

使用 GPT-3 构建符合业务需求的企业聊天机器人


背景
聊天机器人或客服助手是AI工具,希望通过互联网上的文本或语音与用户的交付,实现业务价值。聊天机器人的发展在这几年间迅速进步,从最初的基于简单逻辑的机器人到现在基于自然语言理解(NLU)的人工智能。对于后者,构建此类聊天机器人时最常用的框架或库包括国外的RASA、Dialogflow和Amazon Lex等,以及国内大厂百度、科大讯飞等。这些框架可以集成自然语言处理(NLP)和NLU来处理输入文本、分类意图并触发正确的操作以生成响应。
随着大型语言模型(LLM)的出现,我们可以直接使用这些模型构建功能齐全的聊天机器人。其中一个著名的LLM例子是来自OpenAI的生成Generative Pre-trained Transformer 3 (GPT-3:chatgpt就是基于gpt fine-tuning及加入人类反馈模型的),它可以通过使用对话或会话数据来fine-tuning模型,生成类似于自然对话的文本。这种能力使其成为构建自定义聊天机器人的最佳选择。
今天我们来聊如何通过fine-tuning GPT-3模型来构建满足属于我们自己的简单会话聊天机器人。
通常,我们希望在自己的业务对话示例的数据集上fine-tuning模型,例如客户服务的对话记录、聊天日志或电影中的字幕。fine-tuning过程调整模型的参数,让它更好地适应这些会话数据,从而使聊天机器人更擅长理解和回复用户输入。
要fine-tuningGPT-3,我们可以使用Hugging Face的Transformers库,该库提供了预训练模型和fine-tuning工具。该库提供了几种不同大小和较多能力的GPT-3模型。模型越大,可以处理的数据就越多,精度也可能越高。但是,为了简单起见,我们这次使用的是OpenAI接口,可通过编写少量的代码来实现fine-tuning。
接下来就是我们使用OpenAI GPT-3 来实现fine-tuning,可从这获取数据集,抱歉我又用国外数据集了,国内真的很少这类已经处理好的数据集。
1、创建Open API密匙
创建帐户非常简单,可以使用打开这个链接就可以完成。我们可以通过openai key访问 OpenAI 上的模型。创建API 密钥步骤如下:
- 登录到您的帐户
- 转到页面的右上角,然后单击帐户名,下拉列表,然后单击“查看 API 密钥”
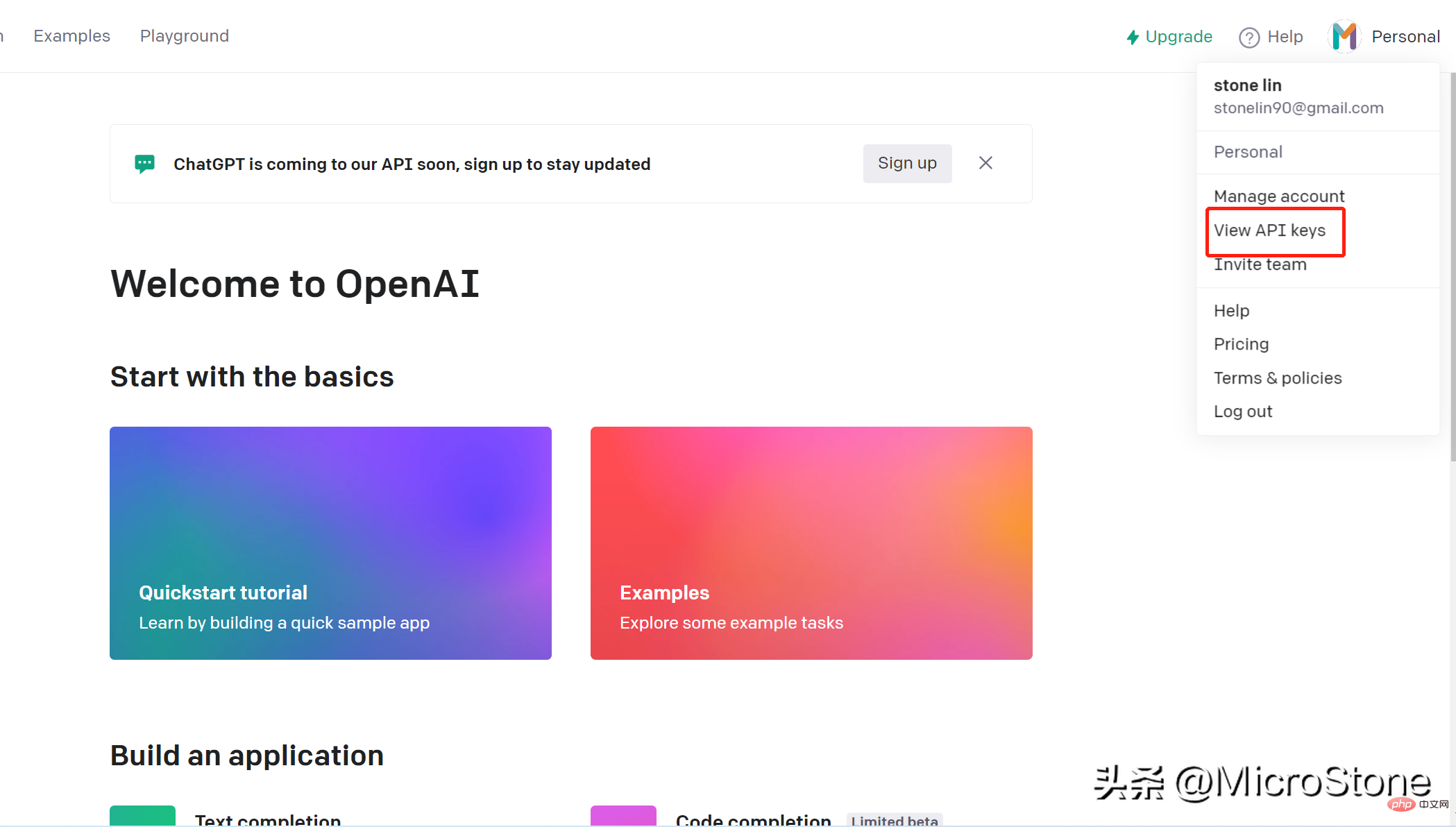
- 单击“创建新密钥”,记得马上复制生成的密钥,切记,并保存好,不然无法再次查看它。
