

OCR+ChatGPT识别食品配料里的狠活!

哈喽,大家好。
之前给大家分享过一次配料表识别程序,这次我们用ChatGPT改造一下。
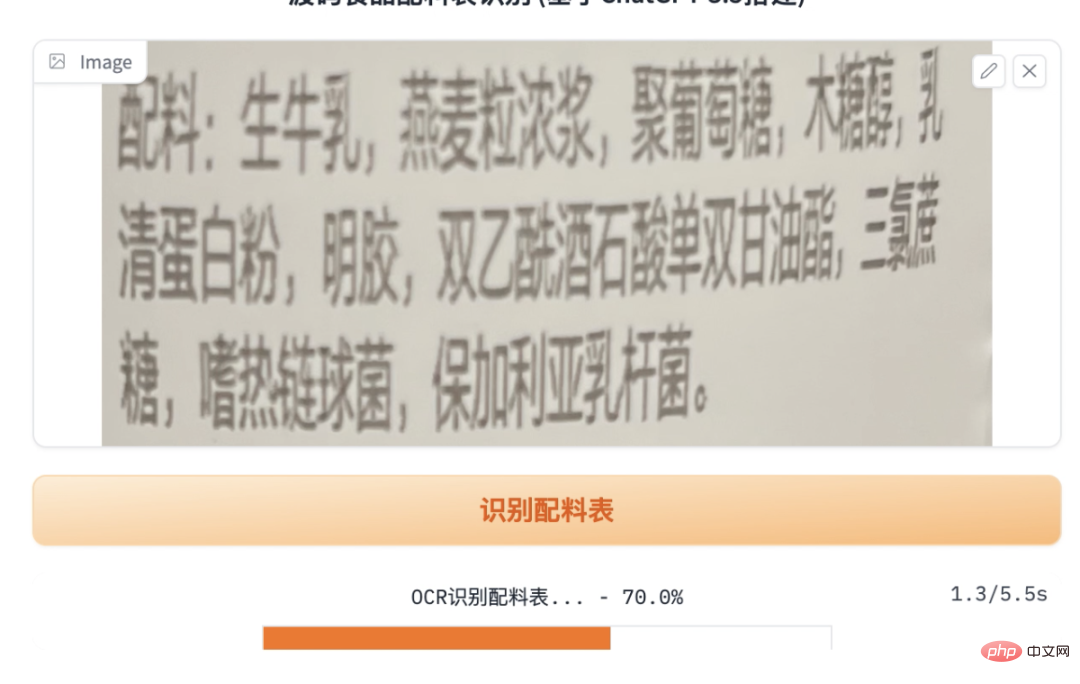
之前的大致思路是,用OCR识别配料表文字,然后开发一个爬虫,爬取每种配料的详细信息(爬百度百科)。
这次的程序不两个不同的地方,第一,配料详情调用ChatGPT获取,免爬取,结果更精准。
第二,web开发框架用gradio,gradio和streamlit类似,都是为了方便AI人员能快速构建web app的框架。
源码已经打包好,大家见文末。
简单贴下核心代码
1. ocr识别
ocr识别使用paddle
def __init__(self): self.paddle_ocr = PaddleOCR(use_angle_cls=False, lang="ch") def ocr(self, img): result = self.paddle_ocr.ocr(img, cls=True)
ocr可以直接用预训练模型,也可以自己训练一个文字识别模型。之前都有介绍过,这里不再赘述了。
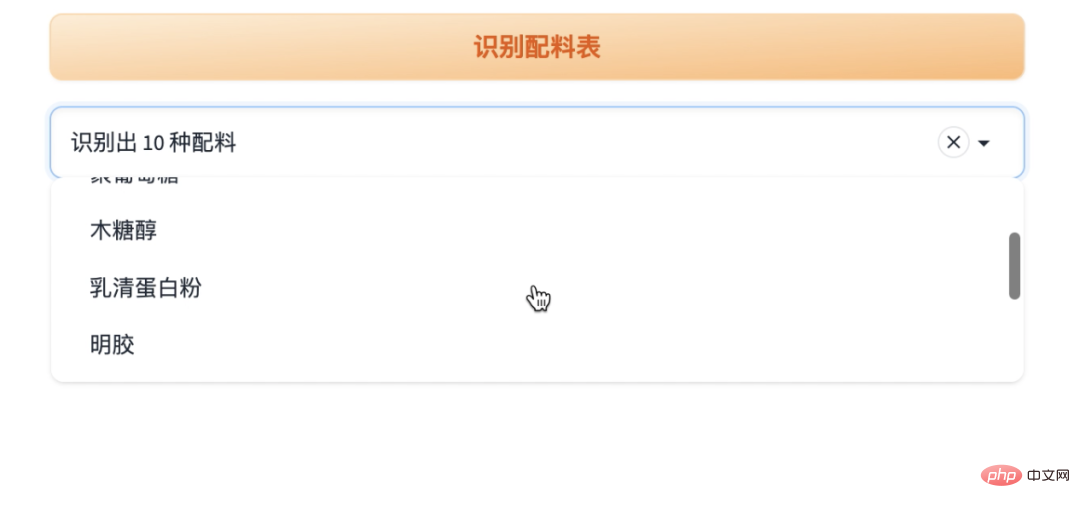
2. 获取配料详情
用下拉列表展示识别出来的配料
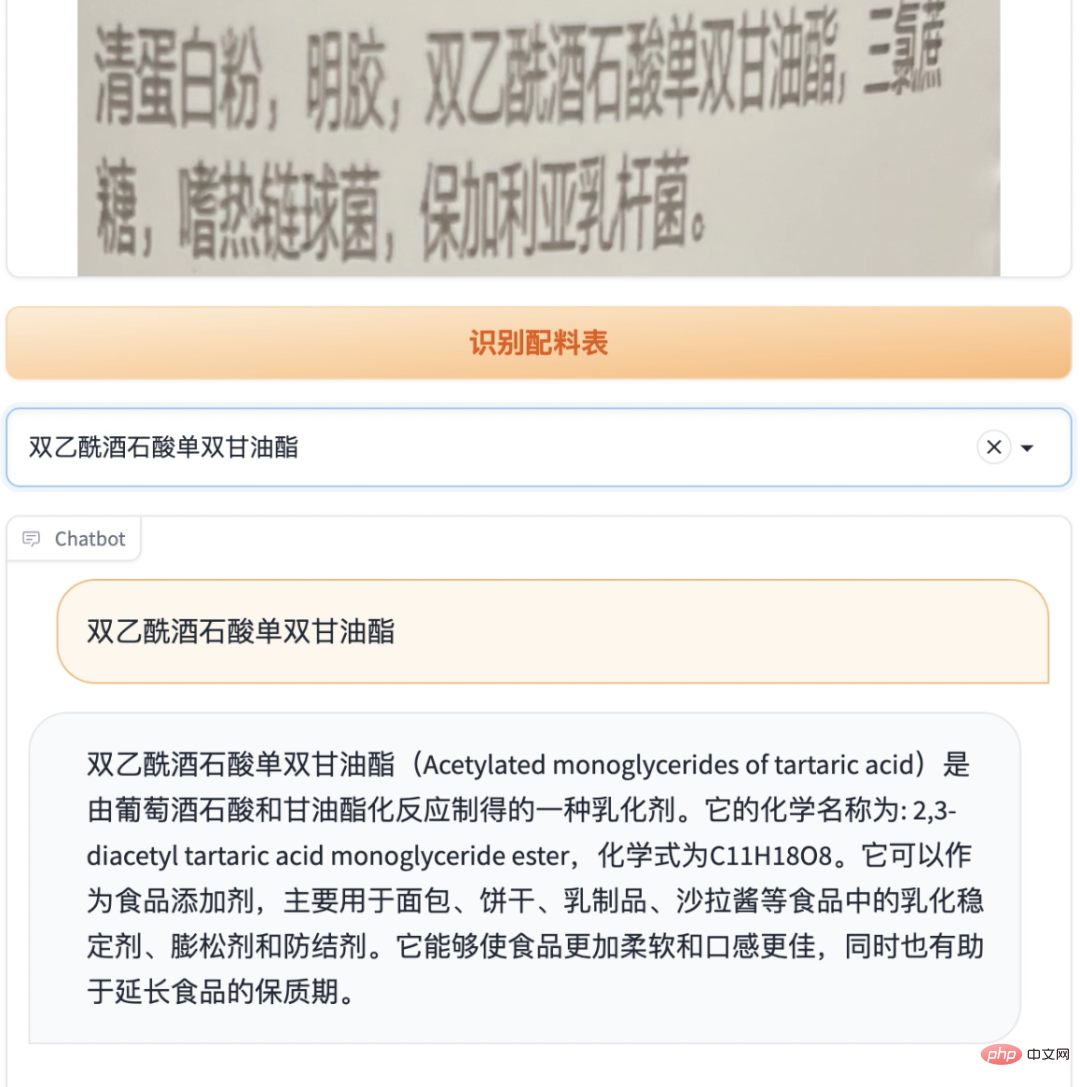
点击每种配料,调用ChatGPT的api获取配料详情
