
什么是k-近邻算法?

K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
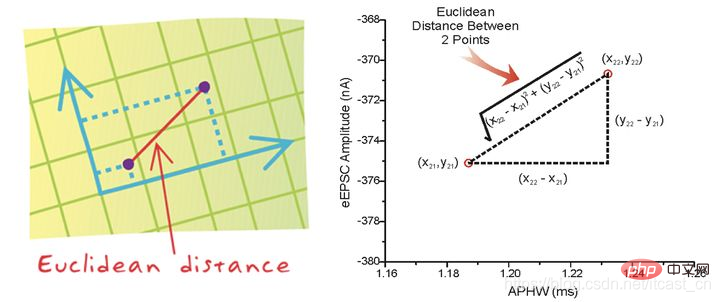
两个样本的距离可以通过如下公式计算,又叫欧式距离 ,关于距离公式会在后面进行讨论
应用场景为:房价预测、销售额度预测、贷款额度预测
什么是线性回归?
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归。

线性回归用矩阵表示举例:
那么怎么理解呢?我们来看几个例子:
期末成绩:0.7×考试成绩+0.3×平时成绩
房子价格 = 0.02×中心区域的距离 + 0.04×城市一氧化氮浓度 + (-0.12×自住房平均房价) + 0.254×城镇犯罪率
上面两个例子,我们看到特征值与目标值之间建立了一个关系,这个关系可以理解为线性模型。
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归。由于算法的简单和高效,在实际中应用非常广泛。
应用场景:广告点击率、是否为垃圾邮件、是否患病、金融诈骗,虚假账号。
这里就可以发现一个特点了,就是两个类别之间都属于判断,逻辑回归就是解决二分类问题的利器。
要想掌握逻辑回归,必须掌握两点:
逻辑回归中,其输入值是什么?
如何判断逻辑回归的输出?
输入:

激活函数:sigmoid函数

判断标准
回归的结果输入到sigmoid函数当中,输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值。

逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)。(方便损失计算)
输出结果解释(重要):假设有两个类别A,B,并且假设我们的概率值为属于A(1)这个类别的概率值。现在有一个样本的输入到逻辑回归输出结果0.55,那么这个概率值超过0.5,意味着我们训练或者预测的结果就是A(1)类别。那么反之,如果得出结果为0.3那么,训练或者预测结果就为B(0)类别。
关于逻辑回归的阈值是可以进行改变的,比如上面举例中,如果你把阈值设置为0.6,那么输出的结果0.55,就属于B类。
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
怎么理解这句话?通过一个对话例子

上面案例是女生通过定性的主观意识,把年龄放到最上面,那么如果需要对这一过程进行量化,该如何处理呢?
此时需要用到信息论中的知识:信息熵,信息增益。

集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。

用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
基于位置信息的商业推送,新闻聚类,筛选排序。
图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段。
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
以上是机器学习中入门级必学的算法有哪些?的详细内容。更多信息请关注PHP中文网其他相关文章!






