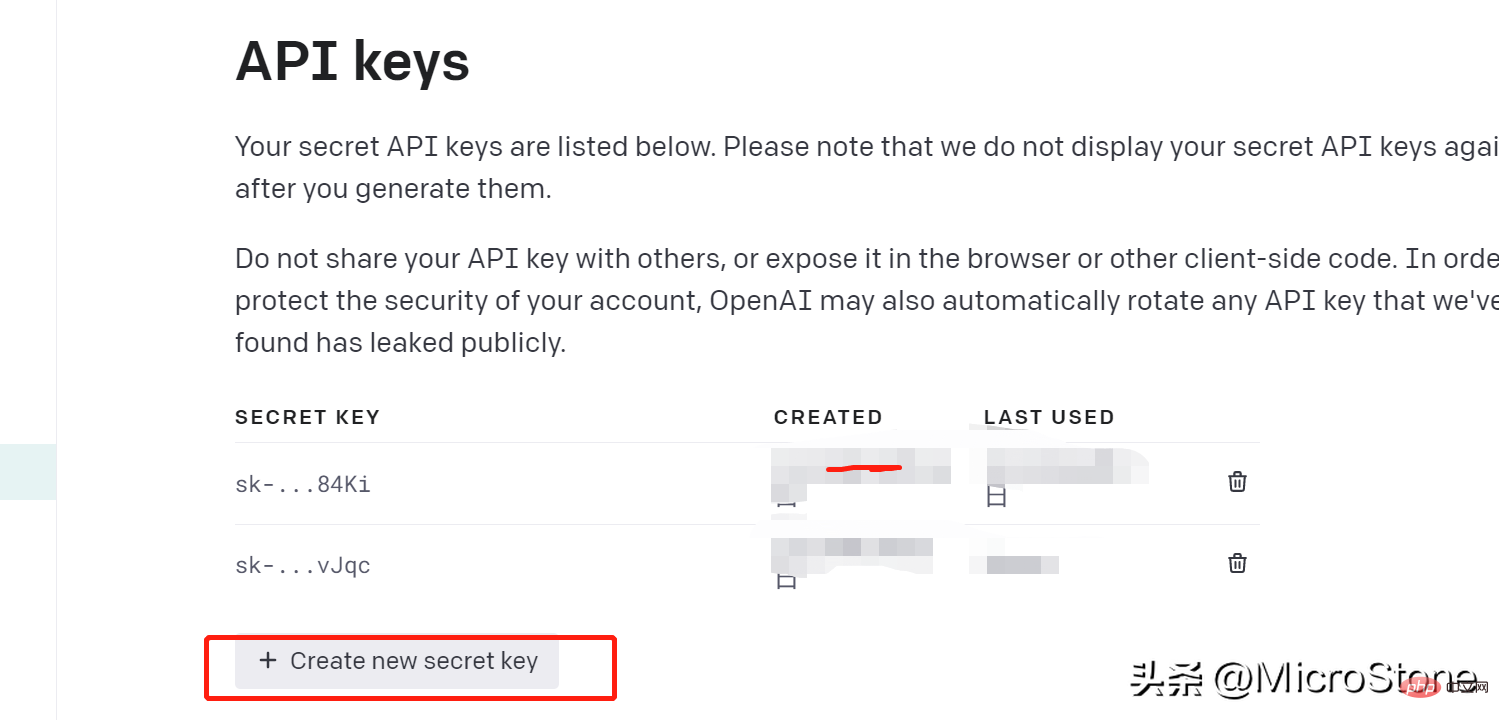
2、准备数据
我们已经创建了api密匙,那么我们可以开始准备fine-tuning模型的数据,在这可以查看数据集。

第一步:
安装 OpenAI 库pip install openai
安装后,我们就可以加载数据了:
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))我们将问题加载到Interview AI列中,并将相应的答案加载到Human列中。我们还需要创建一个环境变量.env文件来保存OPENAI_API_KEY
接下来,我们将数据转换为 GPT-3 的标准。根据文档,确保数据采用JSONL具有两个键的格式,这个很重要:prompt例如completion
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }重新构造数据集以适应以上方式,基本是循环遍历数据框中的每一行,并将文本分配给Human,将Interview AI文本分配给完成。
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')使用prepare_data命令,这时会在提示时询问一些问题,我们可以提供Y或N回复。
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")最后,一个名为的文件data_prepared.jsonl被转储到目录中。
3、fun-tuning 模型
要fun-tuning模型,我们只需要运行一行命令:
os .system( "openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci " )
这基本上使用准备好的数据从 OpenAI 训练davinci模型,fine-tuning后的模型将存储在用户配置文件下,可以在模型下的右侧面板中找到。
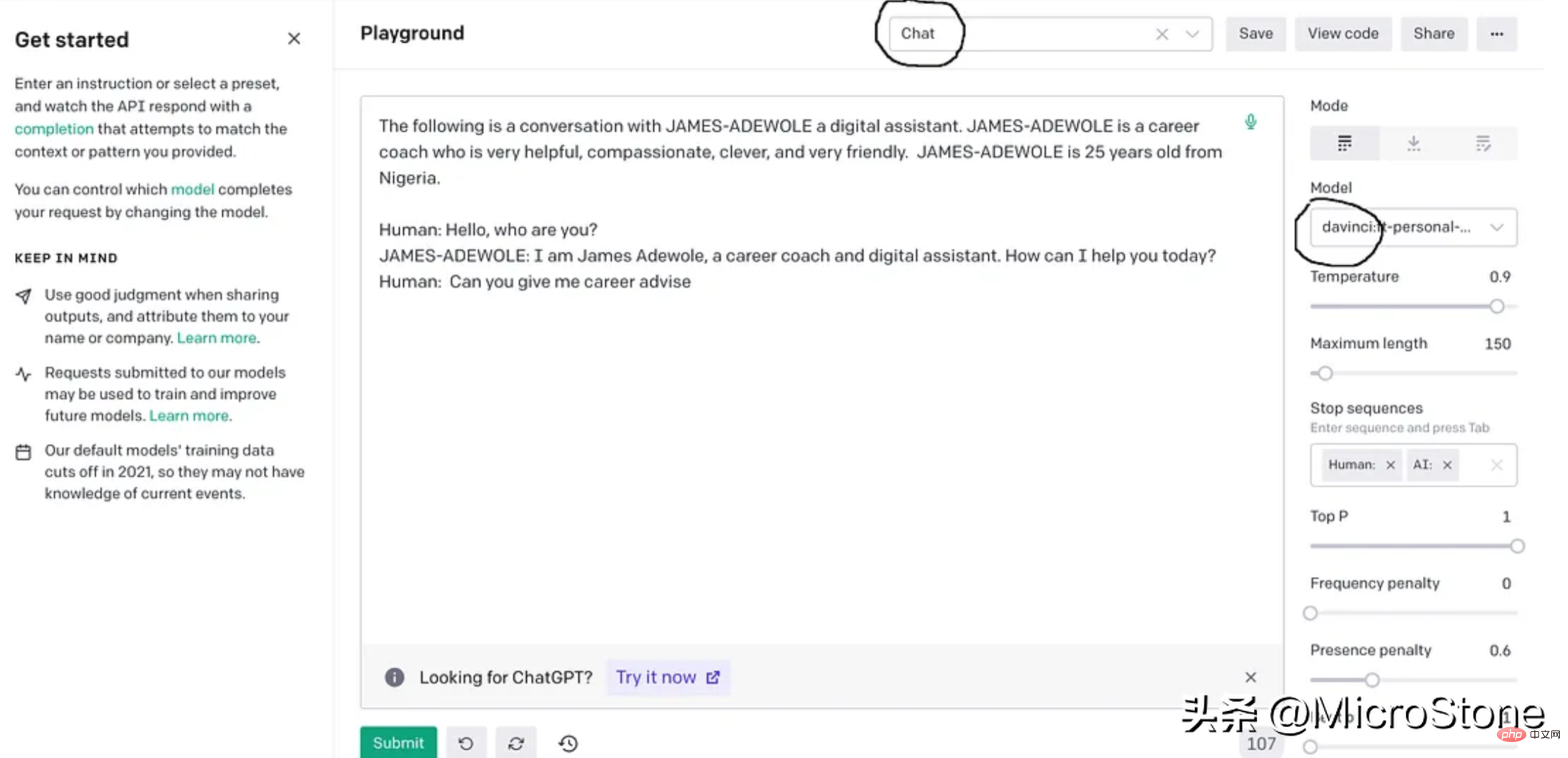
4、模型调试
我们可以使用多种方法来验证我们的模型。可以直接从 Python 脚本、OpenAI Playground 来测试,或者使用 Flask 或 FastAPI 等框构建 Web 服务来测试。
我们先构建一个简单的函数来与此实验的模型进行交互。
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()
output = generate_response(input_text)
