
本文介绍的是达摩院魔搭社区 ModelScope 近期开源的中文 CLIP 大规模预训练图文表征模型,更加懂中文和中文互联网的图像,在图文检索、零样本图片分类等多个任务中实现最优效果,同时代码和模型已经全部开源,用户能够使用魔搭快速上手。

在当下的互联网生态中,多模态相关任务和场景简直数不胜数,如图文检索、图片分类、视频和图文内容等场景。近年火爆全网的图片生成更是热度蹿升,迅速出圈。这些任务的背后,一个强大的图文理解模型显然是必须的。OpenAI 在 2021 年推出的 CLIP 模型,相信大家都不会陌生,通过简单的图文双塔对比学习和大量的图文语料,使模型具有了显著的图文特征对齐能力,在零样本图像分类、跨模态检索中效果拔群,也被作为 DALLE2、Stable Diffusion 等图片生成模型的关键模块。
但很可惜的是,OpenAI CLIP 的预训练主要使用英文世界的图文数据,不能天然支持中文。即便是社区有研究者通过翻译的文本,蒸馏出多语言版本的 Multilingual-CLIP (mCLIP),同样无法很好满足中文世界的需求,对于中文领域的文本理解不很到位,比如搜索“春节对联”,返回的却是圣诞相关的内容:

