

过去两年,斯坦福大学 Hazy Research 实验室一直在从事一项重要的工作:增加序列长度。
他们有一种观点:更长的序列将开启机器学习基础模型的新时代 —— 模型可以从更长的上下文、多种媒体源、复杂的演示等中学习。
目前,这项研究已经取得了新进展。Hazy Research 实验室的 Tri Dao 和 Dan Fu 主导了 FlashAttention 算法的研究和推广,他们证明了 32k 的序列长度是可能的,且在当前这个基础模型时代将得到广泛应用(OpenAI、Microsoft、NVIDIA 和其他公司的模型都在使用 FlashAttention 算法)。
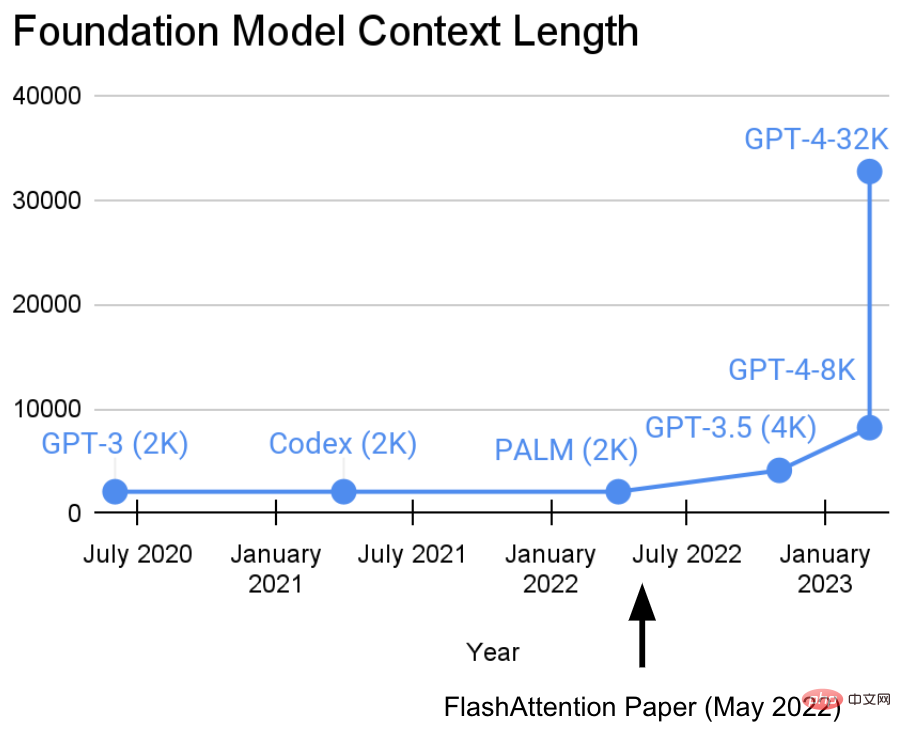
正如 GPT4 的相关资料所指出的,它允许近 50 页的文本作为上下文,而且像 Deepmind Gato 使用图像作为上下文那样实现 tokenization/patching。
在这篇文章中,作者介绍了关于在高层级上增加序列长度的新方法,并提供了连接一组新原语的「桥梁」。
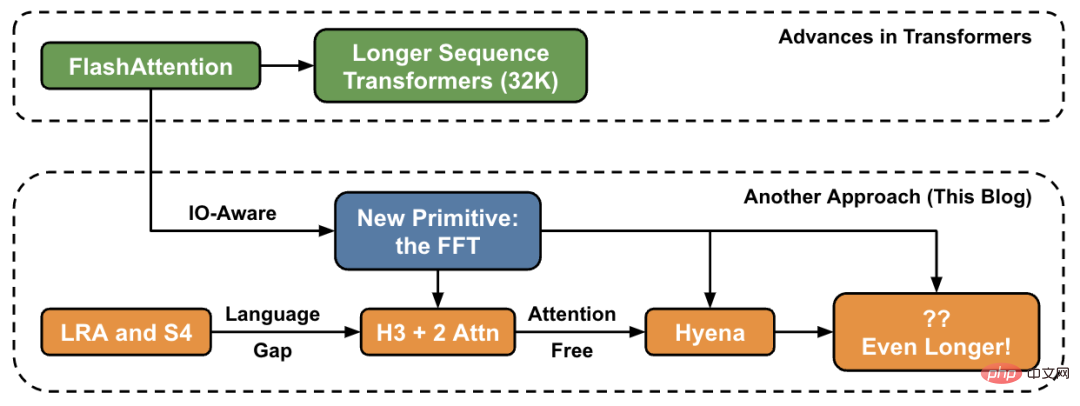
Transformer 变得越来越深,越来越宽,但在长序列上训练它们仍然很困难。研究人员遇到的一个基本问题是,Transformer 的注意力层在序列长度方面是按二次方比例增长:就是说从 32k 长度增加到 64k 长度,成本不只增加 2 倍,而是增加了 4 倍。因此,这促使研究人员探索具有线性时间复杂度的序列长度模型。在 Hazy Research 实验室,这项工作从 Hippo 开始,然后是 S4、H3,再到现在的 Hyena。这些模型有可能处理数百万、甚至十亿级别的上下文长度。
FlashAttention 可以加速注意力并减少其内存占用 —— 无需任何近似。「自从我们在 6 个月前发布 FlashAttention 以来,我们很高兴看到许多组织和研究实验室采用 FlashAttention 来加速他们的训练和推理。」博客中写道。
FlashAttention 是一种对注意力计算进行重新排序并利用经典技术(平铺、重新计算)加快速度并将内存使用从序列长度的二次减少到线性的算法。对于每个注意力头,为了减少内存读 / 写,FlashAttention 使用经典的平铺技术将查询、键和值块从 GPU HBM(其主内存)加载到 SRAM(其快速缓存),计算关于该块的注意力,并将输出写回 HBM。在大多数情况下,这种内存读 / 写的减少带来了显著的加速(2-4 倍)。
