

NUS华人团队发布最新模型:单视图重建3D,快速准确!

2D图像的3D重建一直是CV领域的重头戏。
层出不同的模型被开发出来试图攻克这个难题。
今天,新加坡国立大学的学者共同发表了一篇论文,开发了一个全新的框架Anything-3D来解决这个老大难问题。

论文地址:https://arxiv.org/pdf/2304.10261.pdf
借助Meta「分割一切」模型,Anything-3D直接让分割后的任意物体活起来了。

另外,再用上Zero-1-to-3模型,你就可以得到不同角度的柯基。
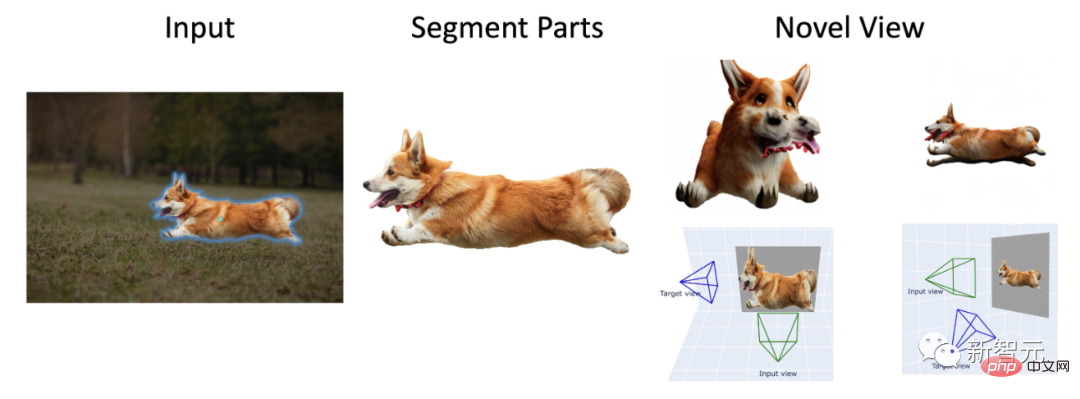
甚至,还可以进行人物3D重建。

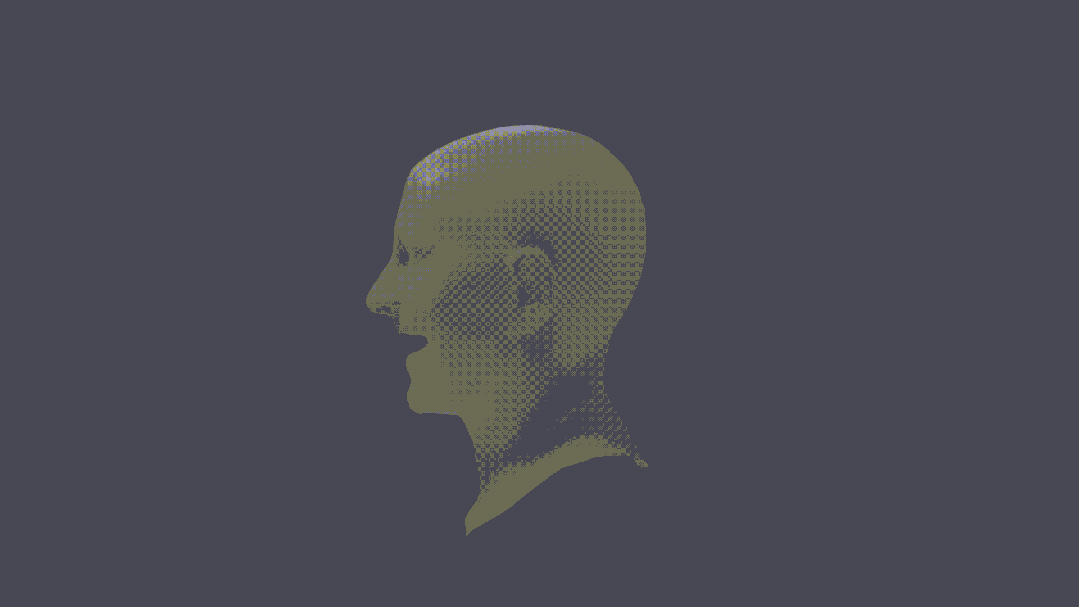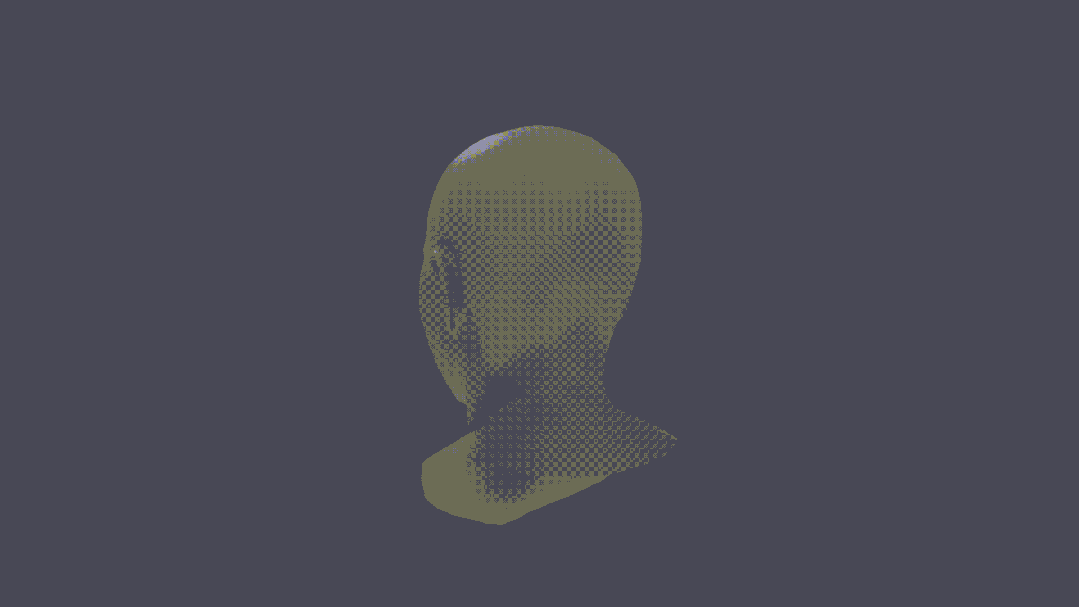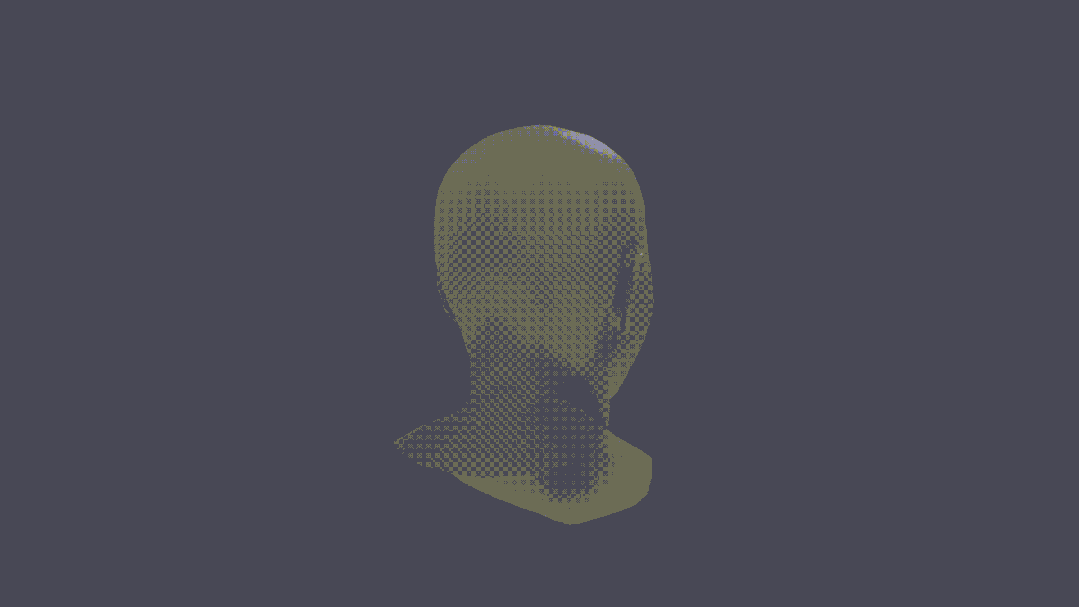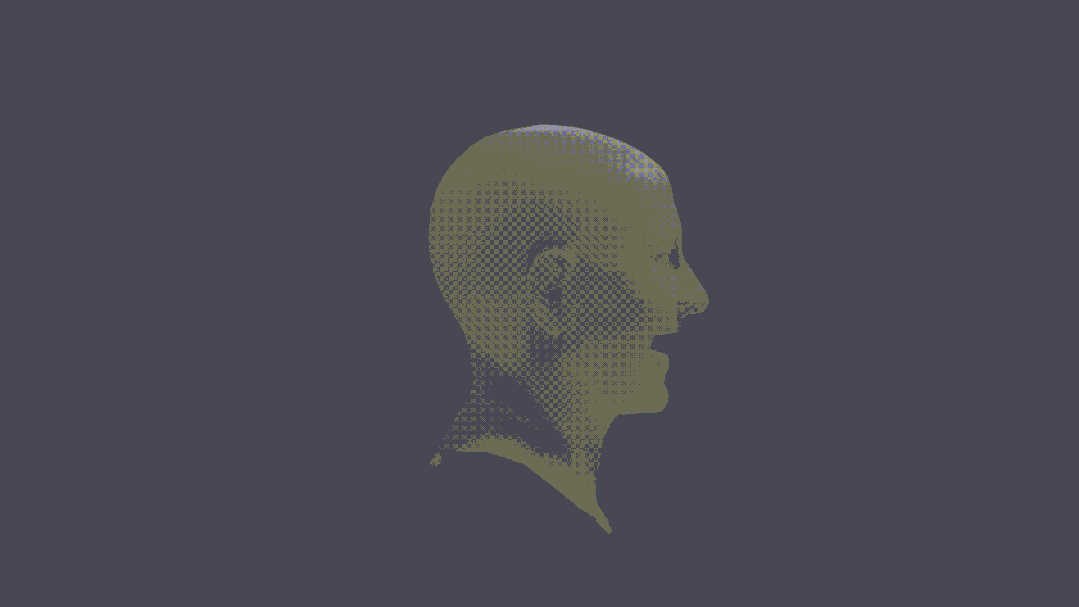
可以说,这把真突破了。
Anything-3D!
在现实世界中,各种物体和各类环境既多样又复杂。所以,在不受限制的情况下,从单一RGB图像中进行三维重建面临诸多困难。
在此,新加坡国立大学研究人员结合了一系列视觉语言模型和SAM(Segment-Anything)物体分割模型,生成了一个功能多、可靠性强的系统——Anything-3D。
目的就是在单视角的条件下,完成3D重建的任务。
他们采用BLIP模型生成纹理描述,用SAM模型提取图像中的物体,然后利用文本→图像的扩散模型Stable Diffusion将物体放置到Nerf(神经辐射场)中。
在后续的实验中,Anything-3D展示出了其强大的三维重建的能力。不仅准确,适用面也非常广泛。
Anything-3D在解决现有方法的局限这方面,效果明显。研究人员通过对各类数据集的测验和评估,展示了这种新框架的优点。