mCLIP 检索 demo 搜索 “春节对联” 返回结果
这也说明,我们需要一个更懂中文的 CLIP,不仅懂我们的语言,也更懂中文世界的图像。
达摩院的研究人员收集了大规模的中文图文对数据(约 2 亿规模),其中包括来自 LAION-5B 中文子集、Wukong 的中文数据、以及来自 COCO、Visual Genome 的翻译图文数据等。训练图文绝大部分来自公开数据集,大大降低了复现难度。而在训练方法上,为了有效提升模型的训练效率和模型效果,研究人员则设计了两阶段训练的流程:
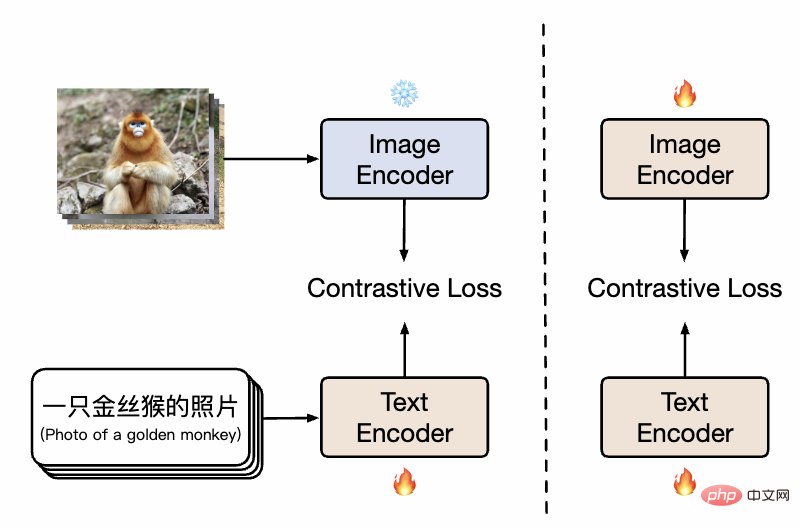
Chinese CLIP 方法示意图
如图所示,在第一阶段,模型使用已有的图像预训练模型和文本预训练模型分别初始化 Chinese-CLIP 的双塔,并冻结图像侧参数,让语言模型关联上已有的图像预训练表示空间,同时减小训练开销。随后,在第二阶段解冻图像侧参数,让图像模型和语言模型关联的同时并建模中文特色的数据分布。研究者发现,相比从头开始做预训练,该方法在多个下游任务上均展现显著更优的实验效果,而其显著更高的收敛效率也意味着更小的训练开销。相比全程只训练文本侧做一阶段训练,加入第二阶段训练能有效在图文下游任务,尤其是中文原生(而非翻译自英文数据集)的图文任务上进一步提升效果。