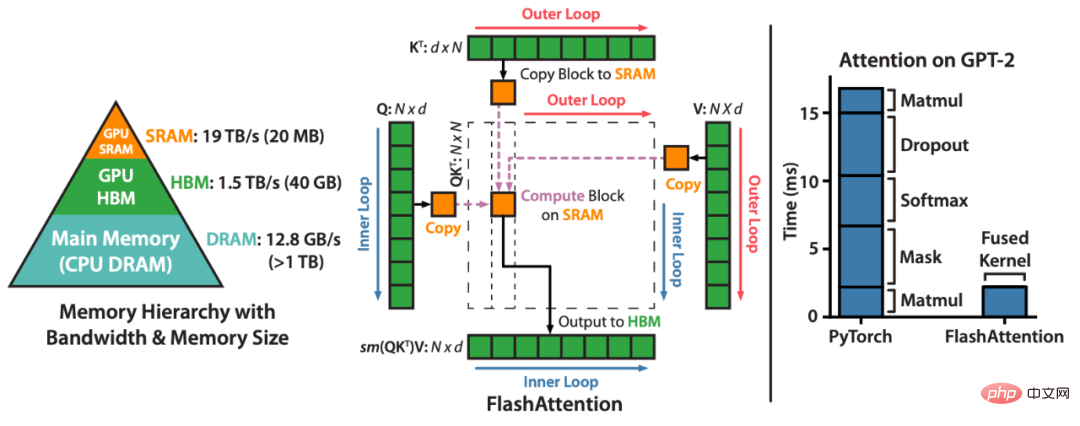
接下来,让我们看一下研究细节。
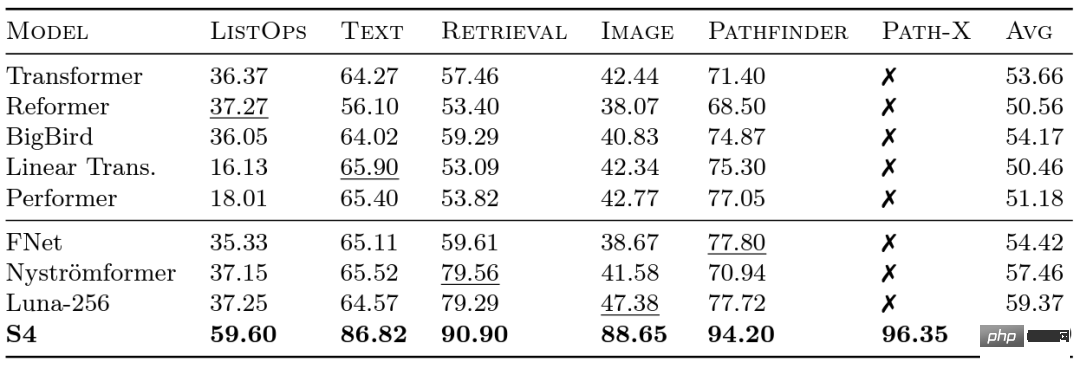
谷歌的研究人员在 2020 年推出了 Long Range Arena (LRA) 基准测试,以评估不同模型处理长程依赖的能力。LRA 能够测试一系列任务,涵盖多种不同的数据类型和模式,例如文本、图像和数学表达式,序列长度可达 16K(Path-X:对已展开成像素的图像进行分类,没有任何空间归纳偏置)。关于将 Transformer 扩展到更长的序列方面已经有很多出色的工作,但其中许多似乎会牺牲准确性(如下图所示)。请注意 Path-X 那一列:所有 Transformer 方法及其变体表现甚至不如随机猜测。
现在让我们认识一下由 Albert Gu 主导研发的 S4。受到 LRA 基准测试结果的启发,Albert Gu 想要找出如何更好地对长程依赖关系建模,在正交多项式和递归模型与卷积模型之间关系的长期研究基础上,推出了 S4—— 一种基于结构化状态空间模型(SSMs)的新的序列模型。
很关键的一点是,SSM 在将长度为 N 的序列拓展到 2N 时的时间复杂度为 ,而不像注意力机制一样呈平方级别增长!S4 成功地对 LRA 中的长程依赖进行了建模,并成为首个在 Path-X 上获得高于平均性能的模型(现在可以获得 96.4%的准确度!)。自 S4 发布以来,许多研究人员在此基础上发展和创新,出现了像 Scott Linderman 团队的 S5 模型、Ankit Gupta 的 DSS(以及 Hazy Research 实验室后续的 S4D)、Hasani 和 Lechner 的 Liquid-S4 等新模型。
,而不像注意力机制一样呈平方级别增长!S4 成功地对 LRA 中的长程依赖进行了建模,并成为首个在 Path-X 上获得高于平均性能的模型(现在可以获得 96.4%的准确度!)。自 S4 发布以来,许多研究人员在此基础上发展和创新,出现了像 Scott Linderman 团队的 S5 模型、Ankit Gupta 的 DSS(以及 Hazy Research 实验室后续的 S4D)、Hasani 和 Lechner 的 Liquid-S4 等新模型。