上图中,我们可以看到,「柯基吐舌头千里奔袭图」、「银翅女神像委身豪车图」,以及「田野棕牛头戴蓝绳图」。
这是一个初步展示,Anything-3D框架能够熟练地把在任意的环境中拍摄的单视角图像中恢复成的3D的形态,并生成纹理。
尽管相机视角和物体属性有很大的变化,但这种新框架始终能提供准确性较高的结果。
要知道,从2D图像中重建3D物体是计算机视觉领域课题的核心,对机器人、自动驾驶、增强现实、虚拟现实,以及三维打印等领域都有巨大影响。
虽说这几年来取得了一些不错的进展,但在非结构化环境中进行单图像物体重建的任务仍然是一个具有很大吸引力且亟待解决的问题。
目前,研究人员的任务就是从一张单一的二维图像中生成一个或多个物体的三维表示,表示方法包括点云、网格或体积表示。
然而,这个问题从根本上来说并不成立。
由于二维投影所产生的内在模糊性,不可能明确地确定一个物体的三维结构。
再加上形状、大小、纹理和外观的巨大差异,重建自然环境下的物体非常复杂。此外,现实世界图像中的物体经常会被遮挡,这就会阻碍被遮挡部分的精准重建。
同时,光照和阴影等变量也会极大地影响物体的外观,而角度和距离的不同也会导致二维投影的明显变化。
困难说够了,Anything-3D可以出场了。
论文中,研究人员详细介绍了这个开创性的系统框架,将视觉语言模型和物体分割模型融合在一起,轻轻松松就能把2D物体搞成3D的。
这样,一个功能强大、自适应能力强的系统就成了。单视图重建?Easy.
研究人员表示,将这两种模型结合,就可以检索并确定出给定图像的三维纹理和几何形状。
Anything-3D利用BLIP模型(Bootstrapping语言-图像模型)预训练对图像的文本描述,然后再用SAM模型识别物体的分布区域。
接下来,利用分割出来的物体和文本描述来执行3D重建任务。
换句话说,该论文利用预先训练好的2D文本→图像扩散模型来进行图像的3D合成。此外,研究人员用分数蒸馏来训练一个专门用于图像的Nerf.