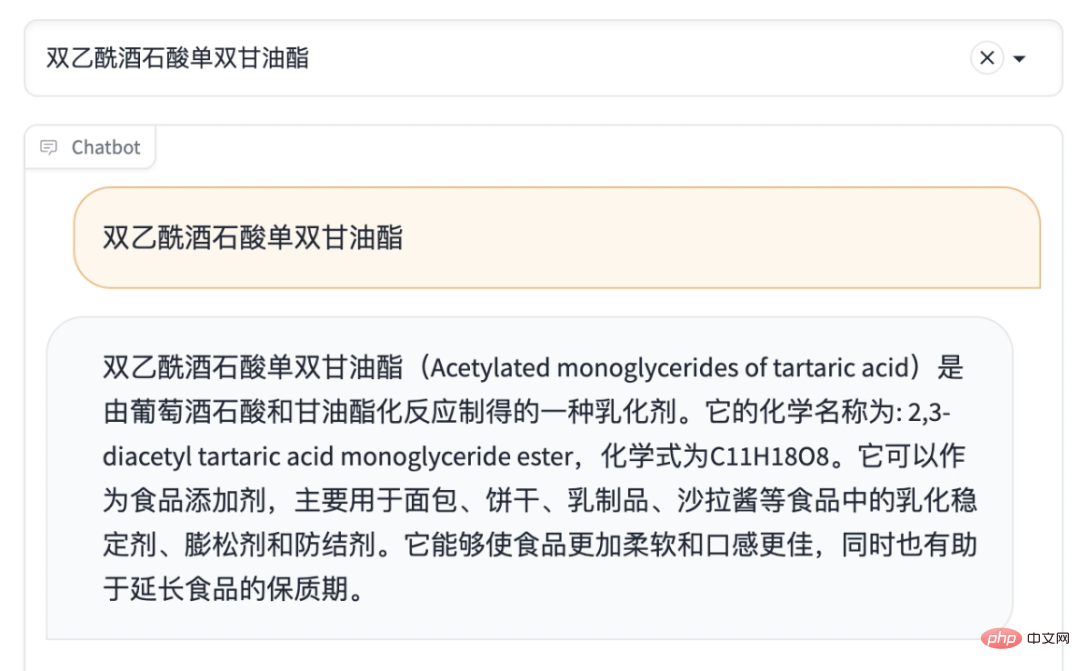
也可以多做一个对话框,支持跟ChatGPT进一步交流
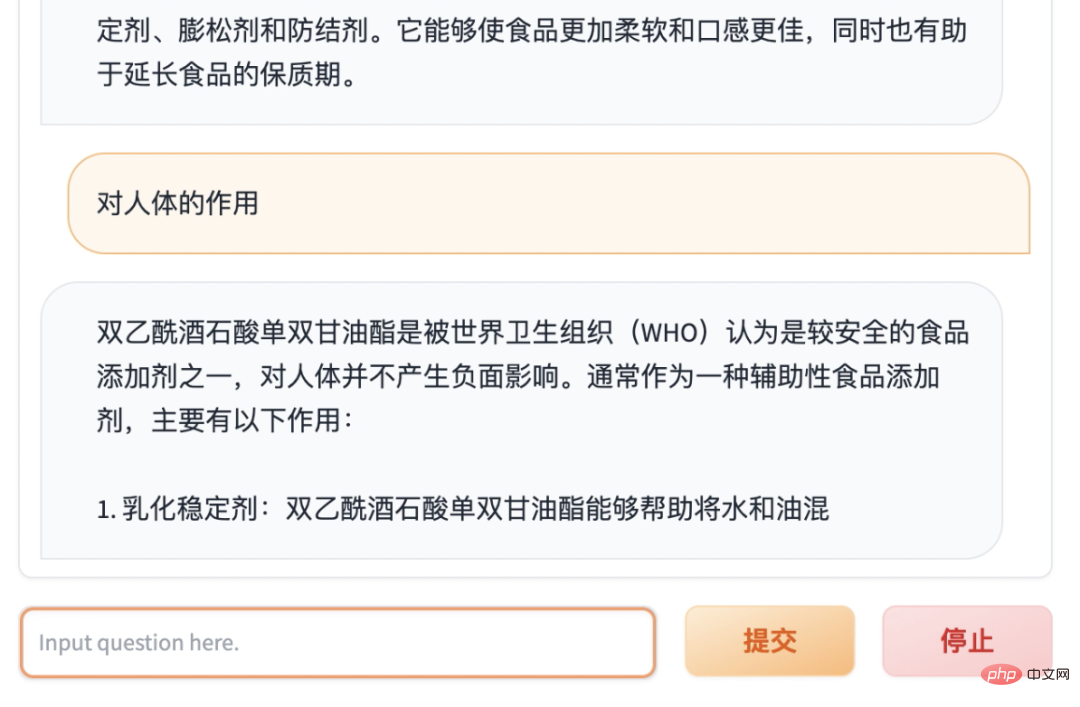
使用ChatGPT还需要魔法和api key,大家需要自行解决。
以上是OCR+ChatGPT识别食品配料里的狠活!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 于 2023 年 9 月正式推出,是比其前身大幅改进的型号。它被认为是迄今为止最好的人工智能图像生成器之一,能够创建具有复杂细节的图像。然而,在推出时,它不包括
 ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人引言:在当今信息时代,智能客服系统已经成为企业与客户之间重要的沟通工具。而为了提供更好的客户服务体验,许多企业开始转向采用聊天机器人的方式来完成客户咨询、问题解答等任务。在这篇文章中,我们将介绍如何使用OpenAI的强大模型ChatGPT和Python语言结合,来打造一个智能客服聊天机器人,以提高
 手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
安装步骤:1、在ChatGTP官网或手机商店上下载ChatGTP软件;2、打开后在设置界面中,选择语言为中文;3、在对局界面中,选择人机对局并设置中文相谱;4、开始后在聊天窗口中输入指令,即可与软件进行交互。
