

使用树状图可视化聚类

一般情况下,我们都是使用散点图进行聚类可视化,但是某些的聚类算法可视化时散点图并不理想,所以在这篇文章中,我们介绍如何使用树状图(Dendrograms)对我们的聚类结果进行可视化。
树状图
树状图是显示对象、组或变量之间的层次关系的图表。树状图由在节点或簇处连接的分支组成,它们代表具有相似特征的观察组。分支的高度或节点之间的距离表示组之间的不同或相似程度。也就是说分支越长或节点之间的距离越大,组就越不相似。分支越短或节点之间的距离越小,组越相似。
树状图对于可视化复杂的数据结构和识别具有相似特征的数据子组或簇很有用。它们通常用于生物学、遗传学、生态学、社会科学和其他可以根据相似性或相关性对数据进行分组的领域。
背景知识:
“树状图”一词来自希腊语“dendron”(树)和“gramma”(绘图)。1901年,英国数学家和统计学家卡尔皮尔逊用树状图来显示不同植物种类之间的关系。他称这个图为“聚类图”。这可以被认为是树状图的首次使用。
数据准备
我们将使用几家公司的真实股价来进行聚类。为了方便获取,所以使用 Alpha Vantage 提供的免费 API 来收集数据。Alpha Vantage同时提供免费 API 和高级 API,通过API访问需要密钥,请参考他的网站。
import pandas as pd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}科技、零售、石油和天然气以及其他行业中挑选了 20 家公司。
import time
all_data={}
for key,value in companies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response = requests.get(url)
data = response.json()
time.sleep(15)
if 'Time Series (Daily)' in data and data['Time Series (Daily)']:
df = pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns = {'1. open':key}, inplace = True)
all_data[key]=df[key]在上面的代码在 API 调用之间设置了 15 秒的暂停,这样可以保证不会因为太频繁被封掉。
# find common dates among all data frames common_dates = None for df_key, df in all_data.items(): if common_dates is None: common_dates = set(df.index) else: common_dates = common_dates.intersection(df.index) common_dates = sorted(list(common_dates)) # create new data frame with common dates as index df_combined = pd.DataFrame(index=common_dates) # reindex each data frame with common dates and concatenate horizontally for df_key, df in all_data.items(): df_combined = pd.concat([df_combined, df.reindex(common_dates)], axis=1)
将上面的数据整合成我们需要的DF,下面就可以直接使用了
层次聚类
层次聚类(Hierarchical clustering)是一种用于机器学习和数据分析的聚类算法。它使用嵌套簇的层次结构,根据相似性将相似对象分组到簇中。该算法可以是聚集性的可以从单个对象开始并将它们合并成簇,也可以是分裂的,从一个大簇开始并递归地将其分成较小的簇。
需要注意的是并非所有聚类方法都是层次聚类方法,只能在少数聚类算法上使用树状图。
聚类算法我们将使用 scipy 模块中提供的层次聚类。
1、自上而下聚类
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform top-down clustering
clustering = sch.linkage(dist_mat, method='complete')
cuts = sch.cut_tree(clustering, n_clusters=[3, 4])
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Top-Down Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()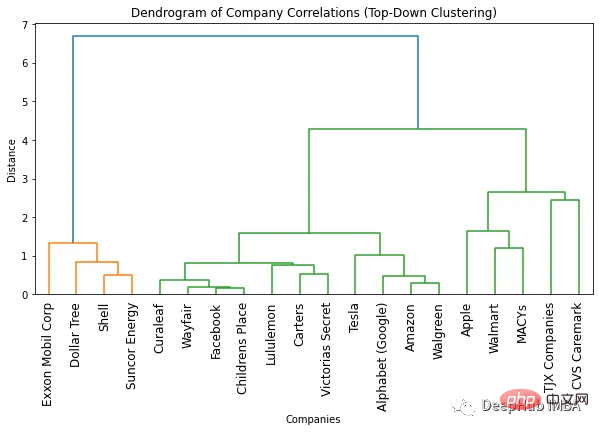
如何根据树状图确定最佳簇数
找到最佳簇数的最简单方法是查看生成的树状图中使用的颜色数。最佳簇的数量比颜色的数量少一个就可以了。所以根据上面这个树状图,最佳聚类的数量是两个。
另一种找到最佳簇数的方法是识别簇间距离突然变化的点。这称为“拐点”或“肘点”,可用于确定最能捕捉数据变化的聚类数量。上面图中我们可以看到,不同数量的簇之间的最大距离变化发生在 1 和 2 个簇之间。因此,再一次说明最佳簇数是两个。
从树状图中获取任意数量的簇
使用树状图的一个优点是可以通过查看树状图将对象聚类到任意数量的簇中。例如,需要找到两个聚类,可以查看树状图上最顶部的垂直线并决定聚类。比如在这个例子中,如果需要两个簇,那么第一个簇中有四家公司,第二个集群中有 16 个公司。如果我们需要三个簇就可以将第二个簇进一步拆分为 11 个和 5 个公司。如果需要的更多可以依次类推。
2、自下而上聚类
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform bottom-up clustering
