

Python在同期群分析中的应用方法

同期群分析
同期群分析概念
同期群(Cohort)的字面意思(有共同特点或举止类同的)一群人,比如不同性别,不同年龄。
同期群分析:比较的是相似群体随时间的变化。
产品会随着你的开发和测试而不断迭代,这就导致在产品发布第一周就加入的用户和后来才加入的用户有着不同的体验。比如,每个用户都会经历一个生命周期:从免费试用,到付费使用,最后停止使用。同时,在这期间里,你还在不停地对商业模式进行调整。于是,在产品上线第一个月就“吃螃蟹”的用户势必与四个月后才加入的用户有着不同的上手体验。这对用户流失率会有什么影响?我们用同期群分析来寻找答案。
每一组用户构成一个同期群,参与整个试验过程。通过比较不同的同期群,你可以获知:从总体上看,关键指标的表现是否越来越好了。
结合到用户分析层面,比如不同月份获取的用户,不同渠道新增用户,具备不同特征的用户(比如微信里每天至少和10个以上朋友微信的用户)。
同期群分析(Cohort Analysis),将这些具有不同特征的人群进行对比分析,以发现他们在时间维度下的行为差异。
因此,同期群分析主要用于以下2点:
对比 不同 同期群群体同一体验周期的数据指标,验证产品迭代优化的效果
对比 同一 同期群群体不同体验周期(生命周期)的数据指标,发现长线体验的问题
我们在进行同期群分析的时候,大致可以划分为2个流程:确定同期群分组逻辑和确定同期群分析的关键数据指标。
具有相似行为特征的群体
具有相同时间周期的群体
例如:
按获客月份(按周甚至按天分组)
按获客渠道
按照用户完成的特定行为,比如用户访问网站的次数或者购买次数来分类。
关于关键数据指标,需要是基于时间维度下的比如留存、营收、自传播系数等等。
下面是以留存率作为指标的案例示例:
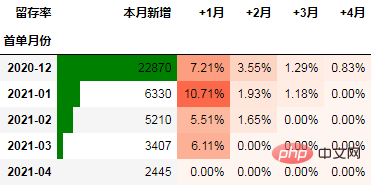
下面是某电商的运营数据,我们将以该数据演示用python进行同期群分析。
同期群分析案例详解:
数据是某电商用户付费日志,日志字段包含日期、付费金额和用户id,已脱敏处理。
数据读取
import pandas as pd df = pd.read_csv('日志.csv', encoding="gb18030") df.head()
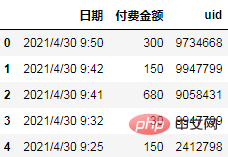
分析方向
分组逻辑:
这里只按照用户的初始购买月份进行分组,如果日志包含的分类字段更多(比如 渠道、性别或者年龄等),可以考虑更多种分组逻辑。
关键数据指标:
针对此份数据,至少有3个数据指标可以进行分析:
留存率
人均付款金额
人均购买次数
数据预处理
因为我们是按照月份进行分组,所以需要先将日期重采样为月份:
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
df.head()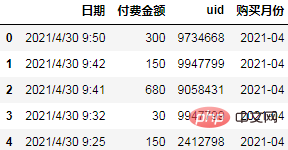
计算每个用户在每个月的付费总额:
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额","sum"),
月付费次数=("uid","count"),
)
order.head()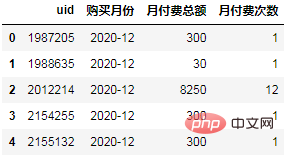
计算每个用户的首单购买月份作为同期群分组,并将其对应到原始数据上:
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order.head()
计算每条购买记录的时间与首单购买时间的月份差,并重置月份差标签:
order["标签"] = (order.购买月份-order.首单月份).apply(lambda x:"同期群人数" if x.n==0 else f"+{x.n}月")
order.head()
两个月份均为时期类型,相减后得到object类型的列,而该列每个元素的类型是pandas._libs.tslibs.offsets.MonthEnd
MonthEnd类型具有属性n能返回具体差值整数。
同期群分析
前面我们说了至少有3个数据指标可以进行分析:
留存率
人均付款金额
人均购买次数
从留存率角度进行同期群分析
通过数据透视表可以一次性计算所需的数据:
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number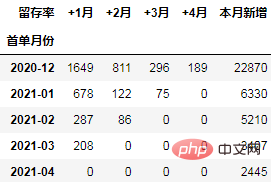
注意:rename_axis(columns=None)用于删除列标签的轴名称。rename_axis(columns=“留存率”)则设置轴名称为留存率。
将 本月新增 列移动到第一列:
