

折腾ChatGLM的几个避坑小技巧

我昨天说从数据技术嘉年华回来后就部署了一套ChatGLM,准备研究利用大语言模型训练数据库运维知识库,很多朋友不大相信,说老白你都这把年纪了,还能自己去折腾这些东西?为了打消这些朋友的疑虑,我今天把这两天折腾ChatGLM的过程分享给大家,也为有兴趣折腾一下ChatGLM的朋友讲一下避坑的一些技巧。
ChatGLM-6B是基于清华大学 KEG 实验室与智谱 AI 于2023年联合训练的语言模型 GLM 开发而成,是一个大型的语言模型,其针对用户的问题和要求提供适当的答复和支持。上面的回答是ChatGLM自己回答的,GLM-6B是一个开源的62亿参数的预训练模型,其特点是可以在比较小的硬件环境下本地运行。这一特性可以让基于大语言模型的应用可以走进千家万户。KEG实验室的目的是要让更大的GLM-130B模型(1300亿参数,与GPT-3.5相当)能够在一个8路RTX 3090的低端环境中完成训练。
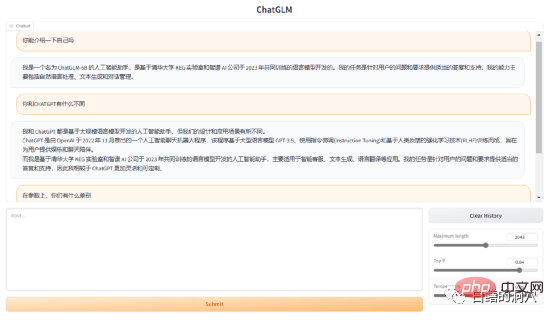
如果这个目标真的能实现,那么对想基于大语言模型做一些应用的人来说绝对是一个福音。目前的ChatGLP-6B的FP16模型大约13G多一点,INT-4量化模型不到4GB,完全可以在一块6GB显存的RTX 3060TI上运行。
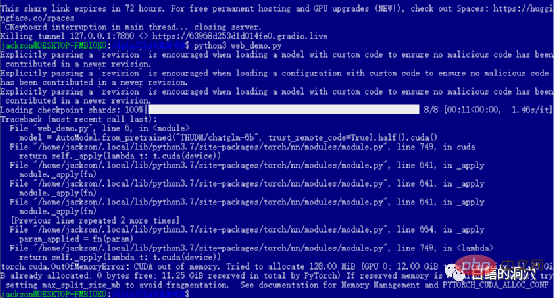
在部署前我不太了解这些情况,因此买了一块不上不下的12GB的RTX 3060,于是完成安装部署后仍然无法运行FP16的模型。早知道在自己家里做测试验证,直接买块价格更便宜的3060TI就可以了。而如果要运行无损的FP16模型,就必须上24GB显存的3090了。
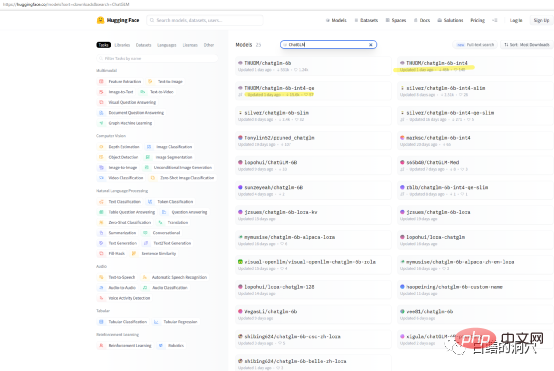
如果你仅仅是想在自己的机器上测试一下ChatGLP-6B的能力,那么你可能不需要直接去下载THUDM/ChatGLM-6B模型,在huggingface上有一些打包好的量化模型可以下载。模型下载速度很慢,你可以直接下载int4的量化模型。
我这次安装是在一台I7 8核的PC机上完成的,显卡为12G显存的RTX 3060,因为这台电脑是我的工作电脑,因此我把ChatGLM安装在了WSL子系统上。在WINDOWS WSL 子系统上安装ChatGLM比直接在LINUX环境中安装要复杂一些。其中最大的坑是显卡驱动的安装。直接在Linux上部署ChatGLM的时候,需要直接安装NVIDIA的驱动程序,通过modprobe来激活网卡驱动就可以了。而在WSL上安装则大有不同。
ChatGLM可以在github上下载,在网站上也有一些简单的文档,甚至包含一个在WINDOWS WSL上部署ChatGLM的文档。只不过如果你是这方面的小白,完全按照这个文档去部署,会遇到无数的坑。
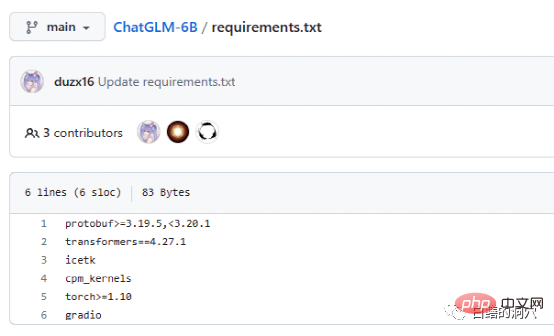
Requriements.txt文档里列出了ChatGLM使用的主要开源组件的清单与版本号,其核心是transformers,需要版本4.27.1,实际上要求没有这么严格,略低一点也没太大问题,不过安全起见还是用相同的版本为好。Icetk是做Token处理的,cpm_kernels是中文处理模型与cuda的核心调用,protobuf是结构化数据存储的。Gradio是用于利用Python快速生成AI应用的框架。Torch就不用我多做介绍了。