print(output)把它们放在一起。
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")
os.system("openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci ")
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()示例响应:
input_text = "what is breadth first search algorithm" output = generate_response(input_text)
The breadth-first search (BFS) is an algorithm for discovering all the reachable nodes from a starting point in a computer network graph or tree data structure
结论
GPT-3 是一种强大的大型语言生成模型,最近火到无边无际的chatgpt就是基于GPT-3上fine-tuning的,我们也可以对GPT-3进行fine-tuning,以构建适合我们自己业务的聊天机器人。fun-tuning过程调整模型的参数可以更好地适应业务对话数据,让机器人更善于理解和响应业务的需求。经过fine-tuning的模型可以集成到聊天机器人平台中以处理用户交互,还可以为聊天机器人生成客服回复习惯与用户交互。整个实现可以在这里找到,数据集可以从这里下载。
以上是使用 GPT-3 构建符合业务需求的企业聊天机器人的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 开发者必备的五类AI工具,不容错过!
Dec 04, 2023 pm 02:25 PM
开发者必备的五类AI工具,不容错过!
Dec 04, 2023 pm 02:25 PM
在当今快节奏和激烈竞争的时代,提高工作效率和产品质量变得尤为重要。作为软件开发者,也必须紧跟现代化工具的步伐,以保持领先优势。在这篇文章中,我总结了2023年开发者必备的5类人工智能工具,这些工具将帮助您提升工作效率、优化代码质量,从而在激烈的市场竞争中脱颖而出一.代码补全和预测TabNineTabNine是一种智能代码补全工具,基于OpenAI的GPT模型。它能够根据上下文和用户的习惯预测代码的补全内容,从而提高编码效率。TabNine支持多种主流的集成开发环境(IDE)和编辑器,如Visua
