
Stable Diffusion 在图像生成领域的知名度不亚于对话大模型中的 ChatGPT。其能够在几十秒内为任何给定的输入文本创建逼真图像。由于 Stable Diffusion 的参数量超过 10 亿,并且由于设备上的计算和内存资源有限,因而这种模型主要运行在云端。
在没有精心设计和实施的情况下,在设备上运行这些模型可能会导致延迟增加,这是由于迭代降噪过程和内存消耗过多造成的。
如何在设备端运行 Stable Diffusion 引起了大家的研究兴趣,此前,有研究者开发了一个应用程序,该应用在 iPhone 14 Pro 上使用 Stable Diffusion 生成图片仅需一分钟,使用大约 2GiB 的应用内存。
此前苹果也对此做了一些优化,他们在 iPhone、iPad、Mac 等设备上,半分钟就能生成一张分辨率 512x512 的图像。高通紧随其后,在安卓手机端运行 Stable Diffusion v1.5 ,不到 15 秒生成分辨率 512x512 的图像。
近日,谷歌发表的一篇论文中《 Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations 》,他们实现了在 GPU 驱动的设备上运行 Stable Diffusion 1.4 ,达到 SOTA 推理延迟性能(在三星 S23 Ultra 上,通过 20 次迭代生成 512 × 512 的图像仅需 11.5 秒)。此外,该研究不是只针对一种设备;相反,它是一种通用方法,适用于改进所有潜在扩散模型。
在没有数据连接或云服务器的情况下,这项研究为在手机上本地运行生成 AI 开辟了许多可能性。Stable Diffusion 去年秋天才发布,今天已经可以塞进设备运行,可见这个领域发展速度有多快。

论文地址:https://arxiv.org/pdf/2304.11267.pdf
为了达到这一生成速度,谷歌提出了一些优化建议,下面我们看看谷歌是如何优化的。
该研究旨在提出优化方法来提高大型扩散模型文生图的速度,其中针对 Stable Diffusion 提出一些优化建议,这些优化建议也适用于其他大型扩散模型。
首先来看一下 Stable Diffusion 的主要组成部分,包括:文本嵌入器(text embedder)、噪声生成(noise generation)、去噪神经网络(denoising neural network)和图像解码器(image decoder,如下图 1 所示。
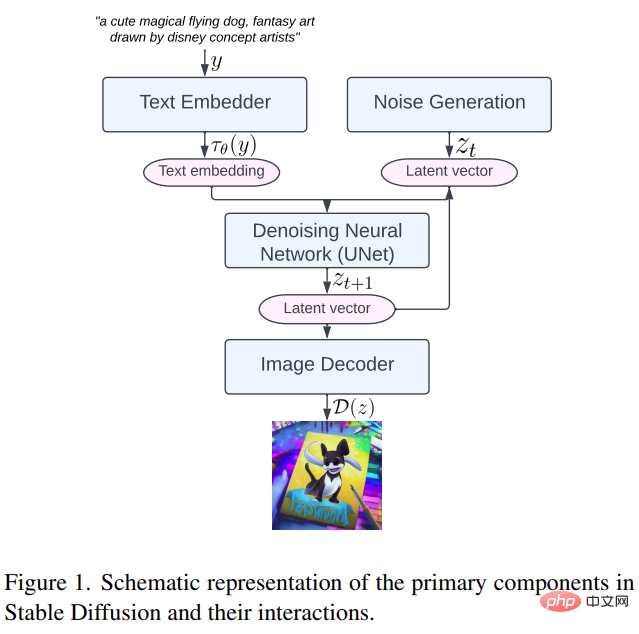
然后我们具体看一下该研究提出的三种优化方法。
专用内核:Group Norm 和 GELU
组归一化(GN)方法的工作原理是将特征图的通道(channel)划分为更小的组,并独立地对每个组进行归一化,从而使 GN 对批大小的依赖性降低,更适合各种批大小和网络架构。该研究没有按顺序执行 reshape、取均值、求方差、归一化这些操作,而是设计了一个独特的 GPU shader 形式的内核,它可以在一个 GPU 命令中执行所有这些操作,而无需任何中间张量(tensor)。