另外,当 Hazy Research 发布 FlashAttention 时,已经能够增加 Transformer 的序列长度。他们还发现,仅通过将序列长度增加到 16K,Transformer 也能在 Path-X 上获得不凡的表现(63%)。
但是 S4 在语言建模方面的质量存在的差距高达 5% 的困惑度(对于上下文,这是 125M 模型和 6.7B 模型之间的差距)。为了缩小这一差距,研究人员研究了诸如联想回忆之类的合成语言,以确定语言应该具备哪些属性。最终设计了 H3(Hungry Hungry Hippos):一个堆叠两个 SSM 的新层,并将它们的输出与乘法门相乘。
使用 H3,Hazy Research 的研究人员替换了 GPT 式 Transformer 中的几乎所有注意力层,并能够在从 Pile 训练的 400B 规模的 token 时,在困惑度和下游评估方面与 transformer 相媲美。
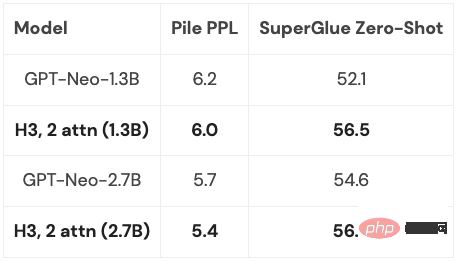
由于 H3 层建立在 SSM 上,因此在序列长度上,它的计算复杂度也以 的速度增长。两个注意力层使得整个模型的复杂度仍然是
的速度增长。两个注意力层使得整个模型的复杂度仍然是
 ,稍后会详细讨论这个问题。
,稍后会详细讨论这个问题。
当然,Hazy Research 不是唯一考虑这个方向的人:GSS 也发现带有门控的 SSM 可以与语言建模中的注意力很好地协同工作(这启发了 H3),Meta 发布了 Mega 模型,它也将 SSM 和注意力结合起来,BiGS 模型则替换了 BERT-style 模型中的注意力,而 RWKV 一直在研究完全循环的方法。
根据前面的一系列工作,启发 Hazy Research 的研究人员开发了新的架构:Hyena。他们试图摆脱 H3 中最后两个注意力层,并获得一个几乎呈线性增长的模型,以适应更长的序列长度。事实证明,两个简单的想法是找到答案的关键:
