

威大哥大等联合发文!最新多模态大模型LLaVA问世,水平直逼GPT-4

视觉指令微调火了。
这篇论文名为Visual Instruction Tuning,由威斯康星大学麦迪逊分校,微软研究院和哥伦比亚大学共同出品。
作者包括Haotian Liu,Chunyuan Li,Qingyang Wu和Yong Jae Lee。

同时,研究人员也在GitHub上开源了他们的代码、模型和数据集。论文也发布在了Arxiv上。
讲解
那么LLaVA的功能究竟是什么呢?如果一头扎进论文,不熟悉的朋友可能会有些陌生。
我们先看看LLaVA自己怎么说。
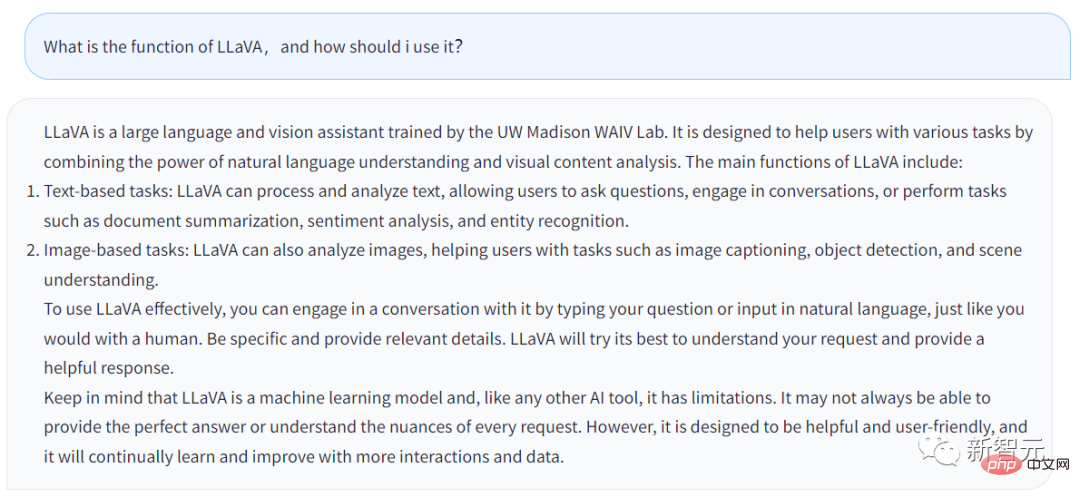
以上回答生成自LLaVA的Chatbot,我输入的问题是,LLaVA的功能是什么,用户该如何利用它?
回答如下:
LLaVA是一个大语言和视觉助手,在UW Madison WAIV实验室经受的训练。LLaVA被设计出来的目的,就是帮助用户处理各类任务,方法则是借助自然语言理解的能力和视觉内容分析的能力。
LLaVA的主要功能包括:
· 以文本为基础的任务:LLaVA可以处理并分析文本,允许用户问问题,LLaVA可以和用户交谈,或者完成用户输入的任务,比如说提炼文件概要,情感分析,实体识别等等。
· 以图像为基础的任务:LLaVA可以分析图像,描述图像,进行物体识别,分析理解场景。
用户如果想更好地应用LLaVA,可以直接和LLaVA进行交谈,就像和人类之间对话一样。尽可能多的提供细节,LLaVA就会生成出一个更完善的答案。
同时应该记住,说到底LLaVA是一个机器学习模型,是一个AI工具。只要是工具,就有其限制。LLaVA不一定每一次都能完美地回答用户输入的问题。
当然,LLaVA也在不断学习和完善,其功能也会越来越强大。
总的来说,从LLaVA的回答中可以看出,在Chatbot这方面,和GPT的功能差不了太多。但是LLaVA可以处理一些有关图像的任务。
表现出彩
研究人员在Arxiv的论文中详细介绍了LLaVA的技术细节。
要知道使用机器生成的指令跟随数据对大型语言模型(LLMs)进行指令微调,提高了新任务的零点能力,但这个想法在多模态领域的探索较少。
在论文中,研究人员首次尝试使用仅有语言的GPT-4来生成多模态语言图像的指令跟随数据。
通过对这种生成的数据进行指令调整,研究人员引入了LLaVA:这是一个大型语言和视觉助手,是一个端到端的训练有素的大型多模态模型,它连接了一个视觉编码器和LLM,用于通用的视觉和语言理解。
早期实验表明,LLaVA展示了令人印象深刻的多模态聊天能力,有时在未见过的图像/指令上都能输出多模态GPT-4的表现,在合成的多模态指令跟随数据集上与GPT-4相比,获得了85.1%的相对分数。
当对Science杂志进行微调时,LLaVA和GPT-4的协同作用达到了92.53%的新的最先进的准确性。
研究人员公开了GPT-4生成的视觉指令调整的数据、模型和代码库。
多模态模型
首先厘清定义。
大型多模态模型指的就是一种基于机器学习技术的模型,能够处理和分析多种输入类型,如文本和图像。
这些模型设计用于处理更广泛的任务,并且能够理解不同形式的数据。通过将文本和图像作为输入,这些模型可以提高理解和编解释的能力,从而生成更准确和相关的回答。
人类通过视觉和语言等多种渠道与世界互动,因为每个单独的渠道在代表和传达某些世界概念方面都有独特的优势,从而有利于更好地理解世界。
而人工智能的核心愿望之一是开发一个通用的助手,能够有效地遵循多模态的视觉和语言指令,与人类的意图一致,完成各种真实世界的任务。
因此,开发者社区见证了对开发语言增强的基础视觉模型的新兴趣,在开放世界的视觉理解方面具有强大的能力,如分类、检测、分割、描述,以及视觉生成和编辑。
在这些功能中,每个任务都由一个单一的大型视觉模型独立解决,在模型设计中隐含考虑了任务指令。
此外,语言只被用来描述图像内容。虽然这允许语言在将视觉信号映射到语言语义方面发挥重要作用——这是人类交流的常见渠道。但这会导致模型通常具有固定的界面,互动性和对用户指令的适应性有限。
而大型语言模型(LLM)表明,语言可以发挥更广泛的作用:通用助手的通用界面,各种任务指令可以明确地用语言表示,并引导端到端训练有素的神经助手切换到感兴趣的任务来解决它。
例如,最近ChatGPT和GPT-4的成功,证明了这种LLM在遵循人类指令方面的能力,并激发了人们对开发开源LLM的巨大兴趣。
LLaMA就是一个开源的LLM,其性能与GPT-3相当。正在进行的工作利用各种机器生成的高质量指令跟随样本来提高LLM的对齐能力,与专有LLM相比,报告了令人印象深刻的性能。重要的是,这一行的工作是纯文本的。
在本文中,研究人员提出了视觉指令调整,这是将指令调整扩展到多模态空间的首次尝试,它为建立一个通用的视觉助手铺平了道路。具体来说,论文的主要内容包括:
多模态的指令跟随数据。一个关键的挑战是缺乏视觉语言指令-跟随数据。我们提出了一个数据改革的观点和管道,使用ChatGPT/GPT-4将图像-文本对转换为适当的指令-跟随格式。
大型多模态模型。研究人员开发了一个大型多模态模型(LMM),通过连接CLIP的开放集视觉编码器和语言解码器LaMA,并在生成的教学视觉——语言数据上对它们进行端到端的微调。实证研究验证了使用生成的数据进行LMM指令调谐的有效性,并为建立一个通用的指令跟随的视觉代理提出了实用的建议。通过GPT 4,研究小组在Science QA多模态推理数据集上取得了最先进的性能。
开源。研究小组向公众发开了以下内容:生成的多模态指令数据、用于数据生成和模型训练的代码库、模型检查点,以及一个视觉聊天演示。
成果展示