 小红书开始测试AI聊天机器人'达芬奇”
Jan 15, 2024 pm 12:42 PM
小红书开始测试AI聊天机器人'达芬奇”
Jan 15, 2024 pm 12:42 PM
小红书正在努力通过增加更多的人工智能功能来丰富其产品根据国内媒体报道,小红书正在其主App中内测一款名为“Davinci”的AI应用。据悉,该应用能够为用户提供智能问答等AI聊天服务,其中包括旅游攻略、美食攻略、地理文化常识、生活技巧、个人成长和心理建设等等据报道,"Davinci"是使用Meta旗下的LLAMA模型进行训练的产品,该产品从今年9月开始测试至今。有传言称,小红书之前还在进行一项群AI对话功能的内测。在这个功能下,用户可以在群聊中创建或引入AI角色,并与其进行对话和互动图片来源:T
 DeepSeek深度思考和联网搜索都是什么意思
Feb 19, 2025 pm 04:09 PM
DeepSeek深度思考和联网搜索都是什么意思
Feb 19, 2025 pm 04:09 PM
DeepSeekAI工具深度解析:深度思考与联网搜索功能详解DeepSeek是一款功能强大的AI智能互动工具,本文将重点介绍其“深度思考”和“联网搜索”两大核心功能,帮助您更好地理解和使用这款工具。DeepSeek核心功能解读:深度思考:DeepSeek的“深度思考”功能并非简单的信息检索,而是基于庞大的预训练知识库和强大的逻辑推理能力,对复杂问题进行多维度、结构化分析。它模拟人类思维模式,高效、全面地提供逻辑严谨、条理清晰的答案,并能有效避免情感偏见。联网搜索:“联网搜索”功
 如何使用ChatGPT和Java开发智能聊天机器人
Oct 28, 2023 am 08:54 AM
如何使用ChatGPT和Java开发智能聊天机器人
Oct 28, 2023 am 08:54 AM
在这篇文章中,我们将介绍如何使用ChatGPT和Java开发智能聊天机器人,并提供一些具体的代码示例。ChatGPT是由OpenAI开发的困境预测转换(GenerativePre-trainingTransformer)的最新版本,它是一种基于神经网络的人工智能技术,可以理解自然语言并生成人类类似的文本。使用ChatGPT,我们可以轻松地创建自适应的聊天
 deepseek生成图片教程
Feb 19, 2025 pm 04:15 PM
deepseek生成图片教程
Feb 19, 2025 pm 04:15 PM
