

分割后门训练的后门防御方法:DBD

香港中文大学(深圳)吴保元教授课题组和浙江大学秦湛教授课题组联合发表了一篇后门防御领域的文章,已顺利被ICLR2022接收。
近年来,后门问题受到人们的广泛关注。随着后门攻击的不断提出,提出针对一般化后门攻击的防御方法变得愈加困难。该论文提出了一个基于分割后门训练过程的后门防御方法。
本文揭示了后门攻击就是一个将后门投影到特征空间的端到端监督训练方法。在此基础上,本文分割训练过程来避免后门攻击。该方法与其他后门防御方法进行了对比实验,证明了该方法的有效性。
收录会议:ICLR2022
文章链接:https://arxiv.org/pdf/2202.03423.pdf
代码链接:https://github.com/SCLBD/DBD
1 背景介绍
后门攻击的目标是通过修改训练数据或者控制训练过程等方法使得模型预测正确干净样本,但是对于带有后门的样本判断为目标标签。例如,后门攻击者给图片增加固定位置的白块(即中毒图片)并且修改图片的标签为目标标签。用这些中毒数据训练模型过后,模型就会判断带有特定白块的图片为目标标签(如下图所示)。
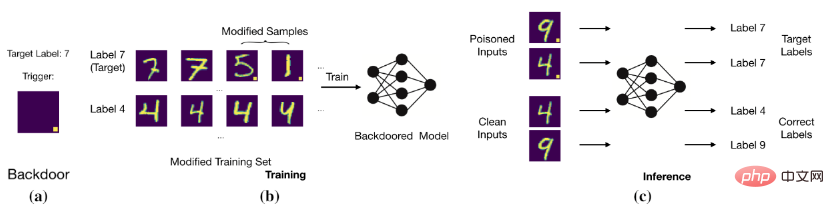 基本的后门攻击
基本的后门攻击
模型建立了触发器(trigger)和目标标签(target label)之间的关系。
2 相关工作
2.1 后门攻击
现有的后门攻击方法按照中毒图片的标签修改情况分为以下两类,修改中毒图片标签的投毒标签攻击(Poison-Label Backdoor Attack),维持中毒图片原本标签的干净标签攻击(Clean-Label Backdoor Attack)。
1.投毒标签攻击: BadNets (Gu et al., 2019)是第一个也是最具代表性的投毒标签攻击。之后(Chen et al., 2017)提出中毒图片的隐身性应与其良性版本相似,并在此基础上提出了混合攻击(blended attack)。最近,(Xue et al., 2020; Li et al., 2020; 2021)进一步探索了如何更隐蔽地进行中毒标签后门攻击。最近,一种更隐形和有效的攻击,WaNet (Nguyen & Tran, 2021年)被提出。WaNet采用图像扭曲作为后门触发器,在变形的同时保留了图像内容。
2.干净标签攻击: 为了解决用户可以通过检查图像-标签关系来注意到后门攻击的问题,Turner等人(2019)提出了干净标签攻击范式,其中目标标签与中毒样本的原始标签一致。在(Zhao et al,2020b)中将这一思想推广到攻击视频分类中,他们采用了目标通用对抗扰动(Moosavi-Dezfooli et al., 2017)作为触发。尽管干净标签后门攻击比投毒标签后门攻击更隐蔽,但它们的性能通常相对较差,甚至可能无法创建后门(Li et al., 2020c)。
2.2 后门防御
现有的后门防御大多是经验性的,可分为五大类,包括
1.基于探测的防御(Xu et al,2021;Zeng et al,2011;Xiang et al,2022)检查可疑的模型或样本是否受到攻击,它将拒绝使用恶意对象。
