

只需3秒就能偷走你的声音!微软发布语音合成模型VALL-E:网友惊呼「电话诈骗」门槛又拉低了

让ChatGPT帮你写剧本,Stable Diffusion生成插图,做视频就差个配音演员了?它来了!
最近来自微软的研究人员发布了一个全新的文本到语音(text-to-speech, TTS)模型VALL-E,只需要提供三秒的音频样本即可模拟输入人声,并根据输入文本合成出对应的音频,而且还可以保持说话者的情感基调。

论文链接:https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
项目链接:https://valle-demo.github.io/
代码链接:https://github.com/microsoft/unilm
先看看效果:假设你有了一段3秒钟的录音。
diversity_speaker音频:00:0000:03
然后只需要输入文本「Because we do not need it.」,即可获得合成的语音。
diversity_s1音频:00:0000:01
甚至使用不同的随机种子,还能进行个性化的语音合成。
diversity_s2音频:00:0000:02
VALL-E还能保持说话人的环境声,比如输入这段语音。
env_speaker音频:00:0000:03
再根据文本「I think it's like you know um more convenient too.」,就能输出合成语音的同时保持环境声。
env_vall_e音频:00:0000:02
而且VALL-E也能保持说话人的情绪,比如输入一段愤怒的语音。
anger_pt音频:00:0000:03
再根据文本「We have to reduce the number of plastic bags.」,同样可以表达愤怒的情绪。
anger_ours音频:00:0000:02
在项目网站上还有更多的例子。
从方法上具体来说,研究人员从现成的神经音频编解码器模型中提取的离散编码来训练语言模型VALL-E,并将TTS视为一个条件语言建模任务而非连续信号回归。
在预训练阶段,VALL-E接受的TTS训练数据达到了6万小时的英语语音,比现有系统用到的数据大了几百倍。
并且VALL-E还展现出了语境学习(in-context learning)能力,只需将unseen speaker的3秒注册录音作为声音提示,即可合成高质量的个性化语音。
实验结果表明,VALL-E在语音自然度和说话人相似度方面明显优于最先进的zero-shot TTS系统,还可以在合成中保留说话人的情感和声音提示的声学环境。
Zero-shot语音合成
过去十年,通过神经网络和端到端建模的发展,语音合成取得了巨大突破。
但目前级联的文本到语音(TTS)系统通常利用具有声学模型的pipeline和使用mel谱图作为中间表示的声码器(vocoder)。
虽然一些高性能的TTS系统可以从单个或多个扬声器中合成高质量的语音,但它仍然需要来自录音室的高质量清洁数据,从互联网上抓取的大规模数据无法满足数据要求,而且会导致模型的性能下降。
由于训练数据相对较少,目前的TTS系统仍然存在泛化能力差的问题。
在zero-shot的任务设置下,对于训练数据中没有出现过的的说话人,相似度和语音自然度都会急剧下降。
为了解决zero-shot的TTS问题,现有的工作通常利用说话人适应(speaker adaption)和说话人编码(speaker encoding)等方法,需要额外的微调,复杂的预先设计的特征,或沉重的结构工程。
与其为这个问题设计一个复杂而特殊的网络,鉴于在文本合成领域的成功,研究人员认为最终的解决方案应当是尽可能地用大量不同的数据来训练模型。