高斯误差线性单元(GELU)作为常用的模型激活函数,包含大量数值计算,例如乘法、加法和高斯误差函数。该研究用一个专用的 shader 来整合这些数值计算及其伴随的 split 和乘法操作,使它们能够在单个 AI 作画调用中执行。
提高注意力模块的效率
Stable Diffusion 中的文本到图像 transformer 有助于对条件分布进行建模,这对于文本到图像生成任务至关重要。然而,由于内存复杂性和时间复杂度,自 / 交叉注意力机制在处理长序列时遇到了困难。基于此,该研究提出两种优化方法,以缓解计算瓶颈。
一方面,为了避免在大矩阵上执行整个 softmax 计算,该研究使用一个 GPU shader 来减少运算操作,大大减少了中间张量的内存占用和整体延迟,具体方法如下图 2 所示。

另一方面,该研究采用 FlashAttention [7] 这种 IO 感知的精确注意力算法,使得高带宽内存(HBM)的访问次数少于标准注意力机制,提高了整体效率。
Winograd 卷积
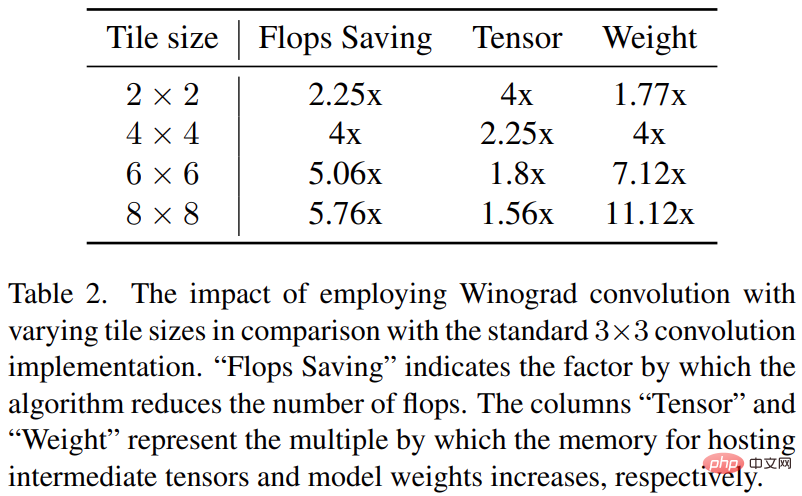
Winograd 卷积将卷积运算转换为一系列矩阵乘法。这种方法可以减少许多乘法运算,提高计算效率。但是,这样一来也会增加内存消耗和数字错误,特别是在使用较大的 tile 时。
Stable Diffusion 的主干在很大程度上依赖于 3×3 卷积层,尤其是在图像解码器中,它们占了 90% 。该研究对这一现象进行了深入分析,以探索在 3 × 3 内核卷积上使用不同 tile 大小的 Winograd 的潜在好处。研究发现 4 × 4 的 tile 大小最佳,因为它在计算效率和内存利用率之间提供了最佳平衡。
该研究在各种设备上进行了基准测试:三星 S23 Ultra(Adreno 740)和 iPhone 14 Pro Max(A16)。基准测试结果如下表 1 所示:
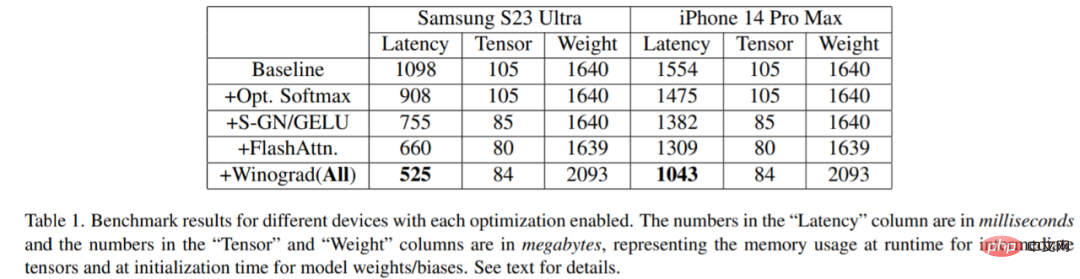
很明显,随着每个优化被激活,延迟逐渐减少(可理解为生成图像时间减少)。具体而言,与基线相比:在三星 S23 Ultra 延迟减少 52.2%;iPhone 14 Pro Max 延迟减少 32.9%。此外,该研究还对三星 S23 Ultra 端到端延迟进行评估,在 20 个去噪迭代 step 内,生成 512 × 512 像素图像,不到 12 秒就达到 SOTA 结果。
小型设备可以运行自己的生成式人工智能模型,这对未来意味着什么?我们可以期待一波。
以上是谷歌下场优化扩散模型,三星手机运行Stable Diffusion,12秒内出图的详细内容。更多信息请关注PHP中文网其他相关文章!





