2.基于预处理的防御(Doan et al,2020;Li et al,2021;Zeng et al,2021)旨在破坏攻击样本中包含的触发模式,通过在将图像输入模型之前引入预处理模块来防止后门激活。
3.基于模型重构的防御(Zhao et al,2020a;Li et al,2021;)是通过直接修改模型来消除模型中隐藏的后门。
4.触发综合防御(Guo et al,2020;Dong et al,2021;Shen et al,2021)是首先学习后门,其次通过抑制其影响来消除隐藏的后门。
5.基于中毒抑制的防御(Du et al,2020;Borgnia et al,2021)在训练过程中降低中毒样本的有效性,以防止隐藏后门的产生
2.3 半监督学习和自监督学习
1.半监督学习:在许多现实世界的应用程序中,标记数据的获取通常依赖于手动标记,这是非常昂贵的。相比之下,获得未标记的样本要容易得多。为了同时利用未标记样本和标记样本的力量,提出了大量的半监督学习方法(Gao et al.,2017;Berthelot et al,2019;Van Engelen & Hoos,2020)。最近,半监督学习也被用于提高模型的安全性(Stanforth et al,2019;Carmon et al,2019),他们在对抗训练中使用了未标记的样本。最近,(Yan et al,2021)讨论了如何后门半监督学习。然而,该方法除了修改训练样本外,还需要控制其他训练成分(如训练损失)。
2.自监督学习:自监督学习范式是无监督学习的一个子集,模型使用数据本身产生的信号进行训练(Chen et al,2020a;Grill et al,2020;Liu et al,2021)。它被用于增加对抗鲁棒性(Hendrycks et al,2019;Wu et al,2021;Shi et al,2021)。最近,一些文章(Saha et al,2021;Carlini & Terzis, 2021;Jia et al,2021)探索如何向自监督学习投入后门。然而,这些攻击除了修改训练样本外,它们还需要控制其他训练成分(例如,训练损失)。
3 后门特征
我们对CIFAR-10数据集(Krizhevsky, 2009)进行了BadNets和干净标签攻击。对有毒数据集进行监督学习以及对未标记数据集进行自监督学习SimCLR(Chen et al., 2020a)。
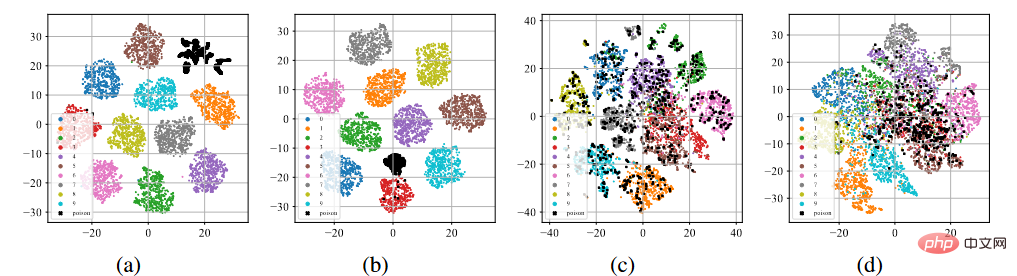
后门特征的t-sne展示
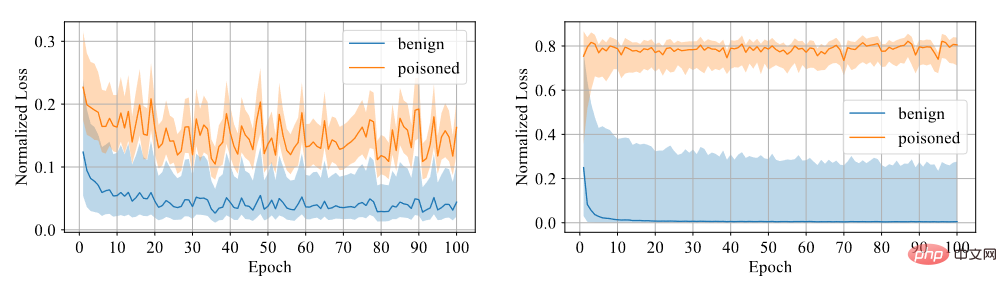
如上图(a)-(b)所示,在经过标准监督训练过程后,无论在投毒标签攻击还是干净标签攻击下,中毒样本(用黑点表示)都倾向于聚在一起形成单独的聚类。这种现象暗示了现有的基于投毒的后门攻击成功原因。过度的学习能力允许模型学习后门触发器的特征。与端到端监督训练范式相结合,模型可以缩小特征空间中中毒样本之间的距离,并将学习到的触发器相关特征与目标标签连接起来。相反,如上图(c)-(d)所示,在未标记的中毒数据集上,经过自监督训练过程后,中毒样本与带有原有标签的样本非常接近。这表明我们可以通过自监督学习来防止后门的产生。