VALL-E模型
在文本合成领域,来自互联网的大规模无标记数据直接喂入模型,随着训练数据量的增加,模型性能也在不断提高。
研究人员将这一思路迁移到语音合成领域,VALL-E模型是第一个基于语言模型的TTS框架,利用海量的、多样化的、多speaker的语音数据。
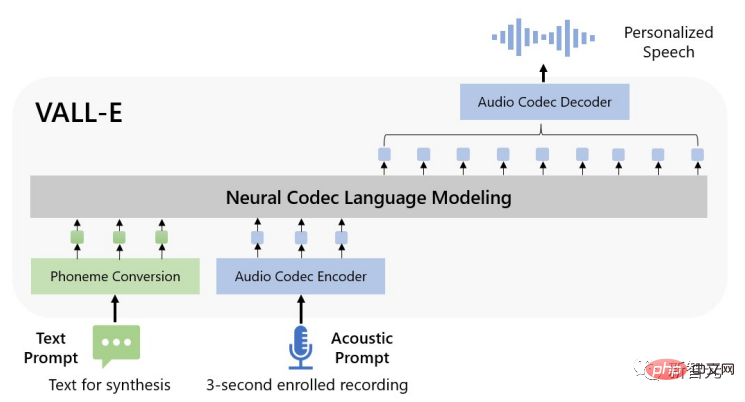
为了合成个性化的语音,VALL-E模型根据3秒enrolled录音的声学token和音素prompt来生成相应的声学token,这些信息可以限制说话人和内容信息。
最后,生成的声学token被用来与相应的神经编解码器合成最终波形。
来自音频编解码器模型的离散声学token使得TTS可以被视为有条件的编解码器语言建模,所以一些先进的基于提示的大模型技术(如GPTs)就可以被用在TTS任务上了。
声学token还可以在推理过程中使用不同的采样策略,在TTS中产生多样化的合成结果。
研究人员利用LibriLight数据集训练VALL-E,该语料库由6万小时的英语语音组成,有7000多个独特的说话人。原始数据是纯音频的,所以只需要使用一个语音识别模型来生成转录即可。
与以前的TTS训练数据集,如LibriTTS相比,论文中提供的新数据集包含更多的噪声语音和不准确的转录,但提供了不同的说话人和语体(prosodies)。
研究人员认为,文章中提出的方法对噪声具有鲁棒性,并可以利用大数据来实现良好的通用性。

值得注意的是,现有的TTS系统总是用几十个小时的单语者数据或几百个小时的多语者数据进行训练,比VALL-E小几百倍以上。
总之,VALL-E是一种全新的、用于TTS的语言模型方法,使用音频编解码代码作为中间表征,利用大量不同的数据,赋予模型强大的语境学习能力。
推理:In-Context Learning via Prompting
语境学习(in-context learning)是基于文本的语言模型的一个令人惊讶的能力,它能够预测未见过的输入的标签而不需要额外的参数更新。
对于TTS来说,如果模型能够在不进行微调的情况下为未见过的说话者合成高质量的语音,那么该模型就被认为具有语境中学习能力。
然而,现有的TTS系统的语境中学习能力并不强,因为它们要么需要额外的微调,要么对未见过的说话者来说会有很大的退化。
对于语言模型来说,prompting是必要的,以便在zero-shot的情况下实现语境学习。
研究人员设计的提示和推理如下:
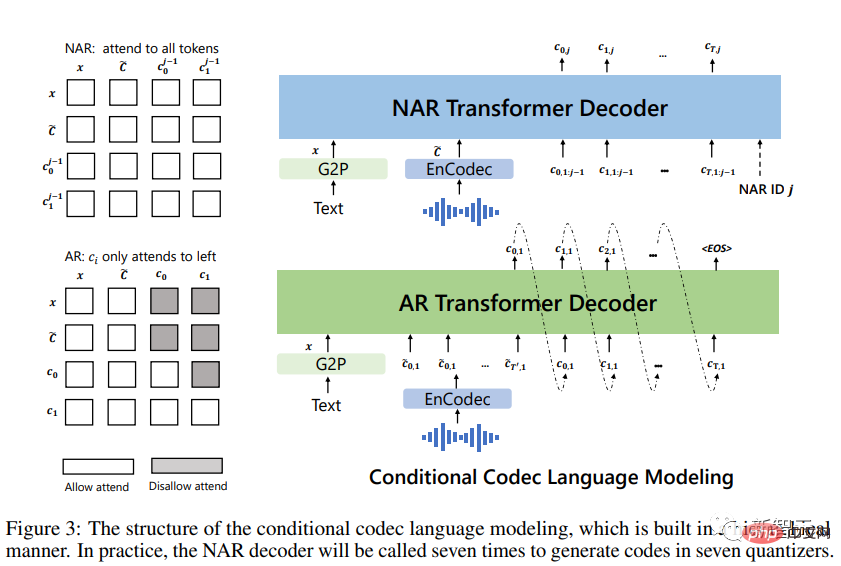
首先将文本转换为音素序列,并将enrolled录音编码为声学矩阵,形成音素提示和声学提示,这两种提示都用于AR和NAR模型中。
对于AR模型,使用以提示为条件的基于采样的解码,因为beam search可能导致LM进入无限循环;此外,基于抽样的方法可以大大增加输出的多样性。
对于NAR模型,使用贪婪解码来选择具有最高概率的token。
最后,使用神经编解码器来生成以八个编码序列为条件的波形。
声学提示可能与要合成的语音之间不一定存在语义关系,所以可以分为两种情况:
VALL-E:主要目标是为未见过的说话者生成给定的内容。
该模型的输入为一个文本句子、一段enrolled语音及其相应的转录。将enrolled语音的转录音素作为音素提示添加到给定句子的音素序列中,并使用注册语音的第一层声学token作为声学前缀。有了音素提示和声学前缀,VALL-E为给定的文本生成声学token,克隆这个说话人的声音。
VALL-E-continual:使用整个转录和话语的前3秒分别作为音素和声学提示,并要求模型生成连续的内容。
