
self.left = left
self.op = op
self.right = right
def eval(self) -> float:
if self.op == "+":
return self.left.eval() + self.right.eval()
if self.op == "-":
return self.left.eval() - self.right.eval()
if self.op == "*":
return self.left.eval() * self.right.eval()
if self.op == "/":
return self.left.eval() / self.right.eval()
return 0
def visit(self):
"""
遍历树的各个节点,并生成 JSON 表示
"""
return {
"name": "BinOp",
"children": [
self.left.visit(),
{
"name": "OP",
"children": [
{
"name": self.op
}
]
},
self.right.visit()
]
}
class Constant(Node):
"""
Constant Node
"""
def __init__(self, value) -> None:
self.value = value
def eval(self) -> float:
return self.value
def visit(self):
return {
"name": "NUMBER",
"children": [
{
"name": str(self.value) # 转成字符是因为渲染成图像时,需要该字段为 str
}
]
}
class Calculator:
"""
Simple Expression Parser
"""
def __init__(self, expr) -> None:
self.expr = expr # 输入的表达式
self.parse_end = False # 解析是否结束,默认未结束
self.toks = [] # 解析的 tokens
self.index = 0 # 解析的下标
def lexizer(self):
"""
分词
"""
index = 0
while index < len(self.expr):
ch = self.expr[index]
if ch in [" ", "\r", "\n"]:
index += 1
continue
if '0' <= ch <= '9':
num_str = ch
index += 1
while index < len(self.expr):
n = self.expr[index]
if '0' <= n <= '9':
if ch == '0':
raise Exception("Invalid number!")
num_str = n
index += 1
continue
break
self.toks.append({
"kind": "INT",
"value": int(num_str)
})
elif ch in ['+', '-', '*', '/', '(', ')']:
self.toks.append({
"kind": ch,
"value": ch
})
index += 1
else:
raise Exception("Unkonwn character!")
def get_token(self):
"""
获取当前位置的 token
"""
if 0 <= self.index < len(self.toks):
tok = self.toks[self.index]
return tok
if self.index == len(self.toks): # token解析结束
return {
"kind": "EOF",
"value": "EOF"
}
raise Exception("Encounter Error, invalid index = ", self.index)
def move_token(self):
"""
下标向后移动一位
"""
self.index += 1
def parse(self) -> Node:
"""
G -> E
"""
# 分词
self.lexizer()
# 解析
expr_tree = self.parse_expr()
if self.parse_end:
return expr_tree
else:
raise Exception("Invalid expression!")
def parse_expr(self):
"""
E -> T E'
E' -> + T E' | - T E' | ɛ
"""
# E -> E E'
left = self.parse_term()
# E' -> + T E' | - T E' | ɛ
while True:
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if tok["kind"] == "EOF":
# 解析结束的标志
self.parse_end = True
break
if kind in ["+", "-"]:
self.move_token()
left = BinOp(left, value, self.parse_term())
else:
break
return left
def parse_term(self):
"""
T -> F T'
T' -> * F T' | / F T' | ɛ
"""
# T -> F T'
left = self.parse_factor()
# T' -> * F T' | / F T' | ɛ
while True:
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if kind in ["*", "/"]:
self.move_token()
right = self.parse_factor()
left = BinOp(left, value, right)
else:
break
return left
def parse_factor(self):
"""
F -> '(' E ')' | num | name
"""
tok = self.get_token()
kind = tok["kind"]
value = tok["value"]
if kind == '(':
self.move_token()
expr_node = self.parse_expr()
if self.get_token()["kind"] != ")":
raise Exception("Encounter Error, expected )!")
self.move_token()
return expr_node
if kind == "INT":
self.move_token()
return Constant(value=value)
raise Exception("Encounter Error, unknown factor: ", kind)
if __name__ == "__main__":
# 添加命令行参数解析器
cmd_parser = argparse.ArgumentParser(
description="Simple Expression Interpreter!")