4 基于分割的后门防御
基于后门特征的分析,我们提出分割训练阶段的后门防御。如下图所示,它包括三个主要阶段,(1)通过自监督学习学习一个纯化的特征提取器,(2)通过标签噪声学习过滤高可信样本,(3)半监督微调。
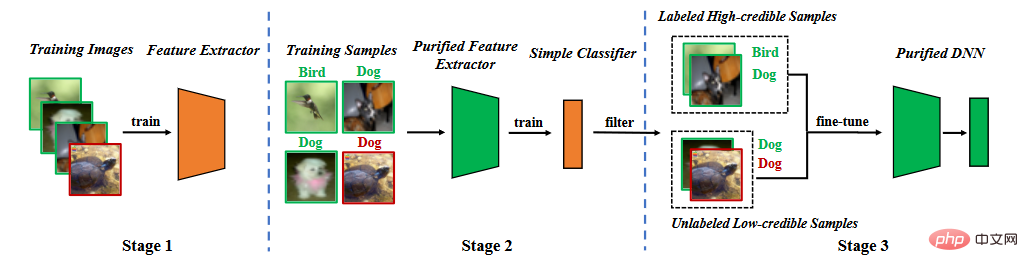 方法流程图
方法流程图
4.1 学习特征提取器
我们用训练数据集去学习模型。模型的参数包含两部分,一部分是骨干模型(backbone model)的参数另一部分是全连接层(fully connected layer)的参数。我们利用自监督学习优化骨干模型的参数。
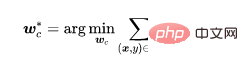
其中是自监督损失(例如,NT-Xent在SimCLR (Chen et al,2020)). 通过前面的分析,我们可以知道特征提取器很难学习到后门特征。
4.2 标签噪声学习过滤样本
一旦特征提取器被训练好后,我们固定特征提取器的参数并用训练数据集进一步学习全连接层参数,
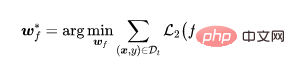
其中是监督学习损失(例如,交叉熵损失(cross entropy))。
虽然这样的分割流程会使得模型很难学到后门,但是它存在两个问题。首先,与通过监督学习训练的方法相比,由于学习到的特征提取器在第二阶段被冻结,预测干净样本的准确率会有一定的下降。其次,当中毒标签攻击出现时,中毒样本将作为“离群值”,进一步阻碍第二阶段的学习。这两个问题表明我们需要去除中毒样本,并对整个模型进行再训练或微调。
我们需要判断样本是否带有后门。我们认为模型对于后门样本难以学习,因此采用置信度作为区分指标,高置信度的样本为干净样本,而低置信度的样本为中毒样本。通过实验发现,利用对称交叉熵损失训练的模型对于两种样本的损失差距较大,从而区分度较高,如下图所示。
对称交叉熵损失和交叉熵损失对比
因此,我们固定特征提取器利用对称交叉熵损失训练全连接层,并且通过置信度的大小筛选数据集为高置信度数据和低置信度数据。
4.3 半监督微调
首先,我们删除低置信度数据的标签。我们利用半监督学习微调整个模型 。

其中是半监督损失(例如,在MixMatch(Berthelot et al,2019)中的损失函数)。
半监督微调既可以避免模型学习到后门触发器,又可以使得模型在干净数据集上表现良好。
5 实验
5.1 数据集和基准
文章在两个经典基准数据集上评估所有防御,包括CIFAR-10 (Krizhevsky, 2009)和ImageNet (Deng等人,2009)(一个子集)。文章采用ResNet18模型 (He et al., 2016)
文章研究了防御四种典型攻击的所有防御方法,即badnets(Gu et al,2019)、混合策略的后门攻击(blended)(Chen et al,2017)、WaNet (Nguyen & Tran, 2021)和带有对敌扰动的干净标签攻击(label-consistent)(Turner et al,2019)。