 如何使用ChatGPT和Java开发智能聊天机器人
Oct 28, 2023 am 08:54 AM
如何使用ChatGPT和Java开发智能聊天机器人
Oct 28, 2023 am 08:54 AM
在这篇文章中,我们将介绍如何使用ChatGPT和Java开发智能聊天机器人,并提供一些具体的代码示例。ChatGPT是由OpenAI开发的困境预测转换(GenerativePre-trainingTransformer)的最新版本,它是一种基于神经网络的人工智能技术,可以理解自然语言并生成人类类似的文本。使用ChatGPT,我们可以轻松地创建自适应的聊天
 如何使用ChatGPT PHP构建智能客服机器人
Oct 28, 2023 am 09:34 AM
如何使用ChatGPT PHP构建智能客服机器人
Oct 28, 2023 am 09:34 AM
如何使用ChatGPTPHP构建智能客服机器人引言:随着人工智能技术的发展,机器人在客服领域的应用越来越广泛。使用ChatGPTPHP构建智能客服机器人,可以帮助企业提供更高效、更个性化的客户服务。本文将介绍如何使用ChatGPTPHP构建智能客服机器人,并提供具体的代码示例。一、安装ChatGPTPHP要使用ChatGPTPHP构建智能客服机器人
 chatgpt国内可以使用吗
Mar 05, 2024 pm 03:05 PM
chatgpt国内可以使用吗
Mar 05, 2024 pm 03:05 PM
