

Python怎么使用EasyOCR工具识别图像文本

什么是 EasyOCR ?
描述: EasyOCR 是一个用于从图像中提取文本的 python 模块, 它是一种通用的 OCR,既可以读取自然场景文本,也可以读取文档中的密集文本。目前支持 80 多种语言和所有流行的书写脚本,包括:拉丁文、中文、阿拉伯文、梵文、西里尔文等。
EasyOCR 是 PyTorch 实现的一个光学字符识别 (OCR) 工具。
Q: 使用 EasyOCR 可以干什么?
描述: EasyOCR 支持两种方式运行一种是常用的CPU,而另外一种是需要GPU支持并且需安装CUDA环境, 我们使用其可以进行图片中语言文字识别, 例如小程序里图片识别、车辆车牌识别(即车债管理系统)。
安装 EasyOCR
在命令窗口中,使用 pip 安装 EasyOCR 稳定版本。
pip install easyocr
使用 EasyOCR
import easyocr
reader = easyocr.Reader(
['ch_sim', 'en'],
gpu=False,
model_storage_directory='model/.',
user_network_directory='model/.',
)
result = reader.readtext('examples/chinese.jpg')执行上面的代码时,会自动通过网络下载检测与识别模型到指定目录下。
['ch_sim', 'en'],: 指定识别的语言
gpu=False,: 设置是否使用GPU (EasyOCR在GPU上运行效率更高, 没有GPU或者GPU内存不足时设置False)
model_storage_directory='model/.',: 检测与识别模型的存储路径 (没有设置时默认存储在~/.EasyOCR/model目录)
识别结果 result 是一个列表,列表中的每一项都是一个长度为 3 的识别结果,例如 ([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),它们分别是 边界框、检测到的文本 和 置信度 值。
easyocr-server
EasyOCR 服务器是一个用于从图像中提取文本。它是一种通用的 OCR,既可以读取自然场景文本,也可以读取文档中的密集文本。目前支持 80+ 种语言,并且还在扩展。
安装步骤
步骤 0. 从 GitHub 下载 easyocr-server 并安装。
git clone https://github.com/hekaiyou/easyocr-server.git
步骤 1. 使用 PyPI 安装 easyocr、 bottle 和 gevent 模块。
cd easyocr-server pip install -r requirements.txt
验证安装
python main.py
Browser: http://localhost:8080/ocr/
CMD:
curl http://localhost:8080/ocr/ -F "language=en" -F "img_file=@examples/english.png"
验证成功后,您应该能够在浏览器中看到打印的推理结果。
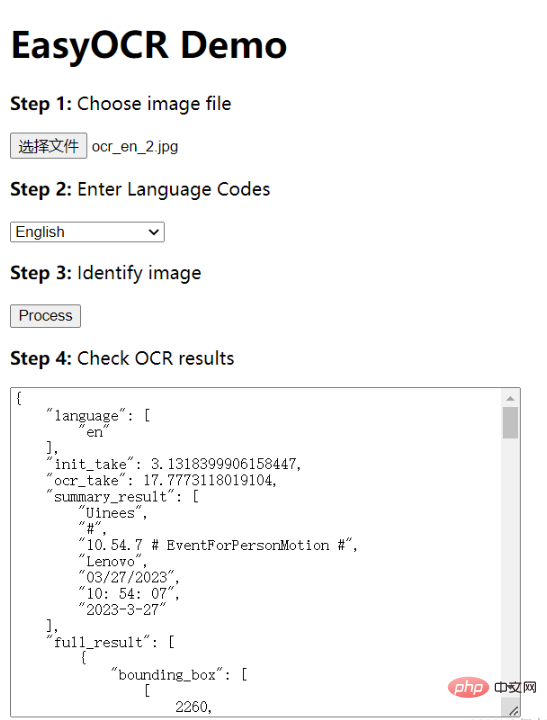
通过 Docker 部署服务
我们提供了一个 Dockerfile 来构建镜像。
docker build -t easyocr-server:latest .