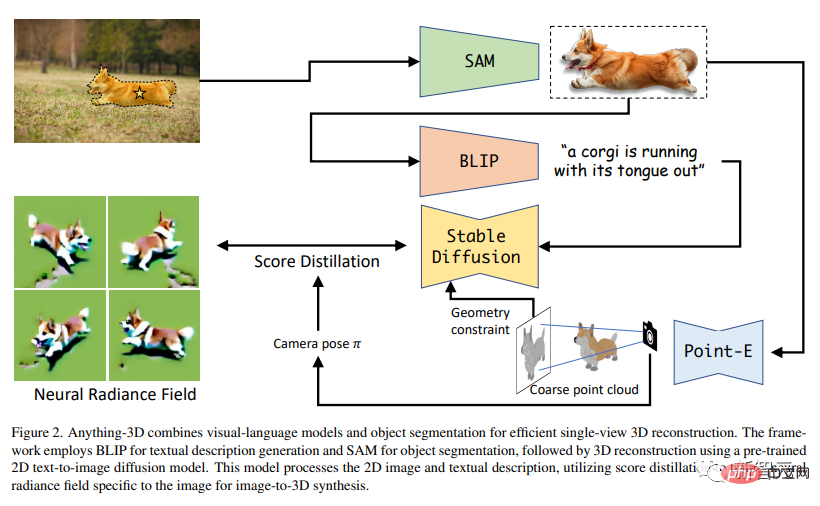
上图就是生成3D图像的全过程。左上角是2D原图,先经过SAM,分割出柯基,再经过BLIP,生成文本描述,然后再用分数蒸馏搞个Nerf出来。
通过对不同数据集的严格实验,研究人员展示了这种方法的有效性和自适应性,同时,在准确性、稳健性和概括能力方面都超过了现有的方法。
研究人员还对自然环境中3D物体重建中已有的挑战进行了全面深入地分析,探讨了新框架如何解决此类问题。
最终,通过将基础模型中的零距离视觉和语言理解能力相融合,新框架更能从真实世界的各类图像中重建物体,生成精确、复杂、适用面广的3D表示。
可以说,Anything-3D是3D物体重建领域的一个重大突破。
下面是更多的实例:

炫酷黑内饰小白保时捷,亮丽橙色挖机吊车,绿帽小黄橡皮鸭
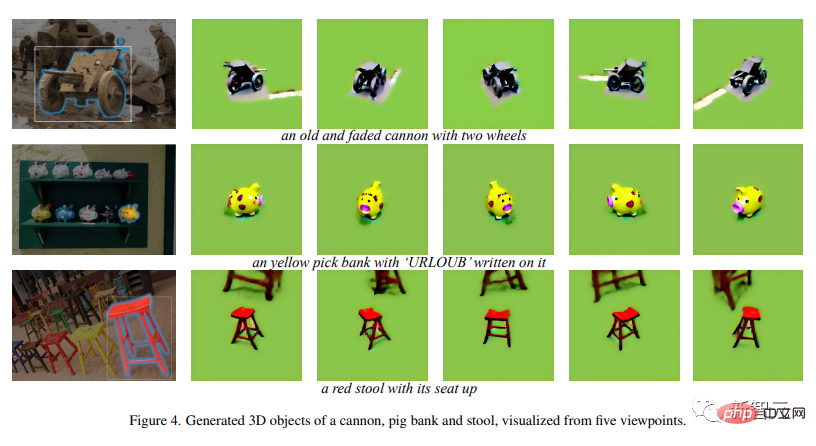
时代眼泪褪色大炮、小猪猪可爱迷你存钱罐、朱砂红四腿高脚凳
这个新框架可以交互式地识别单视角图像中的区域,并用优化的文本嵌入来表示2D物体。最终,使用一个3D感知的分数蒸馏模型有效地生成高质量的3D物体。
总之,Anything-3D展示了从单视角图像中重建自然3D物体的潜力。
研究者称,新框架3D重建的质量还可以更完美,研究人员正在不断努力提高生成的质量。
此外,研究人员表示,目前没有提供3D数据集的定量评估,如新的视图合成和误差重建,但在未来的工作迭代中会纳入这些内容。
同时,研究人员的最终目标是扩大这个框架,以适应更多的实际情况,包括稀疏视图下的对象恢复。
作者介绍
Wang目前是新加坡国立大学(NUS)ECE系的终身制助理教授。
在加入新加坡国立大学之前,他曾是Stevens理工学院CS系的一名助理教授。在加入Stevens之前,我曾在伊利诺伊大学厄巴纳-香槟分校Beckman研究所的Thomas Huang教授的图像形成小组担任博士后。