可以看到,LLaVA能处理各类问题,且生成的回答既全面又富有逻辑。
LLaVA表现出一些接近GPT-4水平的多模态能力,在视觉聊天方面,GPT-4相对评分85%。
而在推理问答方面,LLaVA甚至达到了新SoTA——92.53%,击败多模态思维链。
以上是威大哥大等联合发文!最新多模态大模型LLaVA问世,水平直逼GPT-4的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
本月初,来自MIT等机构的研究者提出了一种非常有潜力的MLP替代方法——KAN。KAN在准确性和可解释性方面表现优于MLP。而且它能以非常少的参数量胜过以更大参数量运行的MLP。比如,作者表示,他们用KAN以更小的网络和更高的自动化程度重现了DeepMind的结果。具体来说,DeepMind的MLP有大约300,000个参数,而KAN只有约200个参数。KAN与MLP一样具有强大的数学基础,MLP基于通用逼近定理,而KAN基于Kolmogorov-Arnold表示定理。如下图所示,KAN在边上具
 微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
6月3日消息,微软正在积极向所有Windows10用户发送全屏通知,鼓励他们升级到Windows11操作系统。这一举措涉及了那些硬件配置并不支持新系统的设备。自2015年起,Windows10已经占据了近70%的市场份额,稳坐Windows操作系统的霸主地位。然而,市场占有率远超过82%的市场份额,占有率远超过2021年面世的Windows11。尽管Windows11已经推出已近三年,但其市场渗透率仍显缓慢。微软已宣布,将于2025年10月14日后终止对Windows10的技术支持,以便更专注于
 微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
本站8月14日消息,在今天的8月补丁星期二活动日中,微软发布了适用于Windows11系统的累积更新,包括面向22H2和23H2的KB5041585更新,面向21H2的KB5041592更新。上述设备安装8月累积更新之后,本站附上版本号变化如下:21H2设备安装后版本号升至Build22000.314722H2设备安装后版本号升至Build22621.403723H2设备安装后版本号升至Build22631.4037面向Windows1121H2的KB5041585更新主要内容如下:改进:提高了
 特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人Optimus最新视频出炉,已经可以在厂子里打工了。正常速度下,它分拣电池(特斯拉的4680电池)是这样的:官方还放出了20倍速下的样子——在小小的“工位”上,拣啊拣啊拣:这次放出的视频亮点之一在于Optimus在厂子里完成这项工作,是完全自主的,全程没有人为的干预。并且在Optimus的视角之下,它还可以把放歪了的电池重新捡起来放置,主打一个自动纠错:对于Optimus的手,英伟达科学家JimFan给出了高度的评价:Optimus的手是全球五指机器人里最灵巧的之一。它的手不仅有触觉
 Yolov10:详解、部署、应用一站式齐全!
Jun 07, 2024 pm 12:05 PM
Yolov10:详解、部署、应用一站式齐全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显着进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显着的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
 全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐LLM方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管RLHF方法的结果很出色,但其中涉及到了一些优化难题。其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。近段时间已有一些研究者探索了更简单的离线算法,其中之一便是直接偏好优化(DPO)。DPO是通过参数化RLHF中的奖励函数来直接根据偏好数据学习策略模型,这样就无需显示式的奖励模型了。该方法简单稳定
 无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显着突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。 StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