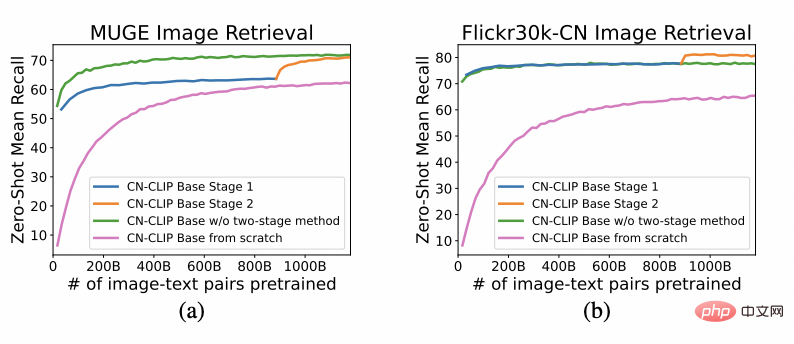
在 MUGE 中文电商图文检索、Flickr30K-CN 翻译版本通用图文检索两个数据集上观察 zero-shot 随着预训练持续进行的效果变化趋势
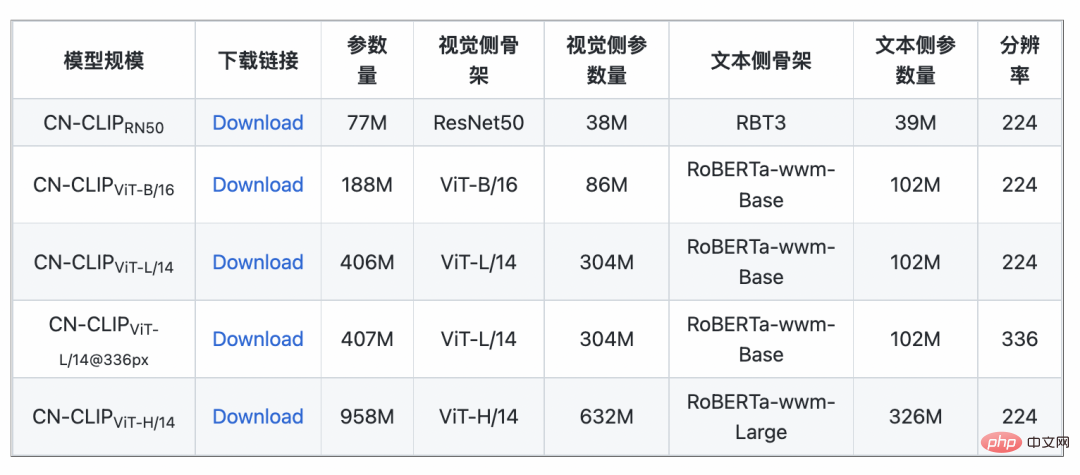
利用这一策略,研究人员训练了多个规模的模型,从最小的 ResNet-50、ViT-Base 和 Large,直到 ViT-Huge 应有尽有,目前已经全部开放,用户完全可以按需使用最适合自身场景的模型:
多项实验数据表明,Chinese-CLIP 可以在中文跨模态检索取得最优表现,其中在中文原生的电商图像检索数据集 MUGE 上,多个规模的 Chinese CLIP 均取得该规模的最优表现。而在英文原生的 Flickr30K-CN 等数据集上,不论是零样本还是微调的设定下,Chinese CLIP 均能显著地超出国内 Wukong、Taiyi、R2D2 等基线模型。