Wang在洛桑联邦理工学院(EPFL)计算机视觉实验室获得博士学位,由Pascal Fua教授指导,并在2010年获得香港理工大学计算机系的一等荣誉学士学位。

以上是NUS华人团队发布最新模型:单视图重建3D,快速准确!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 四款值得推荐的AI辅助编程工具
Apr 22, 2024 pm 05:34 PM
四款值得推荐的AI辅助编程工具
Apr 22, 2024 pm 05:34 PM
这个AI辅助编程工具在这个AI迅速发展的阶段,挖掘出了一大批好用的AI辅助编程工具。AI辅助编程工具能够提高开发效率、改善代码质量、降低bug率,是现代软件开发过程中的重要助手。今天大姚给大家分享4款AI辅助编程工具(并且都支持C#语言),希望对大家有所帮助。https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot是一款AI编码助手,可帮助你更快、更省力地编写代码,从而将更多精力集中在问题解决和协作上。Git
 CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
写在前面&笔者的个人理解目前,在整个自动驾驶系统当中,感知模块扮演了其中至关重要的角色,行驶在道路上的自动驾驶车辆只有通过感知模块获得到准确的感知结果后,才能让自动驾驶系统中的下游规控模块做出及时、正确的判断和行为决策。目前,具备自动驾驶功能的汽车中通常会配备包括环视相机传感器、激光雷达传感器以及毫米波雷达传感器在内的多种数据信息传感器来收集不同模态的信息,用于实现准确的感知任务。基于纯视觉的BEV感知算法因其较低的硬件成本和易于部署的特点,以及其输出结果能便捷地应用于各种下游任务,因此受到工业
 牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
