
根据Solanki、Nayyar和Naved在论文中提供的定义,图像到图像的翻译是将图像从一个域转换到另一个域的过程,其目标是学习输入图像和输出图像之间的映射。
换句话说,我们希望模型能够通过学习映射函数f将一张图像a转换成另一张图像b。

有人可能会想,这些模型有什么用,它们在人工智能世界有什么关联。应用程序往往有很多,这不仅仅限于艺术或平面设计领域。例如,能够拍摄图像并将其转换为另一个图像来创建合成数据(如分割图像),这对训练自动驾驶汽车模型非常有用。另一个经过测试的应用程序是地图设计,其中模型能够执行两种转换(卫星视图到地图,反之亦然)。图像翻转换型也可以应用于建筑,模型可以就如何完成未完成的项目提出建议。
图像转换最引人注目的应用之一是将简单的绘图转换为美丽的风景或绘画。
在过去几年中,已经开发出几种方法,通过利用生成模型来解决图像到图像转换的问题。最常用的方法基于以下体系结构:
Pix2Pix是一个基于条件GAN的模型。这意味着它的架构是由Generator网络(G)和Discriminator (D)组成的。这两个网络都是在对抗性游戏中训练的,其中G的目标是生成与数据集相似的新图像,而D必须决定图像是生成的(假)还是来自数据集(真)。
Pix2Pix和其他GAN模型之间的主要区别是:(1)第一个Generator将图像作为输入来启动生成过程,而普通GAN使用随机噪声;(2)Pix2Pix是一个完全监督模型,这意味着数据集由来自两个域的成对图像组成。
论文中描述的体系结构是由一个用于生成器的U-Net和用于Discriminator的Markovian Discriminator或Patch Discriminator定义的:
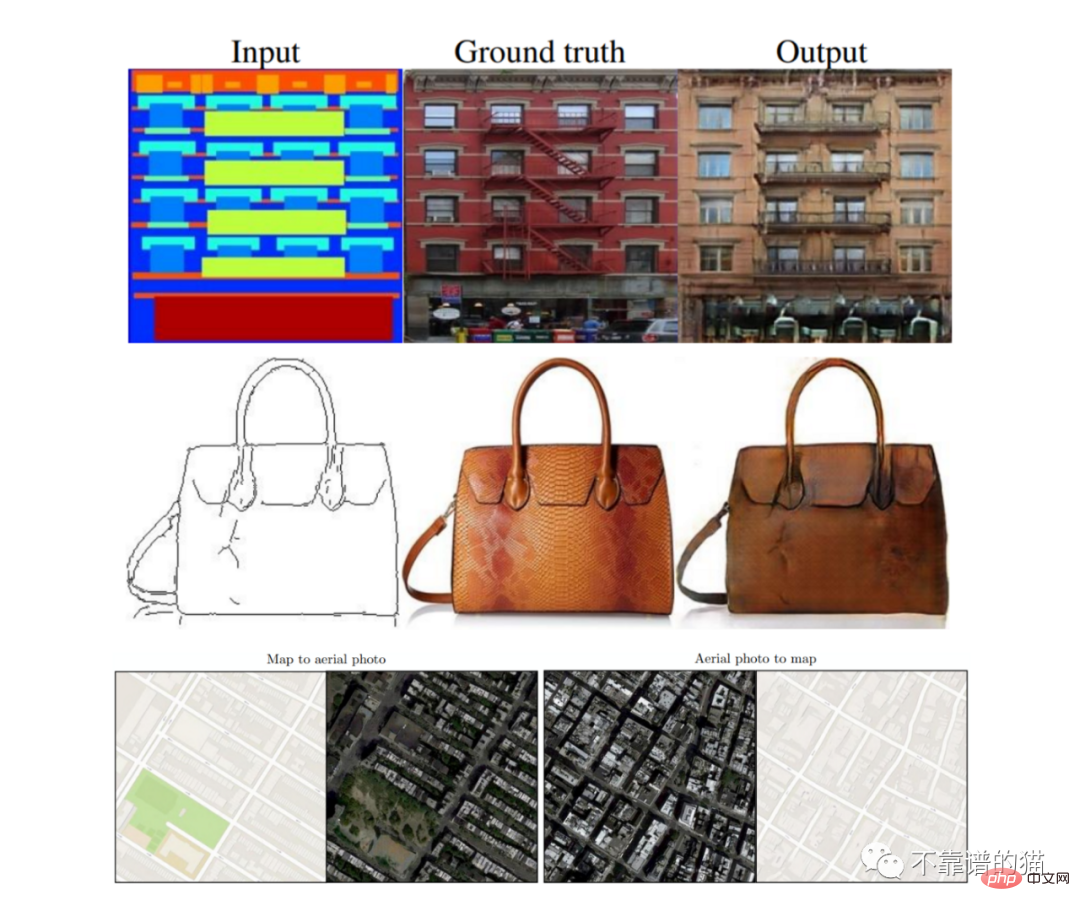
Pix2Pix结果
在Pix2Pix中,训练过程是完全监督的(即我们需要成对的图像输入)。UNIT方法的目的是学习将图像A映射到图像B的函数,而不需要训练两个成对的图像。
该模型从假设两个域(A和B)共享一个共同的潜在空间(Z)开始。直观地说,我们可以将这个潜在空间视为图像域A和B之间的中间阶段。因此,使用从绘画到图像的例子,我们可以使用相同的潜在空间向后生成绘画图像或向前看到令人惊叹的图像(见图X)。
图中:(a)共享潜空间。(b)UNIT架构:X1是一幅图画,X2是一幅美丽的风景;E1, E2是编码器,从两个域(绘图和风景)提取图像,并将它们映射到共享潜在空间Z;G1, G2发生器,D1, D2判别器。虚线表示网络之间的共享层。
UNIT模型是在一对VAE-GAN架构下开发的(见上图),其中编码器的最后一层(E1, E2)和生成器的第一层(G1, G2)是共享的。