group = cmd_parser.add_mutually_exclusive_group()
group.add_argument("--tokens", help="print tokens", action="store_true")
group.add_argument("--ast", help="print ast in JSON", action="store_true")
cmd_parser.add_argument(
"expr", help="expression, contains ['+', '-', '*', '/', '(', ')', 'num']")
args = cmd_parser.parse_args()
calculator = Calculator(expr=args.expr)
tree = calculator.parse()
if args.tokens: # 输出 tokens
for t in calculator.toks:
print(f"{t['kind']:3s} ==> {t['value']}")
elif args.ast: # 输出 JSON 表示的 AST
print(json.dumps(tree.visit(), indent=4))
else: # 计算结果
print(tree.eval())总结
本来想在前面说一下为什么叫 my_eval.py,但是感觉看到后面的人不多,那就在这里说好了。如果写了一个复杂的表达式,那么怎么验证是否正确的。这里我们直接利用 Python 这个最完美的解释器就好了,哈哈。这里用 Python 的 eval 函数,你当然是不需要调用这个函数,直接复制计算的表达式即可。我用 eval 函数,只是想表达为什么我的程序会叫 my_eval 这个名字。
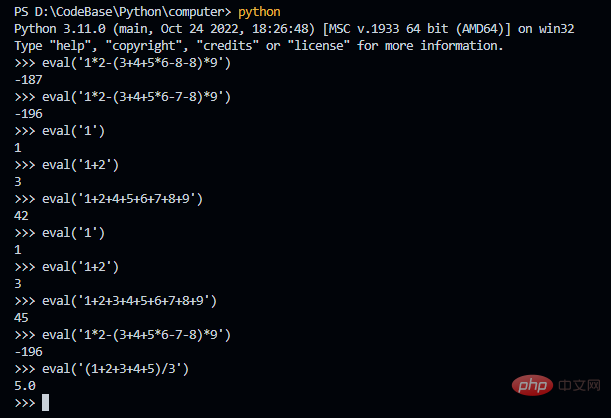
这样实现下来,也算是完成了一个简单的四则运算解释器了。不过,如果你也做一遍的话,也估计会和我一样感觉到整个过程很繁琐。因为分词和语法解析都有现成的工具可以来完成,而且不容易出错,可以大大减少工作量。不过,自己来一遍也是很有必要的,在使用工具之前,至少也要了解工具的作用。
以上是使用Python实现一个简单的四则运算解释器的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
PHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
 PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP起源于1994年,由RasmusLerdorf开发,最初用于跟踪网站访问者,逐渐演变为服务器端脚本语言,广泛应用于网页开发。Python由GuidovanRossum于1980年代末开发,1991年首次发布,强调代码可读性和简洁性,适用于科学计算、数据分析等领域。
 vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上运行,但体验可能不佳。首先确保系统已更新到最新补丁,然后下载与系统架构匹配的VS Code安装包,按照提示安装。安装后,注意某些扩展程序可能与Windows 8不兼容,需要寻找替代扩展或在虚拟机中使用更新的Windows系统。安装必要的扩展,检查是否正常工作。尽管VS Code在Windows 8上可行,但建议升级到更新的Windows系统以获得更好的开发体验和安全保障。
 visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
VS Code 可用于编写 Python,并提供许多功能,使其成为开发 Python 应用程序的理想工具。它允许用户:安装 Python 扩展,以获得代码补全、语法高亮和调试等功能。使用调试器逐步跟踪代码,查找和修复错误。集成 Git,进行版本控制。使用代码格式化工具,保持代码一致性。使用 Linting 工具,提前发现潜在问题。
 notepad 怎么运行python
Apr 16, 2025 pm 07:33 PM
notepad 怎么运行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中运行 Python 代码需要安装 Python 可执行文件和 NppExec 插件。安装 Python 并为其添加 PATH 后,在 NppExec 插件中配置命令为“python”、参数为“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通过快捷键“F6”运行 Python 代码。
 vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
VS Code 扩展存在恶意风险,例如隐藏恶意代码、利用漏洞、伪装成合法扩展。识别恶意扩展的方法包括:检查发布者、阅读评论、检查代码、谨慎安装。安全措施还包括:安全意识、良好习惯、定期更新和杀毒软件。