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number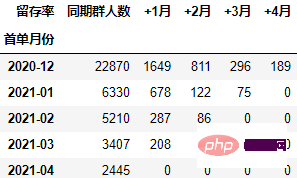
具体过程是先通过pop删除该列,然后插入到0位置,并命名为指定的列名。
在本次的分析中,留存率的具体计算方式为:+N月留存率=+N月付款用户数/首月付款用户数
cohort_number.iloc[:, 1:] = cohort_number.iloc[:, 1:].divide(cohort_number.本月新增, axis=0) cohort_number
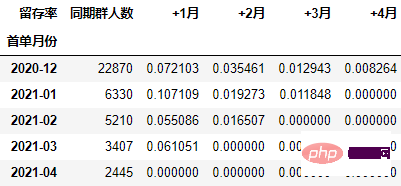
以百分比形式显示,并设置颜色:
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
out1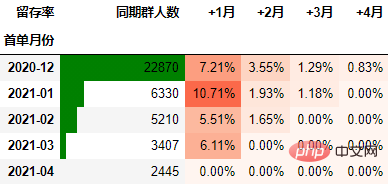
至此计算完毕。
从人均付款金额角度进行同期群分析
要从从人均付款金额角度考虑,需要考虑同期群基期这个整体。具体计算方式是先计算各月的付款总额,然后除以基期的总人数:
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out2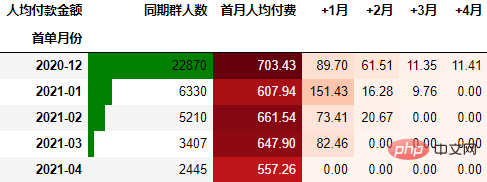
可以看到,12月份的同期群首月新用户人均消费为703.43元,然后逐月递减,到+4月后这些用户人均消费仅11.41元。而随着版本的迭代发展,新增用户的首月消费并没有较大提升,且接下来的消费趋势反而不如12月份。由此可见产品的发展受到了一定的瓶颈,需要思考增长营收的出路了。
一般来说, 通过同期群分析可以比较好指导我们后续更深入细致的数据分析,为产品优化提供参考。
从人均购买次数角度进行同期群分析
依然按照上面一样的套路:
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out3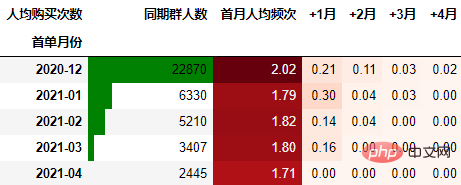
可以得到类似上述一致的结论。
每月总体付费情况
下面我们看看每个月的总体消费情况:
order.groupby("购买月份").agg(
付费人数=("uid", "count"),
人均付款金额=("月付费总额", "mean"),
月付费总额=("月付费总额", "sum")
)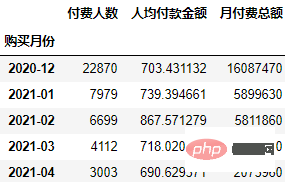
可以看到总体付费人数和付费金额都在逐月下降。
将结果导出网页或截图
对于Styler类型,我们可以调用render方法转化为网页源代码,通过以下方式即可将其导入到一个网页文件中:
with open("out.html", "w") as f:
f.write(out1.render())
f.write(out2.render())
f.write(out3.render())如果你的电脑安装了谷歌游览器,还可以安装dataframe_image,将这个表格导出为图片。
安装:pip install dataframe_image
import dataframe_image as dfi dfi.export(obj=out1, filename='留存率.jpg') dfi.export(obj=out2, filename='人均付款金额.jpg') dfi.export(obj=out3, filename='人均购买次数.jpg')
dfi.export的参数:
obj : 被导出的Datafream对象
filename : 文件保存位置
fontsize : 字体大小
max_rows : 最大行数
max_cols : 最大列数
table_conversion : 使用谷歌游览器或原生’matplotlib’, 只要写非’chrome’的值就会使用原生’matplotlib’
chrome_path : 指定谷歌游览器位置
整体完整代码
import pandas as pd
import dataframe_image as dfi
df = pd.read_csv('日志.csv', encoding="gb18030")
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额", "sum"),
月付费次数=("uid", "count"),
)
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order["标签"] = (
order.购买月份-order.首单月份).apply(lambda x: "同期群人数" if x.n == 0 else f"+{x.n}月")