这在很大程度上归功于 Chinese-CLIP 更大规模的中文预训练图文语料,以及 Chinese-CLIP 不同于国内现有一些图文表征模型为了最小化训练成本全程冻结图像侧,而是采用两阶段的训练策略的做法,以更好适配中文领域:
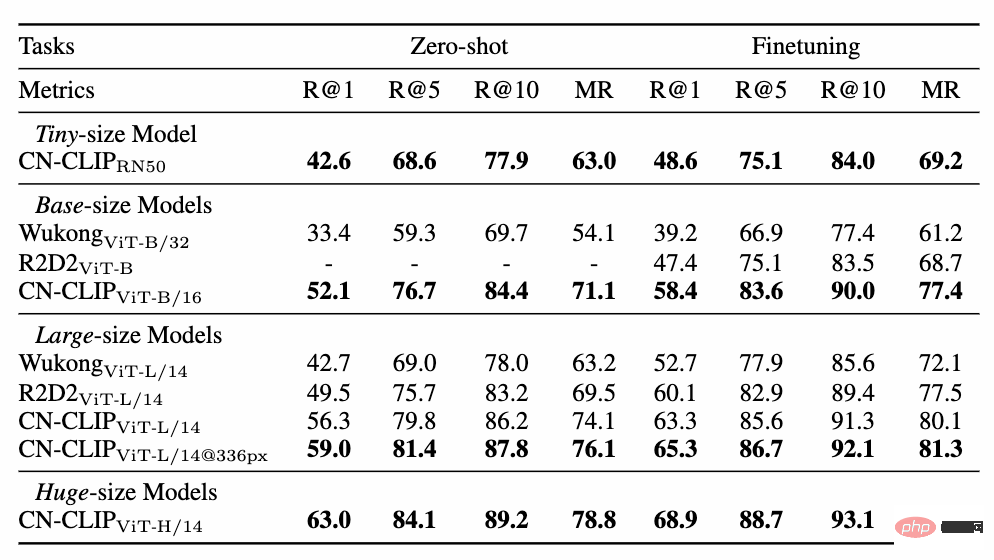
MUGE 中文电商图文检索数据集实验结果
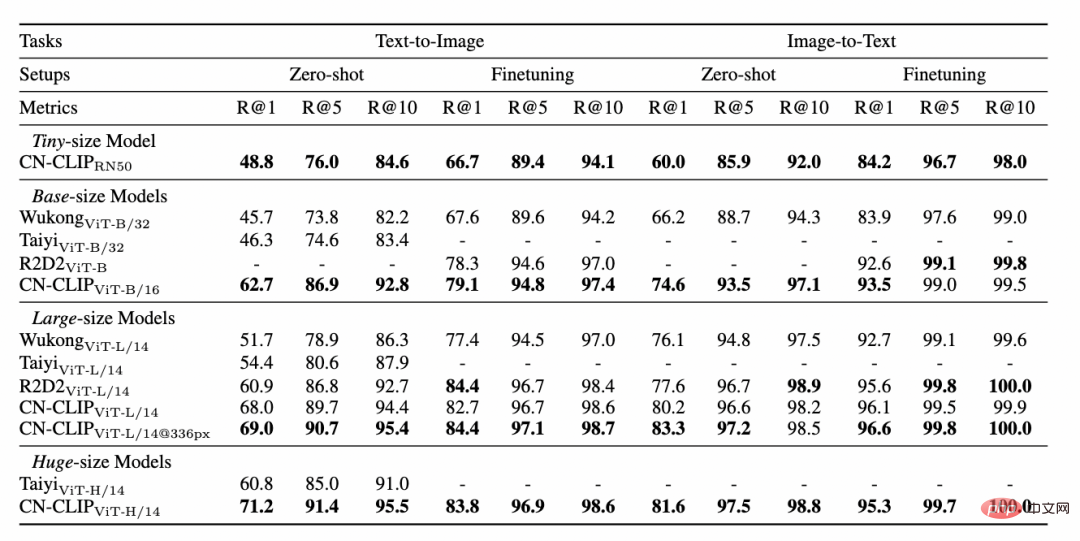
Flickr30K-CN 中文图文检索数据集实验结果
同时,研究人员在零样本图像分类数据集上验证了中文 CLIP 的效果。由于中文领域比较权威的零样本图像分类任务并不多,研究人员目前在英文翻译版本的数据集上进行了测试。Chinese-CLIP 在这些任务上,通过中文的 prompt 和类别标签,能够取得和 CLIP 相当的表现:
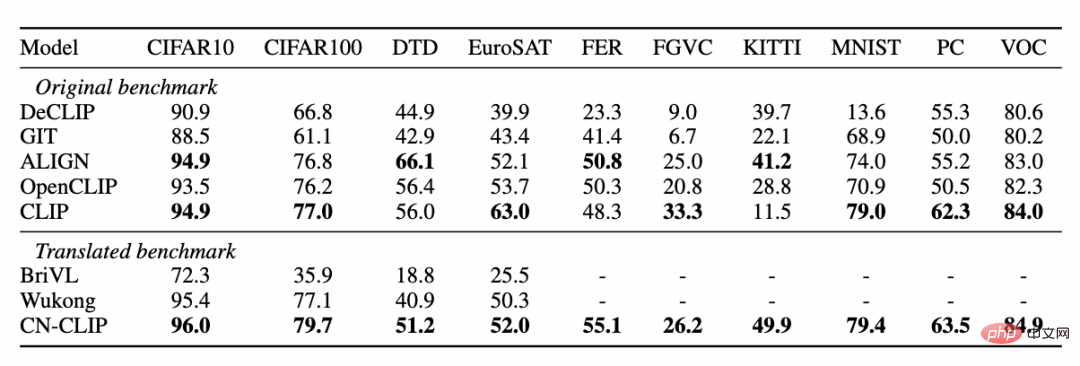
零样本分类实验结果
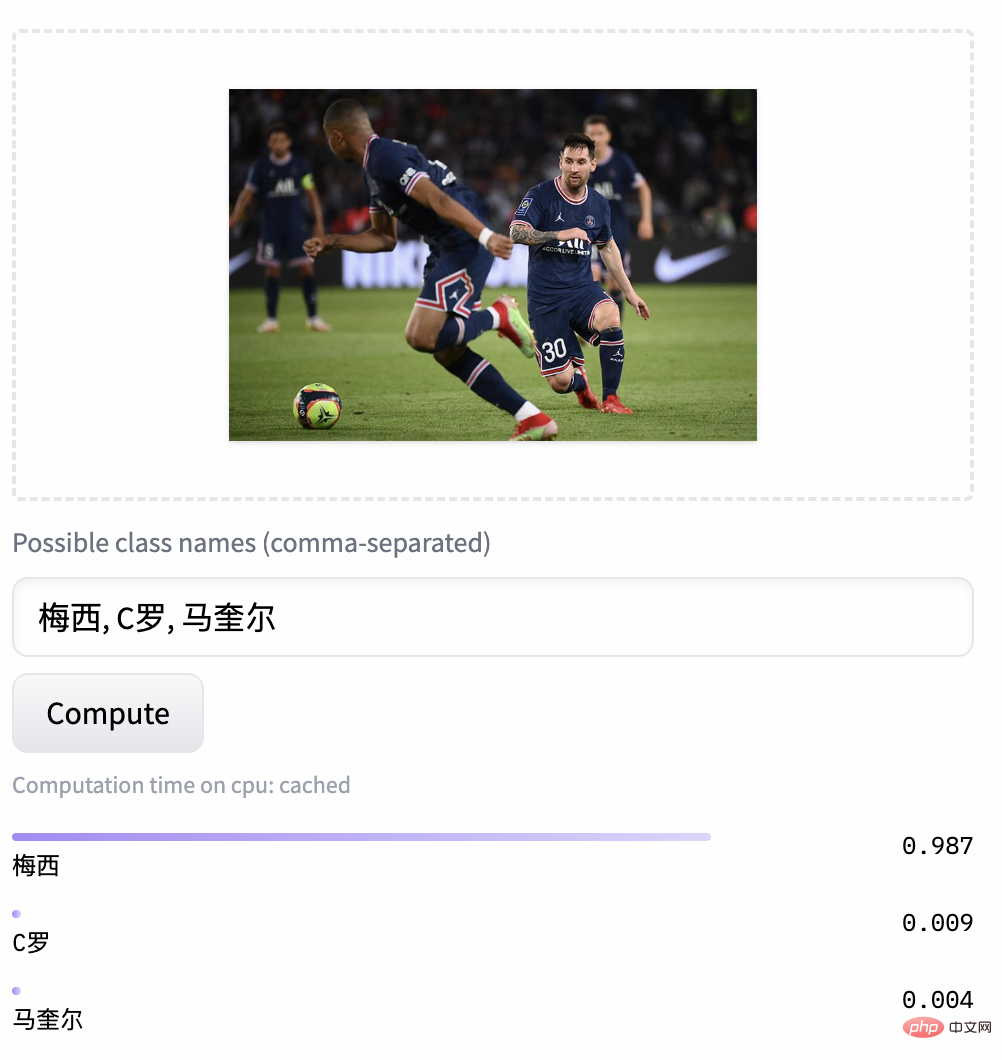
零样本图片分类示例