chatgpt在国内可以使用,但不能注册,港澳也不行,用户想要注册的话,可以使用国外的手机号进行注册,注意注册过程中要将网络环境切换成国外ip。
 ChatGPT和Python的完美结合:打造实时聊天机器人
Oct 28, 2023 am 08:37 AM
ChatGPT和Python的完美结合:打造实时聊天机器人
Oct 28, 2023 am 08:37 AM
ChatGPT和Python的完美结合:打造实时聊天机器人导言:随着人工智能技术的快速发展,聊天机器人在各个领域中扮演着越来越重要的角色。聊天机器人可以帮助用户提供即时且个性化的帮助,同时也可以为企业提供高效的客户服务。本文将介绍如何使用OpenAI的ChatGPT模型和Python语言相结合,打造一个实时聊天机器人,并提供具体的代码示例。一、ChatGPT
 如何利用ChatGPT和Python实现用户意图识别功能
Oct 27, 2023 am 09:04 AM
如何利用ChatGPT和Python实现用户意图识别功能
Oct 27, 2023 am 09:04 AM
如何利用ChatGPT和Python实现用户意图识别功能引言:在当今的数字化时代,人工智能技术逐渐成为各个领域中不可或缺的一部分。其中,自然语言处理(NaturalLanguageProcessing,NLP)技术的发展使得机器能够理解和处理人类语言。ChatGPT(Chat-GeneratingPretrainedTransformer)是一种基于