后门攻击示例图片
5.2 实验结果
实验的判断标准为BA是干净样本的判断准确率和ASR是中毒样本的判断准确率。
后门防御对比结果
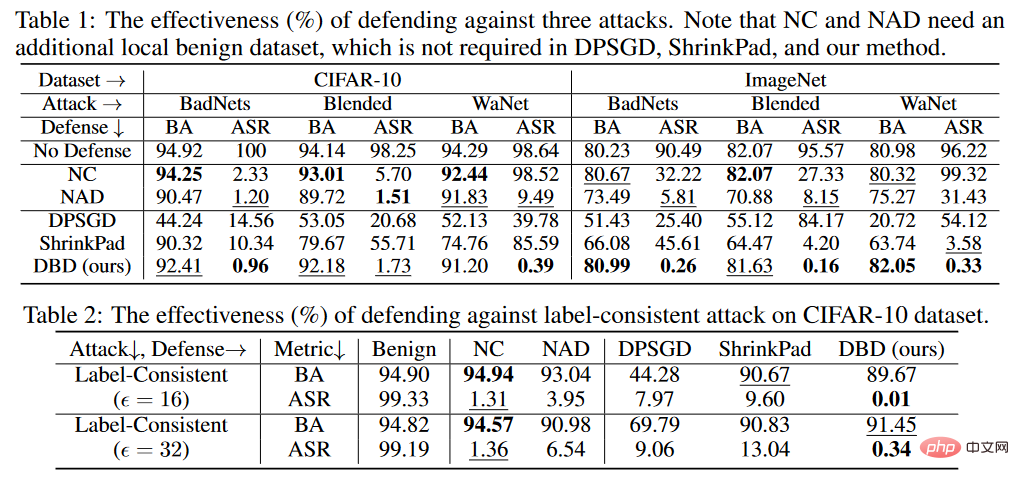
如上表所示,DBD在防御所有攻击方面明显优于具有相同要求的防御(即DPSGD和ShrinkPad)。在所有情况下,DBD比DPSGD的BA超过20%,而ASR低5%。DBD模型的ASR在所有情况下都小于2%(大多数情况下低于0.5%),验证了DBD可以成功地防止隐藏后门的创建。DBD与另外两种方法(即NC和NAD)进行比较,这两种方法都要求防御者拥有一个干净的本地数据集。
如上表所示,NC和NAD优于DPSGD和ShrinkPad,因为它们采用了来自本地的干净数据集的额外信息。特别是,尽管NAD和NC使用了额外的信息,但DBD比它们更好。特别是在ImageNet数据集上,NC对ASR的降低效果有限。相比之下,DBD达到最小的ASR,而DBD的BA在几乎所有情况下都是最高或第二高。此外,与未经任何防御训练的模型相比,防御中毒标签攻击时的BA下降不到2%。在相对较大的数据集上,DBD甚至更好,因为所有的基线方法都变得不那么有效。这些结果验证了DBD的有效性。
5.3 消融实验
各阶段消融实验
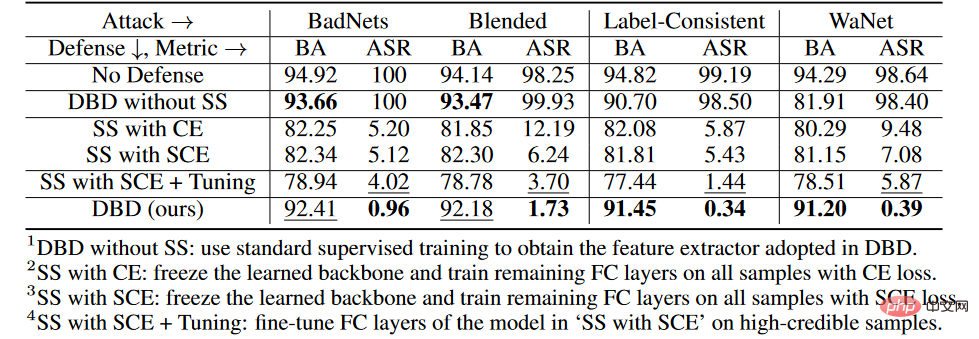
在CIFAR-10数据集上,我们比较了提出的DBD及其四个变体,包括
1.DBD不带SS,将由自监督学习生成的骨干替换为以监督方式训练的主干,并保持其他部分不变
2.SS带CE,冻结了通过自监督学习学习到的骨干,并在所有训练样本上训练剩下的全连接层的交叉熵损失
3.SS带SCE, 与第二种变体类似,但使用了对称交叉熵损失训练。
4.SS带SCE + Tuning,进一步微调由第三个变体过滤的高置信度样本上的全连接层。
如上表所示,解耦原始的端到端监督训练过程在防止隐藏后门的创建方面是有效的。此外,比较第二个和第三个DBD变体来验证SCE损失对防御毒药标签后门攻击的有效性。另外,第4个DBD变异的ASR和BA相对于第3个DBD变异要低一些。这一现象是由于低可信度样本的去除。这表明,在采用低可信度样本的有用信息的同时减少其副作用对防御很重要。
5.4 对于潜在的自适应性攻击的抵抗
如果攻击者知道DBD的存在,他们可能会设计自适应性攻击。如果攻击者能够知道防御者使用的模型结构,他们可以通过优化触发模式,在自监督学习后,使中毒样本仍然在一个新的集群中,从而设计自适应性攻击,如下所示:
攻击设定
对于一个-分类问题,让代表那些需要被投毒的干净样本,代表原标签为的样本,以及是一个被训练的骨干。给定攻击者预定的中毒图像生成器,自适应性攻击旨在优化触发模式,通过最小化有毒图像之间的距离,同时最大化有毒图像的中心与具有不同标签的良性图像集群的中心之间的距离,即。
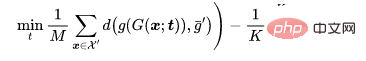
其中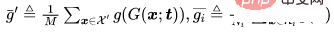 ,是一个距离判定。