推理过程与设置VALL-E相同,只是enrolled语音和生成的语音在语义上是连续的。
实验部分
研究人员在LibriSpeech和VCTK数据集上评估了VALL-E,其中所有测试的说话人在训练语料库中都没有出现过。
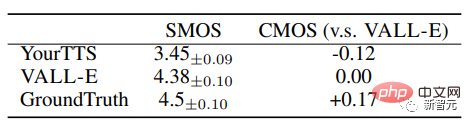
VALL-E在语音自然度和说话人相似度方面明显优于最先进的zero-shot TTS系统,在LibriSpeech上有+0.12的比较平均选项得分(CMOS)和+0.93的相似度平均选项得分(SMOS)。
VALL-E在VCTK上也以+0.11 SMOS和+0.23 CMOS的性能改进超越了基线系统,甚至达到了针对ground truth的+0.04CMOS得分,表明在VCTK上,未见过的说话者的合成语音与人类录音一样自然。
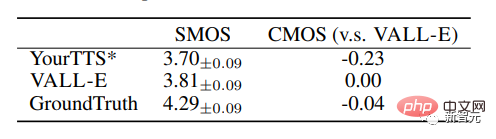
此外,定性分析表明,VALL-E能够用2个相同的文本和目标说话人合成不同的输出,这可能有利于语音识别任务的伪数据创建。
实验中还可以发现,VALL-E能够保持声音环境(如混响)和声音提示的情绪(如愤怒等)。
安全隐患
强大的技术如果被乱用,就可能对社会造成危害,比如电话诈骗的门槛又被拉低了!
由于VALL-E具有潜在的恶作剧和欺骗的能力,微软并没有开放VALL-E的代码或接口以供测试。
有网友分享道:如果你给系统管理员打电话,录下他们说「你好」的几句话,然后根据这几句话重新合成语音「 你好,我是系统管理员。我的声音是唯一标识,可以进行安全验证。」我之前一直认为这是不可能的,你不可能用那么少的数据来完成这个任务。现在看来,我可能错了......
在项目最后的道德声明(Ethics Statement)中,研究人员表示「本文的实验是在模型使用者为目标说话人并得到说话人认可的假设下进行的。然而,当该模型推广到看不见的说话人时,相关部分应该伴有语音编辑模型,包括保证说话人同意执行修改的协议和检测被编辑语音的系统。」

作者同时在论文中进行声明,由于 VALL-E 可以合成能够保持说话者身份的语音,它可能会带来误用该模型的潜在风险,例如欺骗声音识别或者模仿特定的说话者。
为了降低这种风险,可以建立一个检测模型来区分音频剪辑是否由 VALL-E 合成。在进一步开发这些模型时,我们还将把微软人工智能原则付诸实践。
参考资料:
https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
以上是只需3秒就能偷走你的声音!微软发布语音合成模型VALL-E:网友惊呼「电话诈骗」门槛又拉低了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 微软bing国际版入口地址(bing搜索引擎入口)
Mar 14, 2024 pm 01:37 PM
微软bing国际版入口地址(bing搜索引擎入口)
Mar 14, 2024 pm 01:37 PM
必应(Bing)是微软公司推出的一款网络搜索引擎,搜索功能非常强大,分了国内版和国际版两个入口。这两个版本入口在哪呢?要怎么访问国际版呢?下面就来看看详细内容。 必应中国版网址入口:https://cn.bing.com/ 必应国际版网址入口:https://global.bing.com/ 必应国际版怎么访问? 1、首先输入打开必应的网址入口:https://www.bing.com/ 2、可以看到有国内版跟国际版的选项,我们只需要选择国际版,输入关键词即可。
 为什么微信语音听不到声音?微信语音听不到声音怎么办?
Mar 13, 2024 pm 02:31 PM
为什么微信语音听不到声音?微信语音听不到声音怎么办?