Hyena 首次提出了完全近线性时间卷积模型,它可以在困惑度和下游任务上与 Transformer 相匹配,并在实验中取得了很好的结果。并且在 PILE 的子集上训练了中小型模型,其表现与 Transformer 相媲美:
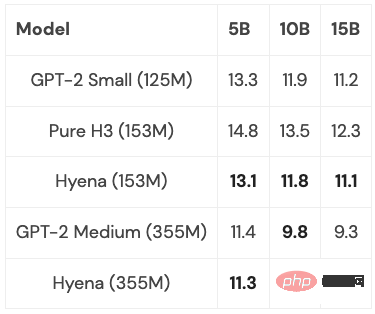
通过一些优化(更多内容见下文),在序列长度为 2K 时,Hyena 模型的速度略慢于相同大小的 Transformer,但在更长的序列长度上会更快。
接下来仍需思考的是,究竟能将这些模型推广到什么程度?是否能将它们扩展到 PILE 的全尺寸(400B 个 token)?如果结合 H3 和 Hyena 的思想精华,会发生什么,能走多远?
在所有这些模型中,一个常见的基本操作是 FFT,它是高效计算卷积的方式,只需要 O (NlogN) 的时间。然而,FFT 在现代硬件上的支持很差,因为现代硬件主流架构是专用的矩阵乘法单元和 GEMMs(例如 NVIDIA GPU 上的张量核心)。
可以通过将 FFT 重写为一系列矩阵乘法操作来缩小效率差距。研究小组的成员利用蝴蝶矩阵来探索稀疏训练,从而实现这个目标。最近,Hazy Research 研究人员利用这个连接构建了快速卷积算法,例如 FlashConv 和 FlashButterfly,通过使用蝴蝶分解将 FFT 计算转化为一系列矩阵乘法操作。
此外,通过借鉴之前的工作,还能建立更深入的联系:包括让这些矩阵被学习,这同样需要相同的时间,但会增加额外的参数。研究人员已经开始在一些小型数据集上探索这种联系,并取得了初步成效。我们可以清楚地看到这种联系可以带来什么(比如,如何使其适用于语言模型):

这一扩展值得更深入的探索:这个扩展学习的是哪类转换,它能让你做什么?当将它应用于语言建模时会发生什么?
这些方向都是令人兴奋的,接下来会是越来越长的序列和新的架构,让我们能够进一步探索这个新领域。我们需要特别关注那些能够受益于长序列模型的应用,比如高分辨率成像、新的数据形式,能够阅读整本书的语言模型等等。想象一下,把整本书给语言模型阅读,并让它总结故事情节,或者让一个代码生成模型基于你写的代码来生成新的代码。这些可能的场景非常非常多,都是让人感到非常兴奋的事情。
以上是想把半本《红楼梦》搬进ChatGPT输入框?先把这个问题解决掉的详细内容。更多信息请关注PHP中文网其他相关文章!





