,是一个距离判定。
实验结果
自适应性攻击在没有防御的情况下的BA为94.96%,和ASR为99.70%。然而,DBD的防御结果为BA93.21%以及ASR1.02%。换句话说,DBD是抵抗这种自适应性攻击的。
6 总结
基于投毒的后门攻击的机制是在训练过程中在触发模式和目标标签之间建立一种潜在的连接。本文揭示了这种连接主要是由于端到端监督训练范式学习。基于这种认识,本文提出了一种基于解耦的后门防御方法。大量的实验验证了DBD防御在减少后门威胁的同时保持了预测良性样本的高精度。
以上是分割后门训练的后门防御方法:DBD的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
0.这篇文章干了啥?提出了DepthFM:一个多功能且快速的最先进的生成式单目深度估计模型。除了传统的深度估计任务外,DepthFM还展示了在深度修复等下游任务中的最先进能力。DepthFM效率高,可以在少数推理步骤内合成深度图。下面一起来阅读一下这项工作~1.论文信息标题:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
波士顿动力Atlas,正式进入电动机器人时代!昨天,液压Atlas刚刚「含泪」退出历史舞台,今天波士顿动力就宣布:电动Atlas上岗。看来,在商用人形机器人领域,波士顿动力是下定决心要和特斯拉硬刚一把了。新视频放出后,短短十几小时内,就已经有一百多万观看。旧人离去,新角色登场,这是历史的必然。毫无疑问,今年是人形机器人的爆发年。网友锐评:机器人的进步,让今年看起来像人类的开幕式动作、自由度远超人类,但这真不是恐怖片?视频一开始,Atlas平静地躺在地上,看起来应该是仰面朝天。接下来,让人惊掉下巴
 超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂炼大模型,一互联网的数据不够用,根本不够用。训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。尤其在多模态任务中,这一问题尤为突出。一筹莫展之际,来自人大系的初创团队,用自家的新模型,率先在国内把“模型生成数据自己喂自己”变成了现实。而且还是理解侧和生成侧双管齐下,两侧都能生成高质量、多模态的新数据,对模型本身进行数据反哺。模型是啥?中关村论坛上刚刚露面的多模态大模型Awaker1.0。团队是谁?智子引擎。由人大高瓴人工智能学院博士生高一钊创立,高
 快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
什么?疯狂动物城被国产AI搬进现实了?与视频一同曝光的,是一款名为「可灵」全新国产视频生成大模型。Sora利用了相似的技术路线,结合多项自研技术创新,生产的视频不仅运动幅度大且合理,还能模拟物理世界特性,具备强大的概念组合能力和想象力。数据上看,可灵支持生成长达2分钟的30fps的超长视频,分辨率高达1080p,且支持多种宽高比。另外再划个重点,可灵不是实验室放出的Demo或者视频结果演示,而是短视频领域头部玩家快手推出的产品级应用。而且主打一个务实,不开空头支票、发布即上线,可灵大模型已在快影