ChatGLM可以在没有GPU的环境中使用,利用CPU和32GB的物理内存来运行,不过运行速度很慢,仅仅能够用来做个演示验证而已。要想玩ChatGLM最好还是配备一块GPU。
在WSL上安装ChatGLM最大的坑是显卡驱动,在Git上ChatGLM的文档十分不友好,对于不太了解这个项目或者没有做过此类部署的人来说,文档实在太坑。实际上软件部署并不麻烦,而显卡驱动就十分有技巧性。
因为是在WSL subsystem上部署,因此LINUX只是一个仿真系统,并不是完整的LINUX,因此英伟达的显卡驱动只需要在WINDOWS上安装,不需要在WSL里激活。不过在WSL的LINUX虚拟环境中还是需要安装CUDA TOOLS。WINDOWS上的英伟达驱动一定要安装官网上的最新驱动,而不能使用WIN10/11自带的兼容性驱动,因此从官网上下载最新驱动并安装一定不要省略。
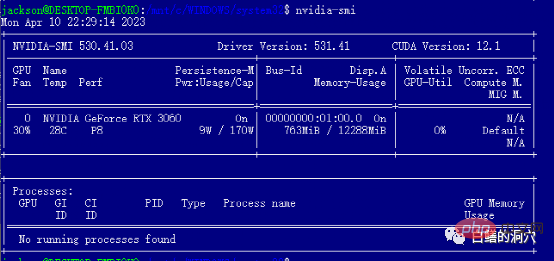
安装完WIN的驱动后就可以直接在WSL里安装cuda tools了,安装完毕后,运行nvidia-smi如果能够看到上面的界面,那么恭喜你,你已经成功地避开了第一个坑。实际上在安装cuda tools时候还会遇到几个小坑。那就是你的系统中必须安装合适版本的gcc,gcc-dev和make等编译相关的工具,如果缺少这些组件,cuda tools的安装会失败。
上面就是坑人的前期准备,实际上避开英伟达驱动这个坑,后面的安装还是很顺利的。在系统的选择上,我还是建议选择Debian兼容的Ubuntu,新版的Ubuntu的aptitude十分智能,能够帮你解决大量软件的版本兼容问题,实现部分软件的自动降版本。
下面的安装过程完全按照安装指南就可以顺利完成了,要注意的是替换/etc/apt/sources.list里面的安装源的工作最好按照指南完成,一方面安装速度会快很多,另外一方面也避免出现软件版本兼容性的问题。当然不替换也不一定会影响后面的安装过程。
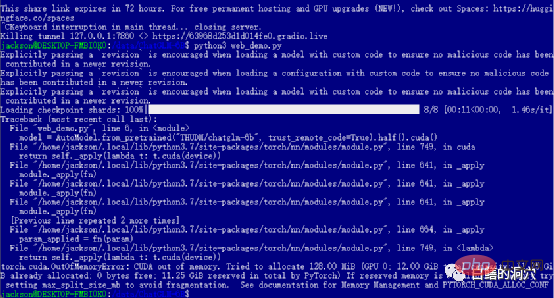
如果你顺利地通过了前面的各道关卡,那么你就进入到了最后一步,启动web_demo了。执行python3 web_demo.py可以启动一个WEB对话的例子。这时候如果你是个穷人,只有一张12GB显存的3060,那么你就一定会看到上面的报错了,哪怕你把PYTORCH_CUDA_ALLOC_CONF设置为最小的21,也无法避开这个报错。这时候你就不能偷懒了,必须简单地改写一下python脚本。
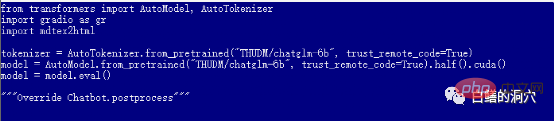
默认的web_demo.py是使用FP16的预训练模型的,13GB多的模型肯定无法装载到12GB现存里的,因此你需要对这个代码做一个小的调整。

你可以改为quantize(4)来装载INT4量化模型,或者改为quantize(8)来装载INT8量化模型。这样你的显卡内存就够用了,而且可以支持你做各种对话了。
要注意的是,web_demo.py启动后,模型的下载工作才真正开始,因此要下载13GB的模型,需要相当长的时间,你可以把这项工作放到半夜做,或者你直接用迅雷等下载工具预先从hugging face上下载模型。如果你对模型一无所知,不太会安装下载的模型,你也可以修改代码中的模型名称,THUDM/chatglm-6b-int4,直接从网上下载只有不到4GB的INT4量化模型,这样会快很多,反正你的破显卡也跑不起FP16的模型。