写在前面项目链接:https://nianticlabs.github.io/mickey/给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对
 AI程序员哪家强?探索Devin、通义灵码和SWE-agent的潜力
Apr 07, 2024 am 09:10 AM
AI程序员哪家强?探索Devin、通义灵码和SWE-agent的潜力
Apr 07, 2024 am 09:10 AM
2022年3月3日,距世界首个AI程序员Devin诞生不足一个月,普林斯顿大学的NLP团队开发了一个开源AI程序员SWE-agent。它利用GPT-4模型在GitHub存储库中自动解决问题。SWE-agent在SWE-bench测试集上的表现与Devin相似,平均耗时93秒,解决了12.29%的问题。SWE-agent通过与专用终端交互,可以打开、搜索文件内容,使用自动语法检查、编辑特定行,以及编写和执行测试。(注:以上内容为原内容微调,但保留了原文中的关键信息,未超过指定字数限制。)SWE-A
 学习如何利用Go语言开发移动应用程序
Mar 28, 2024 pm 10:00 PM
学习如何利用Go语言开发移动应用程序
Mar 28, 2024 pm 10:00 PM
Go语言开发移动应用程序教程随着移动应用市场的不断蓬勃发展,越来越多的开发者开始探索如何利用Go语言开发移动应用程序。作为一种简洁高效的编程语言,Go语言在移动应用开发中也展现出了强大的潜力。本文将详细介绍如何利用Go语言开发移动应用程序,并附上具体的代码示例,帮助读者快速入门并开始开发自己的移动应用。一、准备工作在开始之前,我们需要准备好开发环境和工具。首
 五大热门Go语言库汇总:开发必备利器
Feb 22, 2024 pm 02:33 PM
五大热门Go语言库汇总:开发必备利器
Feb 22, 2024 pm 02:33 PM