 美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
最近,军事圈被这个消息刷屏了:美军的战斗机,已经能由AI完成全自动空战了。是的,就在最近,美军的AI战斗机首次公开,揭开了神秘面纱。这架战斗机的全名是可变稳定性飞行模拟器测试飞机(VISTA),由美空军部长亲自搭乘,模拟了一对一的空战。5月2日,美国空军部长FrankKendall在Edwards空军基地驾驶X-62AVISTA升空注意,在一小时的飞行中,所有飞行动作都由AI自主完成!Kendall表示——在过去的几十年中,我们一直在思考自主空对空作战的无限潜力,但它始终显得遥不可及。然而如今,
 仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
我们熟悉的Meta推出的Llama3、MistralAI推出的Mistral和Mixtral模型以及AI21实验室推出的Jamba等开源大语言模型已经成为OpenAI的竞争对手。在大多数情况下,用户需要根据自己的数据对这些开源模型进行微调,才能充分释放模型的潜力。在单个GPU上使用Q-Learning对比小的大语言模型(如Mistral)进行微调不是难事,但对像Llama370b或Mixtral这样的大模型的高效微调直到现在仍然是一个挑战。因此,HuggingFace技术主管PhilippSch
 全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐LLM方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管RLHF方法的结果很出色,但其中涉及到了一些优化难题。其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。近段时间已有一些研究者探索了更简单的离线算法,其中之一便是直接偏好优化(DPO)。DPO是通过参数化RLHF中的奖励函数来直接根据偏好数据学习策略模型,这样就无需显示式的奖励模型了。该方法简单稳定
 模型合并就进化,直接拿下SOTA!Transformer作者创业新成果火了
Mar 26, 2024 am 11:30 AM
模型合并就进化,直接拿下SOTA!Transformer作者创业新成果火了
Mar 26, 2024 am 11:30 AM
把Huggingface上的现成模型拿来“攒一攒”——直接就能组合出新的强大模型?!日本大模型公司sakana.ai脑洞大开(正是“Transformer八子”之一所创办的公司),想出了这么一个进化合并模型的妙招。该方法不仅能自动生成新的基础模型,而且性能绝不赖:他们利用一个包含70亿个参数的日语数学大型模型,在相关基准测试中取得了最先进的结果,超越了700亿参数的Llama-2等先前模型。最重要的是,得出这样的模型不需要任何梯度训练,因此需要的计算资源大大减少。英伟达科学家JimFan看完大赞