DeepSeek:强大的AI图像生成利器!DeepSeek本身并非图像生成工具,但其强大的核心技术为众多AI绘画工具提供了底层支持。想知道如何利用DeepSeek间接生成图片吗?请继续阅读!利用基于DeepSeek的AI工具生成图像:以下步骤将引导您使用这些工具:启动AI绘画工具:在您的电脑、手机浏览器或微信小程序中搜索并打开一个基于DeepSeek的AI绘画工具(例如,搜索“简单AI”)。选择绘画模式:选择“AI绘图”或类似功能,并根据您的需求选择图片类型,例如“动漫头像”、“风景
 如何使用Java开发一个基于人工智能的智能聊天机器人
Sep 21, 2023 am 10:45 AM
如何使用Java开发一个基于人工智能的智能聊天机器人
Sep 21, 2023 am 10:45 AM
如何使用Java开发一个基于人工智能的智能聊天机器人随着人工智能技术的不断发展,智能聊天机器人在各类应用场景中得到越来越广泛的应用。开发一个基于人工智能的智能聊天机器人既能提升用户体验,也可以为企业节省人力成本。本文将介绍如何使用Java语言开发一个基于人工智能的智能聊天机器人,并提供具体的代码示例。确定机器人的功能和领域在开发智能聊天机器人之前,首先需要确
 ChatGPT和Python的完美结合:打造实时聊天机器人
Oct 28, 2023 am 08:37 AM
ChatGPT和Python的完美结合:打造实时聊天机器人
Oct 28, 2023 am 08:37 AM
ChatGPT和Python的完美结合:打造实时聊天机器人导言:随着人工智能技术的快速发展,聊天机器人在各个领域中扮演着越来越重要的角色。聊天机器人可以帮助用户提供即时且个性化的帮助,同时也可以为企业提供高效的客户服务。本文将介绍如何使用OpenAI的ChatGPT模型和Python语言相结合,打造一个实时聊天机器人,并提供具体的代码示例。一、ChatGPT
 小红书内测达芬奇AI聊天机器人'Davinic”
Jan 05, 2024 pm 10:57 PM
小红书内测达芬奇AI聊天机器人'Davinic”
Jan 05, 2024 pm 10:57 PM
站长之家(ChinaZ.com)12月25日消息:据Tech星球消息,小红书在其主APP中内测了一个名为“Davinic”(达芬奇)的AI功能。这项功能自9月开始测试,至今仍在持续,这也是继AI群聊后,小红书推出的又一项新的AI应用。"Davinic"主要为用户提供智能问答等AI聊天功能。"Davinic"更专注于提供关于好物生活的问答,包括旅游攻略、美食攻略、地理和文化知识、生活技巧、个人成长和心理建议,以及活动推荐等多个领域根据报道,"Davinic"是通过基于Meta旗下的LLAMA大模型