五大热门Go语言库汇总:开发必备利器,需要具体代码示例Go语言自从诞生以来,受到了广泛的关注和应用。作为一门新兴的高效、简洁的编程语言,Go的快速发展离不开丰富的开源库的支持。本文将介绍五大热门的Go语言库,这些库在Go开发中扮演了至关重要的角色,为开发者提供了强大的功能和便捷的开发体验。同时,为了更好地理解这些库的用途和功能,我们会结合具体的代码示例进行讲
 LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
写在前面&笔者的个人理解这篇论文致力于解决当前多模态大语言模型(MLLMs)在自动驾驶应用中存在的关键挑战,即将MLLMs从2D理解扩展到3D空间的问题。由于自动驾驶车辆(AVs)需要针对3D环境做出准确的决策,这一扩展显得尤为重要。3D空间理解对于AV来说至关重要,因为它直接影响车辆做出明智决策、预测未来状态以及与环境安全互动的能力。当前的多模态大语言模型(如LLaVA-1.5)通常仅能处理较低分辨率的图像输入(例如),这是由于视觉编码器的分辨率限制,LLM序列长度的限制。然而,自动驾驶应用需
 3D视觉绕不开的点云配准!一文搞懂所有主流方案与挑战
Apr 02, 2024 am 11:31 AM
3D视觉绕不开的点云配准!一文搞懂所有主流方案与挑战
Apr 02, 2024 am 11:31 AM
作为点集合的点云有望通过3D重建、工业检测和机器人操作中,在获取和生成物体的三维(3D)表面信息方面带来一场改变。最具挑战性但必不可少的过程是点云配准,即获得一个空间变换,该变换将在两个不同坐标中获得的两个点云对齐并匹配。这篇综述介绍了点云配准的概述和基本原理,对各种方法进行了系统的分类和比较,并解决了点云配准中存在的技术问题,试图为该领域以外的学术研究人员和工程师提供指导,并促进对点云配准统一愿景的讨论。点云获取的一般方式分为主动和被动方式,由传感器主动获取的点云为主动方式,后期通过重建的方式