至此,你可以通过网页与ChatGLM对话了,不过这一切只是折腾的开始。只有你能够把你的微调模型训练出来了,那么你的ChatGLM的入坑之旅才会真正开始。玩这种东西还是需要大量的精力和金钱的,入坑要慎重。
最后我还是十分感谢清华大学KEG实验室的朋友,他们的工作让更多的人可以低成本地使用大语言模型。
以上是折腾ChatGLM的几个避坑小技巧的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
本文回顾了AI最高的艺术生成器,讨论了他们的功能,对创意项目的适用性和价值。它重点介绍了Midjourney是专业人士的最佳价值,并建议使用Dall-E 2进行高质量的可定制艺术。
 Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4当前可用并广泛使用,与诸如ChatGpt 3.5(例如ChatGpt 3.5)相比,在理解上下文和产生连贯的响应方面取得了重大改进。未来的发展可能包括更多个性化的间
 开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&更多)
Apr 02, 2025 pm 06:09 PM
最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&更多)
Apr 02, 2025 pm 06:09 PM
本文比较了诸如Chatgpt,Gemini和Claude之类的顶级AI聊天机器人,重点介绍了其独特功能,自定义选项以及自然语言处理和可靠性的性能。
 顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
文章讨论了Grammarly,Jasper,Copy.ai,Writesonic和Rytr等AI最高的写作助手,重点介绍了其独特的内容创建功能。它认为Jasper在SEO优化方面表现出色,而AI工具有助于保持音调的组成
 选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
本文评论了Google Cloud,Amazon Polly,Microsoft Azure,IBM Watson和Discript等高级AI语音生成器,重点介绍其功能,语音质量和满足不同需求的适用性。
 如何访问猎鹰3? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
如何访问猎鹰3? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
猎鹰3:革命性的开源大语模型 Falcon 3是著名的猎鹰系列LLMS系列中的最新迭代,代表了AI技术的重大进步。由技术创新研究所(TII)开发
 构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
2024年见证了从简单地使用LLM进行内容生成的转变,转变为了解其内部工作。 这种探索导致了AI代理的发现 - 自主系统处理任务和最少人工干预的决策。 Buildin