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number.iloc[:, 1:] = cohort_number.iloc[:,1:].divide(cohort_number.同期群人数, axis=0)
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
outs = [out1, out2, out3]
with open("out.html", "w") as f:
for out in outs:
f.write(out.render())
display(out)
dfi.export(obj=out1, filename='留存率.jpg')
dfi.export(obj=out2, filename='人均付款金额.jpg')
dfi.export(obj=out3, filename='人均购买次数.jpg')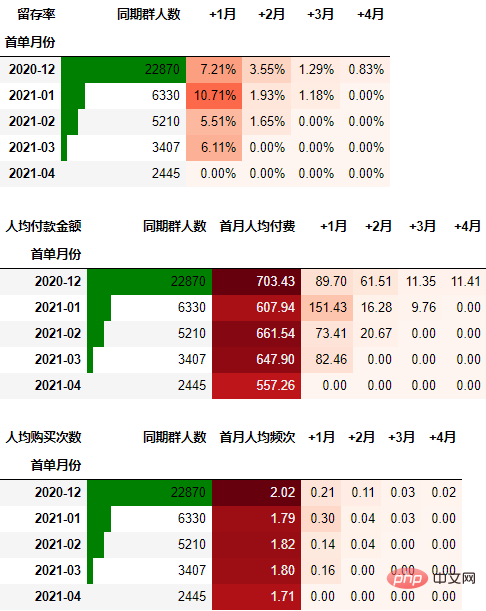
以上是Python在同期群分析中的应用方法的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 PHP和Python:代码示例和比较
Apr 15, 2025 am 12:07 AM
PHP和Python:代码示例和比较
Apr 15, 2025 am 12:07 AM
PHP和Python各有优劣,选择取决于项目需求和个人偏好。1.PHP适合快速开发和维护大型Web应用。2.Python在数据科学和机器学习领域占据主导地位。
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
 Python vs. JavaScript:社区,图书馆和资源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社区,图书馆和资源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社区、库和资源方面的对比各有优劣。1)Python社区友好,适合初学者,但前端开发资源不如JavaScript丰富。2)Python在数据科学和机器学习库方面强大,JavaScript则在前端开发库和框架上更胜一筹。3)两者的学习资源都丰富,但Python适合从官方文档开始,JavaScript则以MDNWebDocs为佳。选择应基于项目需求和个人兴趣。
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 minio安装centos兼容性
Apr 14, 2025 pm 05:45 PM
minio安装centos兼容性
Apr 14, 2025 pm 05:45 PM
MinIO对象存储:CentOS系统下的高性能部署MinIO是一款基于Go语言开发的高性能、分布式对象存储系统,与AmazonS3兼容。它支持多种客户端语言,包括Java、Python、JavaScript和Go。本文将简要介绍MinIO在CentOS系统上的安装和兼容性。CentOS版本兼容性MinIO已在多个CentOS版本上得到验证,包括但不限于:CentOS7.9:提供完整的安装指南,涵盖集群配置、环境准备、配置文件设置、磁盘分区以及MinI
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
 CentOS上PyTorch版本怎么选
Apr 14, 2025 pm 06:51 PM
CentOS上PyTorch版本怎么选
Apr 14, 2025 pm 06:51 PM
在CentOS系统上安装PyTorch,需要仔细选择合适的版本,并考虑以下几个关键因素:一、系统环境兼容性:操作系统:建议使用CentOS7或更高版本。CUDA与cuDNN:PyTorch版本与CUDA版本密切相关。例如,PyTorch1.9.0需要CUDA11.1,而PyTorch2.0.1则需要CUDA11.3。cuDNN版本也必须与CUDA版本匹配。选择PyTorch版本前,务必确认已安装兼容的CUDA和cuDNN版本。Python版本:PyTorch官方支
 CentOS上如何更新PyTorch到最新版本
Apr 14, 2025 pm 06:15 PM
CentOS上如何更新PyTorch到最新版本
Apr 14, 2025 pm 06:15 PM
在CentOS上更新PyTorch到最新版本,可以按照以下步骤进行:方法一:使用pip升级pip:首先确保你的pip是最新版本,因为旧版本的pip可能无法正确安装最新版本的PyTorch。pipinstall--upgradepip卸载旧版本的PyTorch(如果已安装):pipuninstalltorchtorchvisiontorchaudio安装最新