运行它。
docker run -it -v {DATA_DIR}:/workspace/model -p 8083:8080 easyocr-server:latest| Language | Code Name |
|---|---|
| Abaza | abq |
| Adyghe | ady |
| Afrikaans | af |
| Angika | ang |
| Arabic | ar |
| Assamese | as |
| Avar | ava |
| Azerbaijani | az |
| Belarusian | be |
| Bulgarian | bg |
| Bihari | bh |
| Bhojpuri | bho |
| Bengali | bn |
| Bosnian | bs |
| Simplified Chinese | ch_sim |
| Traditional Chinese | ch_tra |
| Chechen | che |
| Czech | cs |
| Welsh | cy |
| Danish | da |
| Dargwa | dar |
| German | de |
| English | en |
| Spanish | es |
| Estonian | et |
| Persian (Farsi) | fa |
| French | fr |
| Irish | ga |
| Goan Konkani | gom |
| Hindi | hi |
| Croatian | hr |
| Hungarian | hu |
| Indonesian | id |
| Ingush | inh |
| Icelandic | is |
| Italian | it |
| Japanese | ja |
| Kabardian | kbd |
| Kannada | kn |
| Korean | ko |
| Kurdish | ku |
| Latin | la |
| Lak | lbe |
| Lezghian | lez |
| Lithuanian | lt |
| Latvian | lv |
| Magahi | mah |
| Maithili | mai |
| Maori | mi |
| Mongolian | mn |
| Marathi | mr |
| Malay | ms |
| Maltese | mt |
| Nepali | ne |
| Newari | new |
| Dutch | nl |
| Norwegian | no |
| Occitan | oc |
| Pali | pi |
| Polish | pl |
| Portuguese | pt |
| Romanian | ro |
| Russian | ru |
| Serbian (cyrillic) | rs_cyrillic |
| Serbian (latin) | rs_latin |
| Nagpuri | sck |
| Slovak | sk |
| Slovenian | sl |
| Albanian | sq |
| Swedish | sv |
| Swahili | sw |
| Tamil | ta |
| Tabassaran | tab |
| Telugu | te |
| Thai | th |
| Tajik | tjk |
| Tagalog | tl |
| Turkish | tr |
| Uyghur | ug |
| Ukranian | uk |
| Urdu | ur |
| Uzbek | uz |
| Vietnamese | vi |
以上是Python怎么使用EasyOCR工具识别图像文本的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何在LAMP架构下高效整合Node.js或Python服务?
Apr 01, 2025 pm 02:48 PM
如何在LAMP架构下高效整合Node.js或Python服务?
Apr 01, 2025 pm 02:48 PM
在LAMP架构下整合Node.js或Python服务许多网站开发者都面临这样的问题:已有的LAMP(Linux Apache MySQL PHP)架构网站需要...
 使用Scapy爬虫时,管道持久化存储文件无法写入的原因是什么?
Apr 01, 2025 pm 04:03 PM
使用Scapy爬虫时,管道持久化存储文件无法写入的原因是什么?
Apr 01, 2025 pm 04:03 PM
使用Scapy爬虫时,管道持久化存储文件无法写入的原因探讨在学习使用Scapy爬虫进行数据抓取时,经常会遇到一�...
 Python跨平台桌面应用开发:哪个GUI库最适合你?
Apr 01, 2025 pm 05:24 PM
Python跨平台桌面应用开发:哪个GUI库最适合你?
Apr 01, 2025 pm 05:24 PM
Python跨平台桌面应用开发库的选择许多Python开发者都希望开发出能够在Windows和Linux系统上都能运行的桌面应用程...
 Python进程池处理并发TCP请求导致客户端卡死的原因是什么?
Apr 01, 2025 pm 04:09 PM
Python进程池处理并发TCP请求导致客户端卡死的原因是什么?
Apr 01, 2025 pm 04:09 PM
Python进程池处理并发TCP请求导致客户端卡死的解析在使用Python进行网络编程时,高效处理并发TCP请求至关重要。...
 如何查看Python functools.partial对象内部封装的原始函数?
Apr 01, 2025 pm 04:15 PM
如何查看Python functools.partial对象内部封装的原始函数?
Apr 01, 2025 pm 04:15 PM
深入探讨Pythonfunctools.partial对象的查看方法在使用Python的functools.partial...
 Python沙漏图形绘制:如何避免变量未定义错误?
Apr 01, 2025 pm 06:27 PM
Python沙漏图形绘制:如何避免变量未定义错误?
Apr 01, 2025 pm 06:27 PM
Python入门:沙漏图形绘制及输入校验本文将解决一个Python新手在沙漏图形绘制程序中遇到的变量定义问题。代码...
 在Python中如何优化处理高分辨率图片以精确查找白色圆形区域?
Apr 01, 2025 pm 06:12 PM
在Python中如何优化处理高分辨率图片以精确查找白色圆形区域?
Apr 01, 2025 pm 06:12 PM
在Python中如何处理高分辨率图片以查找白色区域?处理一张9000x7000像素的高分辨率图片,如何准确找出图片中两...
 如何用Python高效统计并排序大型商品数据集?
Apr 01, 2025 pm 08:03 PM
如何用Python高效统计并排序大型商品数据集?
Apr 01, 2025 pm 08:03 PM
数据转换与统计:高效处理大型数据集本文将详细介绍如何将一个包含商品信息的数据列表,转换为另一个包含...