Mar 13, 2024 pm 02:31 PM
为什么微信语音听不到声音?微信是我们日常生活中必不可少的一款通讯工具,其中不少的用户们在使用的过程中出现了问题,例如微信语音听不见声音?那么这要怎么办?下面就让本站来为用户们来仔细的介绍一下微信语音听不到声音怎么办吧。 微信语音听不到声音怎么办 1、手机系统设置的声音比较小或者处于静音状态,这种情况下可以调高音量或者关闭静音模式 2、也有可能没有开启微信扬声器功能,打开“设置”,选择“聊天”选项。 3、点击“聊天”选项过后
 微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
6月3日消息,微软正在积极向所有Windows10用户发送全屏通知,鼓励他们升级到Windows11操作系统。这一举措涉及了那些硬件配置并不支持新系统的设备。自2015年起,Windows10已经占据了近70%的市场份额,稳坐Windows操作系统的霸主地位。然而,市场占有率远超过82%的市场份额,占有率远超过2021年面世的Windows11。尽管Windows11已经推出已近三年,但其市场渗透率仍显缓慢。微软已宣布,将于2025年10月14日后终止对Windows10的技术支持,以便更专注于
 微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
本站8月14日消息,在今天的8月补丁星期二活动日中,微软发布了适用于Windows11系统的累积更新,包括面向22H2和23H2的KB5041585更新,面向21H2的KB5041592更新。上述设备安装8月累积更新之后,本站附上版本号变化如下:21H2设备安装后版本号升至Build22000.314722H2设备安装后版本号升至Build22621.403723H2设备安装后版本号升至Build22631.4037面向Windows1121H2的KB5041585更新主要内容如下:改进:提高了
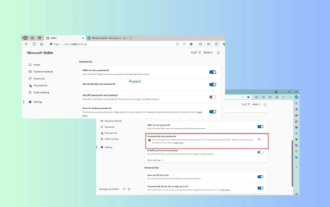 Microsoft Edge升级:自动存密码功能遭禁?!用户惊了!
Apr 19, 2024 am 08:13 AM
Microsoft Edge升级:自动存密码功能遭禁?!用户惊了!
Apr 19, 2024 am 08:13 AM
4月18日消息,近日,一些使用Canary频道的MicrosoftEdge浏览器的用户反映,在升级到最新版本后,他们发现自动保存密码的选项被禁用了。经过调查,这是浏览器升级后的一个微调,而非功能被取消。在使用Edge浏览器访问网站前,用户反馈说浏览器会弹出一个窗口询问是否希望保存该网站的登录密码。选择保存后,在下一次登录时,Edge就会自动填充已保存的账号和密码,为用户提供了极大的便利。但最近的更新类似于微调,修改了默认设置。用户需要在选择保存密码后,再手动在设置中开启自动填充已保存的账号和密码
 微软 Win11 压缩为 7z、TAR 文件的功能已从 24H2 下放到 23H2/22H2 版本
Apr 28, 2024 am 09:19 AM
微软 Win11 压缩为 7z、TAR 文件的功能已从 24H2 下放到 23H2/22H2 版本
Apr 28, 2024 am 09:19 AM
本站4月27日消息,微软本月初向Canary和Dev频道发布了Windows11Build26100预览版更新,预估会成为Windows1124H2更新的候选RTM版本。新版本中最主要的变化在于文件资源管理器、整合Copilot、编辑PNG文件元数据、创建TAR和7z压缩文件等等。@PhantomOfEarth发现,微软已经将24H2版本(Germanium)部分功能下放到23H2/22H2(Nickel)版本中,例如创建TAR和7z压缩文件。如示意图所示,Windows11将支持原生创建TAR
 微软Edge浏览器更新:新增'放大图像”功能,提升用户体验
Mar 21, 2024 pm 01:40 PM
微软Edge浏览器更新:新增'放大图像”功能,提升用户体验
Mar 21, 2024 pm 01:40 PM
3月21日消息,微软近日对其MicrosoftEdge浏览器进行了更新,新增了一项实用的“放大图像”功能。现在,用户在使用Edge浏览器时,只需右键点击图片,便可在弹出的菜单中轻松找到这一新功能。更为便捷的是,用户还可以将光标悬停在图片上方,然后双击Ctrl键,即可快速呼出放大图像的功能。根据小编的了解,最新发布的MicrosoftEdge浏览器已经在Canary频道进行了新功能测试。该浏览器的稳定版中也已经正式推出了实用的“放大图像”功能,为用户提供了更便捷的图片浏览体验。外国科技媒体也对这一
 微软计划2024年下半年在Windows 11中淘汰NTLM,全面转向Kerberos认证
Jun 09, 2024 pm 04:17 PM
微软计划2024年下半年在Windows 11中淘汰NTLM,全面转向Kerberos认证
Jun 09, 2024 pm 04:17 PM
2024年下半年,微软安全官方博客发布了一条消息,以回应安全社区的呼吁。公司计划在2024年下半年发布的Windows11中淘汰NTLANManager(NTLM)认证协议,以提升安全性。根据之前的解释,微软此前已经有过类似的动作。去年10月12日,微软在一份官方新闻稿中就已经提出了一个过渡计划,旨在逐步淘汰NTLM身份验证方式,并推动更多企业和用户转向使用Kerberos。为了帮助那些可能在关闭NTLM身份验证后遇到硬连接(hardwired)应用程序和服务问题的企业,微软提供了IAKerb和