clustering = sch.linkage(dist_mat, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Bottom-Up Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()
我们为自下而上的聚类获得的树状图类似于自上而下的聚类。最佳簇数仍然是两个(基于颜色数和“拐点”方法)。但是如果我们需要更多的集群,就会观察到一些细微的差异。这也很正常,因为使用的方法不一样,导致结果会有一些细微的差异。
总结
树状图是可视化复杂数据结构和识别具有相似特征的数据子组或簇的有用工具。在本文中,我们使用层次聚类方法来演示如何创建树状图以及如何确定最佳聚类数。对于我们的数据树状图有助于理解不同公司之间的关系,但它们也可以用于其他各种领域,以理解数据的层次结构。
以上是使用树状图可视化聚类的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 四款值得推荐的AI辅助编程工具
Apr 22, 2024 pm 05:34 PM
四款值得推荐的AI辅助编程工具
Apr 22, 2024 pm 05:34 PM
这个AI辅助编程工具在这个AI迅速发展的阶段,挖掘出了一大批好用的AI辅助编程工具。AI辅助编程工具能够提高开发效率、改善代码质量、降低bug率,是现代软件开发过程中的重要助手。今天大姚给大家分享4款AI辅助编程工具(并且都支持C#语言),希望对大家有所帮助。https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot是一款AI编码助手,可帮助你更快、更省力地编写代码,从而将更多精力集中在问题解决和协作上。Git
 AI程序员哪家强?探索Devin、通义灵码和SWE-agent的潜力
Apr 07, 2024 am 09:10 AM
AI程序员哪家强?探索Devin、通义灵码和SWE-agent的潜力
Apr 07, 2024 am 09:10 AM
2022年3月3日,距世界首个AI程序员Devin诞生不足一个月,普林斯顿大学的NLP团队开发了一个开源AI程序员SWE-agent。它利用GPT-4模型在GitHub存储库中自动解决问题。SWE-agent在SWE-bench测试集上的表现与Devin相似,平均耗时93秒,解决了12.29%的问题。SWE-agent通过与专用终端交互,可以打开、搜索文件内容,使用自动语法检查、编辑特定行,以及编写和执行测试。(注:以上内容为原内容微调,但保留了原文中的关键信息,未超过指定字数限制。)SWE-A
 五大热门Go语言库汇总:开发必备利器
Feb 22, 2024 pm 02:33 PM
五大热门Go语言库汇总:开发必备利器
Feb 22, 2024 pm 02:33 PM
五大热门Go语言库汇总:开发必备利器,需要具体代码示例Go语言自从诞生以来,受到了广泛的关注和应用。作为一门新兴的高效、简洁的编程语言,Go的快速发展离不开丰富的开源库的支持。本文将介绍五大热门的Go语言库,这些库在Go开发中扮演了至关重要的角色,为开发者提供了强大的功能和便捷的开发体验。同时,为了更好地理解这些库的用途和功能,我们会结合具体的代码示例进行讲
 学习如何利用Go语言开发移动应用程序
Mar 28, 2024 pm 10:00 PM
学习如何利用Go语言开发移动应用程序
Mar 28, 2024 pm 10:00 PM
Go语言开发移动应用程序教程随着移动应用市场的不断蓬勃发展,越来越多的开发者开始探索如何利用Go语言开发移动应用程序。作为一种简洁高效的编程语言,Go语言在移动应用开发中也展现出了强大的潜力。本文将详细介绍如何利用Go语言开发移动应用程序,并附上具体的代码示例,帮助读者快速入门并开始开发自己的移动应用。一、准备工作在开始之前,我们需要准备好开发环境和工具。首
 五种选择的可视化工具,用于探索Kafka
Feb 01, 2024 am 08:03 AM
五种选择的可视化工具,用于探索Kafka
Feb 01, 2024 am 08:03 AM
Kafka可视化工具的五种选择ApacheKafka是一个分布式流处理平台,能够处理大量实时数据。它广泛用于构建实时数据管道、消息队列和事件驱动的应用程序。Kafka的可视化工具可以帮助用户监控和管理Kafka集群,并更好地理解Kafka数据流。以下是对五种流行的Kafka可视化工具的介绍:ConfluentControlCenterConfluent
 Android开发最适合的Linux发行版是哪个?
Mar 14, 2024 pm 12:30 PM
Android开发最适合的Linux发行版是哪个?
Mar 14, 2024 pm 12:30 PM
Android开发是一项繁忙而又令人兴奋的工作,而选择一个适合的Linux发行版来进行开发则显得尤为重要。在众多的Linux发行版中,究竟哪一个最适合Android开发呢?本文将从几个方面来探讨这一问题,并给出具体的代码示例。首先,我们来看一下目前流行的几个Linux发行版:Ubuntu、Fedora、Debian、CentOS等,它们都有各自的优点和特点。
 了解VSCode:这款工具到底是用来干什么的?
Mar 25, 2024 pm 03:06 PM
了解VSCode:这款工具到底是用来干什么的?
Mar 25, 2024 pm 03:06 PM
《了解VSCode:这款工具到底是用来干什么的?》作为一个程序员,无论是初学者还是资深开发者,都离不开代码编辑工具的使用。在众多编辑工具中,VisualStudioCode(简称VSCode)作为一款开源、轻量级、强大的代码编辑器备受开发者欢迎。那么,VSCode到底是用来干什么的?本文将深入探讨VSCode的功能和用途,并提供具体的代码示例,以帮助读者
 Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言作为一种快速、高效的编程语言,在后端开发领域广受欢迎。然而,很少有人将Go语言与前端开发联系起来。事实上,使用Go语言进行前端开发不仅可以提高效率,还能为开发者带来全新的视野。本文将探讨使用Go语言进行前端开发的可能性,并提供具体的代码示例,帮助读者更好地了解这一领域。在传统的前端开发中,通常会使用JavaScript、HTML和CSS来构建用户界面