UNIT结果
Palette是加拿大谷歌研究小组开发的条件扩散模型。该模型经过训练,可执行与图像转换相关的4项不同任务,从而获得高质量的结果:
(i)着色:为灰度图像添加颜色
(ii)Inpainting:用逼真的内容填充用户指定的图像区域
(iii)Uncropping:放大图像帧
(iv)JPEG恢复:恢复损坏的JPEG图像
在论文中,作者探讨了多任务通用模型和多个专门模型之间的区别,两者都经过一百万次迭代训练。该模型的体系结构基于Dhariwal和Nichol 2021的类条件U-Net模型,使用1024个批次大小的图像进行1M的训练步骤。将噪声计划作为超参数进行预处理和调整,使用不同的计划进行训练和预测。

Palette结果
请注意,尽管以下两个模型并不是专门为图像转换设计的,但它们在将诸如transformers等功能强大的模型引入计算机视觉领域方面迈出了明显的一步。
Vision Transformers(ViT)是对Transformers架构的修改(Vaswani等人,2017年),是为图像分类而开发的。该模型将图像作为输入,并输出属于每个已定义类的概率。
主要问题在于Transformers被设计成以一维序列作为输入,而不是二维矩阵。为了进行排序,作者建议将图像分割为小块,将图像视为序列(或NLP中的句子),小块视为标记(或单词)。
简单总结一下,我们可以将整个过程分为3个阶段:
1)嵌入:将小块拆分并flatten→应用线性变换→添加类标记(此标记将作为分类时考虑的图像摘要)→位置嵌入
2)Transformer-Encoder块:将嵌入的patches放入一系列变transformer encoder块中。注意力机制会学习关注图像的哪些部分。
3)分类MLP头:将类令牌通过MLP头,该MLP头输出图像属于每个类的最终概率。
使用ViT的优点:排列不变。与CNN相比,Transformer不受图像中的平移(元素位置的变化)的影响。
缺点:需要大量标记数据进行训练(至少14M的图像)
TransGAN是一个基于transform的GAN模型,设计用于图像生成,不使用任何卷积层。相反,生成器和鉴别器是由一系列由上采样和下采样块连接的Transformer组成的。
生成器的正向过程取一个一维数组的随机噪声样本,并将其通过MLP。直观地说,我们可以把数组想象成一个句子,像素的值想象成单词(请注意,一个由64个元素组成的数组可以重塑为1个通道的8✕8的图像)接下来,作者应用了一系列Transformer块,每个块后面都有一个上采样层,使数组(图像)的大小增加一倍。
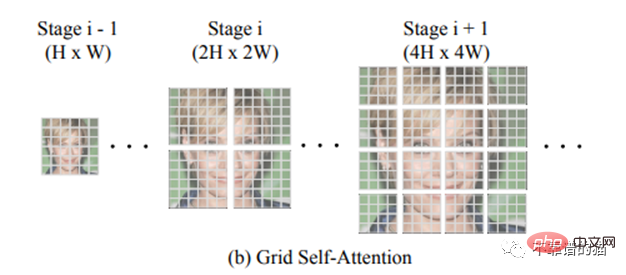
TransGAN的一个关键特征是Grid-self - attention。当达到高维图像(即非常长的数组32✕32 = 1024)时,应用transformer可能导致自注意力机制的爆炸性成本,因为您需要将1024数组的每个像素与所有255个可能的像素进行比较(RGB维度)。因此,网格自注意力不是计算给定标记和所有其他标记之间的对应关系,而是将全维度特征映射划分为几个不重叠的网格,并且在每个局部网格中计算标记交互。
判别器体系结构与前面引用的ViT非常相似。

不同数据集上的TransGAN结果
以上是五个有前途的AI模型用于图像翻译的详细内容。更多信息请关注PHP中文网其他相关文章!





