如何才能用上 Chinese-CLIP ?很简单,点击文章开头的链接访问魔搭社区或使用开源代码,短短几行就能完成图文特征提取和相似度计算了。如需快速使用和体验,魔搭社区提供了配置好环境的 Notebook,点击右上方即可使用。

Chinese-CLIP 也支持用户使用自己的数据进行 finetune,同时还提供了一个图文检索的 demo,供大家实际体验 Chinese-CLIP 各规模模型的效果:
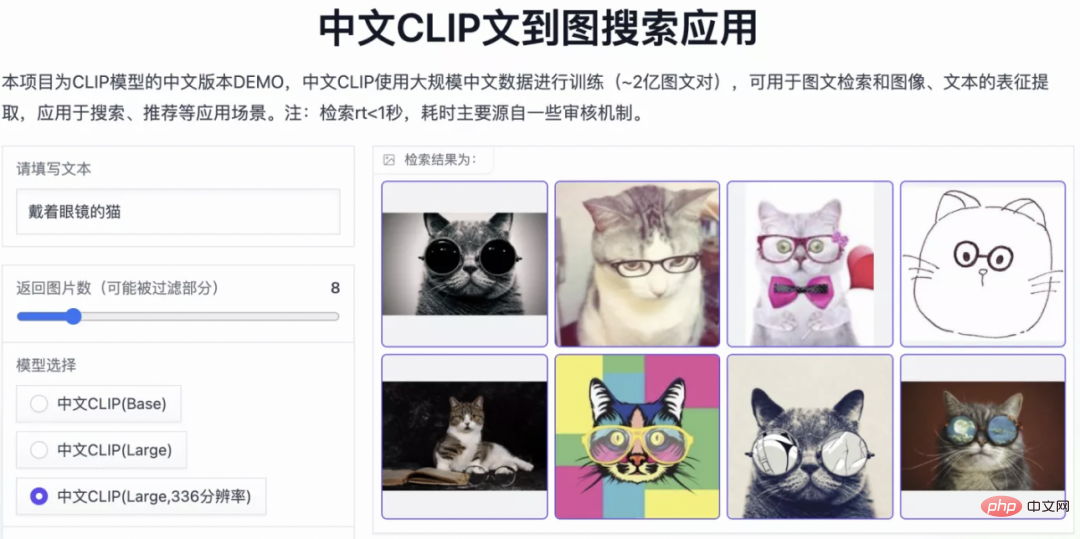
此次达魔搭社区推出 Chinese-CLIP 项目,为广大中文多模态研究和产业界用户,提供了一个优秀的预训练图文理解模型,帮助大家无门槛快速上手图文特征 & 相似度计算、图文检索以及零样本分类,并可尝试用于搭建像是图像生成这样更复杂的多模态应用。想要在中文多模态领域一展拳脚的朋友们,请一定不要错过!而这也仅仅是魔搭社区的一项应用之一,ModelScope 让众多 AI 领域的基础模型扮演应用基座的角色,支持更多创新模型、应用甚至产品的诞生。
以上是CLIP不接地气?你需要一个更懂中文的模型的详细内容。更多信息请关注PHP中文网其他相关文章!






















