
4 月初,Meta 发布了史上首个图像分割基础模型--SAM(Segment Anything Model)[1]。作为分割模型,SAM 的能力强大,操作使用方式也十分友好,比如用户简单地点击来选择对应物体,物体就会立即被分割出来,且分割结果十分精准。截至 4 月 15 号,SAM 的 GitHub 仓库的 Star 数高达 26k。

如何利用好如此强大的「分割一切」模型,并拓展到更加有实际需求的应用场景至关重要。例如,当 SAM 遇上实用的图像修补(Image Inpainting)任务会碰撞出什么样的火花?
来自中国科学技术大学和东方理工高等研究院的研究团队给出了令人惊艳的答案。基于 SAM,他们提出「修补一切」(Inpaint Anything,简称 IA)模型。区别于传统图像修补模型,IA 模型无需精细化操作生成掩码,支持了一键点击标记选定对象,IA 即可实现移除一切物体(Remove Anything)、填补一切内容(Fill Anything)、替换一切场景(Replace Anything),涵盖了包括目标移除、目标填充、背景替换等在内的多种典型图像修补应用场景。

尽管当前图像修补系统取得了重大进展,但它们在选择掩码图和填补空洞方面仍然面临困难。基于 SAM,研究者首次尝试无需掩码(Mask-Free)图像修复,并构建了「点击再填充」(Clicking and Filling) 的图像修补新范式,他们将其称为修补一切 (Inpaint Anything)(IA)。IA 背后的核心思想是结合不同模型的优势,以建立一个功能强大且用户友好的图像修复系统。
IA 拥有三个主要功能:(i) 移除一切(Remove Anything):用户只需点击一下想要移除的物体,IA 将无痕地移除该物体,实现高效「魔法消除」;(ii) 填补一切(Fill Anything):同时,用户还可以进一步通过文本提示(Text Prompt)告诉 IA 想要在物体内填充什么,IA 随即通过驱动已嵌入的 AIGC(AI-Generated Content)模型(如 Stable Diffusion [2])生成相应的内容填充物体,实现随心「内容创作」;(iii) 替换一切(Replace Anything):用户也可以通过点击选择需要保留的物体对象,并用文本提示告诉 IA 想要把物体的背景替换成什么,即可将物体背景替换为指定内容,实现生动「环境转换」。IA 的整体框架如下图所示:
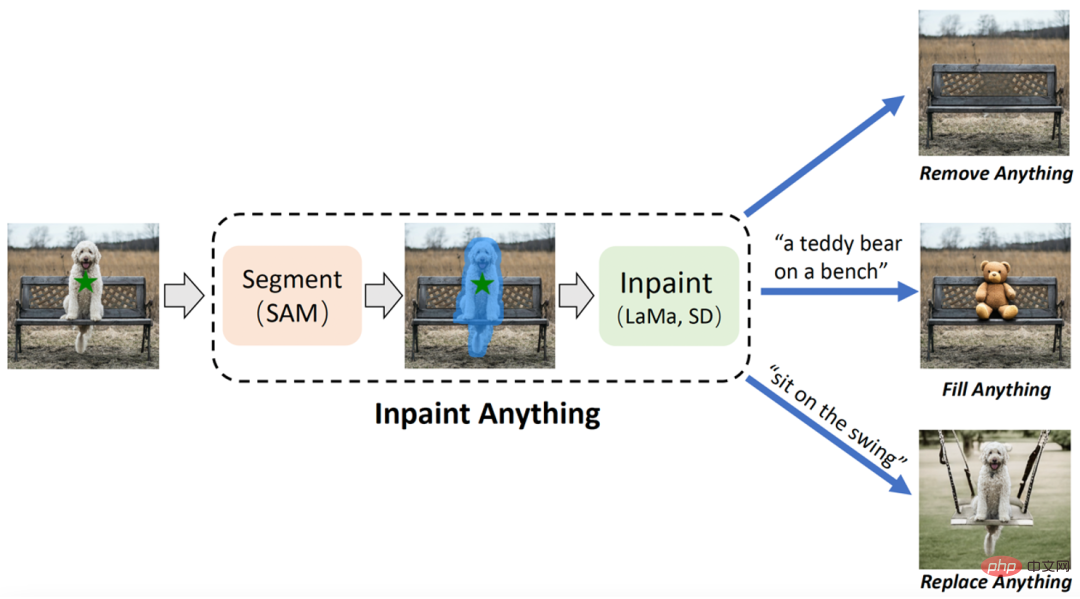
Inpaint Anything(IA)示意图。用户可以通过单击来选择图像中的任何物体。借助强大的视觉模型,如 SAM [1]、LaMa [3] 和 Stable Diffusion (SD) [3],IA 能够平滑移除选定物体(即 Remove Anything)。进一步地,通过向 IA 输入文本提示,用户可以用任何想要的内容填充物体(即 Fill Anything)或者任意替换对象的物体(即 Replace Anything)。
移除一切

移除一切(Remove Anything)示意图
「移除一切」步骤如下:
填补一切

填补一切(Fill Anything)示意图,图中使用的文本提示:a teddy bear on a bench
「填补一切」步骤如下:
替换一切
替换一切(Replace Anything)示意图,图中使用的文本提示:a man in office
「填补一切」步骤如下:
研究者随后在 COCO 数据集 [4]、LaMa 测试数据集 [3] 和他们自己用手机拍摄的 2K 高清图像上对 Inpaint Anything 进行测试。值得注意的是,研究者的模型还支持 2K 高清图和任意长宽比,这使得 IA 系统在各种集成环境和现有框架中都能够实现高效的迁移应用。
移除一切实验结果




填充一切实验结果
文本提示:a camera lens in the hand

文本提示:an aircraft carrier on the sea

文本提示:a sports car on a road

文本提示:a Picasso painting on the wall
替换一切实验结果

文本提示:sit on the swing

文本提示:breakfast

文本提示:a bus, on the center of a country road, summer

文本提示:crossroad in the city
研究者建立这样一个有趣的项目,来展示充分利用现有大型人工智能模型所能获得的强大能力,并揭示「可组合人工智能」(Composable AI)的无限潜力。项目所提出的 Inpaint Anything (IA) 是一种多功能的图像修补系统,融合了物体移除、内容填补、场景替换等功能(更多的功能正在路上敬请期待)。
IA 结合了 SAM、图像修补模型(例如 LaMa)和 AIGC 模型(例如 Stable Diffusion)等视觉基础模型,实现了对用户操作友好的无掩码化图像修复,同时支持「点击删除,提示填充」的等「傻瓜式」人性化操作。此外,IA 还可以处理具有任意长宽比和 2K 高清分辨率的图像,且不受图像原始内容限制。
目前,项目已经完全开源。最后,欢迎大家分享和推广 Inpaint Anything (IA) ,也很期待看见更多基于 IA 所拓展的新项目。未来,研究者将进一步挖掘 Inpaint Anything (IA) 的潜力 以支持更多实用的新功能,如细粒度图像抠图、编辑等,并将其应用到更多现实应用中。
以上是当「分割一切」遇上图像修补:无需精细标记,单击物体实现物体移除、内容填补、场景替换的详细内容。更多信息请关注PHP中文网其他相关文章!





















