

通过定制化算子融合提高AI端到端性能

图优化在降低 AI 模型的训练和推理使用的时间和资源方面起着重要作用。图优化的一个重要功能是模型中将可以融合的算子进行融合,通过降低内存占用和减少数据在低速内存中的搬运来提高计算效率。然而,实现一套能够提供各种算子融合的后端方案难度很大,导致在实际硬件上 AI 模型能够使用的算子融合非常有限。
Composable Kernel (CK)库旨在提供一套在 AMD GPU 上的算子融合的后端方案。CK 使用通用编程语言 HIP C ,完全开源。其设计理念包括:
- 高性能 & 高生产力:CK 的核心是一组精心设计,高度优化,可复用的基础模块。CK 库内所有的算子都是通过组合这些基础模块实现的。复用这些基础模块大大缩短开发后端算法的周期,同时还能保证高性能。
- 精通当前的 AI 问题,快速适应未来的 AI 问题:CK 旨在提供一套完整的 AI 算子后端方案,这让复杂的算子融合成为可能,因为这样让整个后端都可以用 CK 实现,而不需依赖外部算子库。CK 的可复用基础模块足以实现常见 AI 模型(机器视觉,自然语言处理,等等)所需的各种算子及其融合。当新出现的 AI 模型需要新的算子时,CK 也将会提供所需的基础模块。
- AI 系统专家的简单但强大的工具:CK 所有的算子都是用 HIP C 模版实现的。AI 系统专家可以通过实例化模版来定制这些算子的属性,比如数据类型,元操作类型,张量存储格式,等等。这通常只需要几行代码。
- 友好的 HIP C 界面:HPC 算法开发者一直在推动着 AI 计算加速的前沿。CK 的一个重要设计理念就是要让 HPC 算法开发者更容易对 AI 加速作出贡献。因此 CK 所有核心模块都是用 HIP C 实现,而不是 Intermediate Representation (IR)。HPC 算法开发者直接以他们熟悉的编写 C 代码的形式编写算法,而无需像基于 IR 的算子库那样,以通过编写针对某种特定算法的 Compiler Pass 来实现。这样做可以大大提高算法的迭代速度。
- 可移植性:今天使用 CK 作为后端的图优化将能够移植到未来 AMD 的所有的 GPU 上,并且最终也可以被移植到 AMD CPU 上【2】。
- CK 源代码:https://github.com/ROCmSoftwarePlatform/composable_kernel
核心概念
CK 引入了两个概念以提高后端开发者的生产力:
1. 开创性的引入“张量坐标变换” (Tensor Coordinate Transformation)降低 AI 算子的编写复杂度。该研究开创性地定义了一组可复用的 Tensor Coordinate Transformation 基础模块,并且用它们把复杂的 AI 算子(比如卷积,group normalization reduction,Depth2Space,等等)以数学严谨的方式重新表达成了最基础的 AI 算子(GEMM,2D reduction,tensor transfer,等等)。这项技术可以让为基础 AI 算子编写的算法直接被用到所有与之对应的复杂的 AI 算子上,而无需重写算法。
2. 基于 Tile 的编程范式:开发算子融合的后端算法可以被看成先将每一个融合前的算子(独立算子)拆解成许多 “小块” 的数据操作,然后再把这些 “小块” 操作组合成融合的算子。每一个这样的 “小块” 操作都对应一个原始的独立算子,但是被操作的数据只是原始张量的一部分(tile),因此这样的 “小块” 操作被称为 Tile Tensor Operator。CK 库包含一组针对 Tile Tensor Operator 的高度优化的实现,CK 里所有的 AI 独立算子和融合算子都是用它们实现的。目前,这些 Tile Tensor Operators 包括 Tile GEMM,Tile Reduction 和 Tile Tensor Transfer。每一个 Tile Tensor Operator 都有针对 GPU thread block,warp 和 thread 的实现。
Tensor Coordinate Transformation 和 Tile Tensor Operator 共同组成了 CK 的可复用的基础模块。
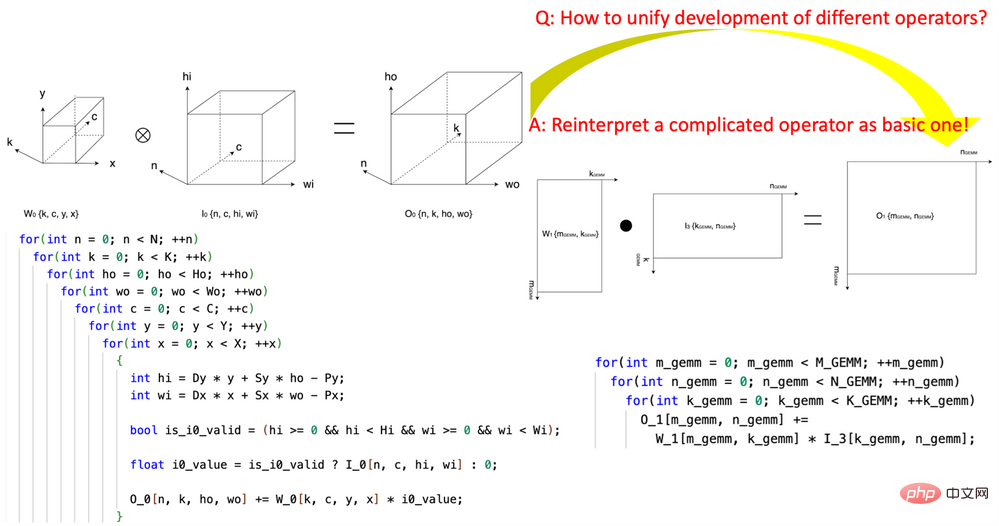
图 1,使用 CK 的 Tensor Coordinate Transformation 基础模块将 convolution 算子表达成 GEMM 算子
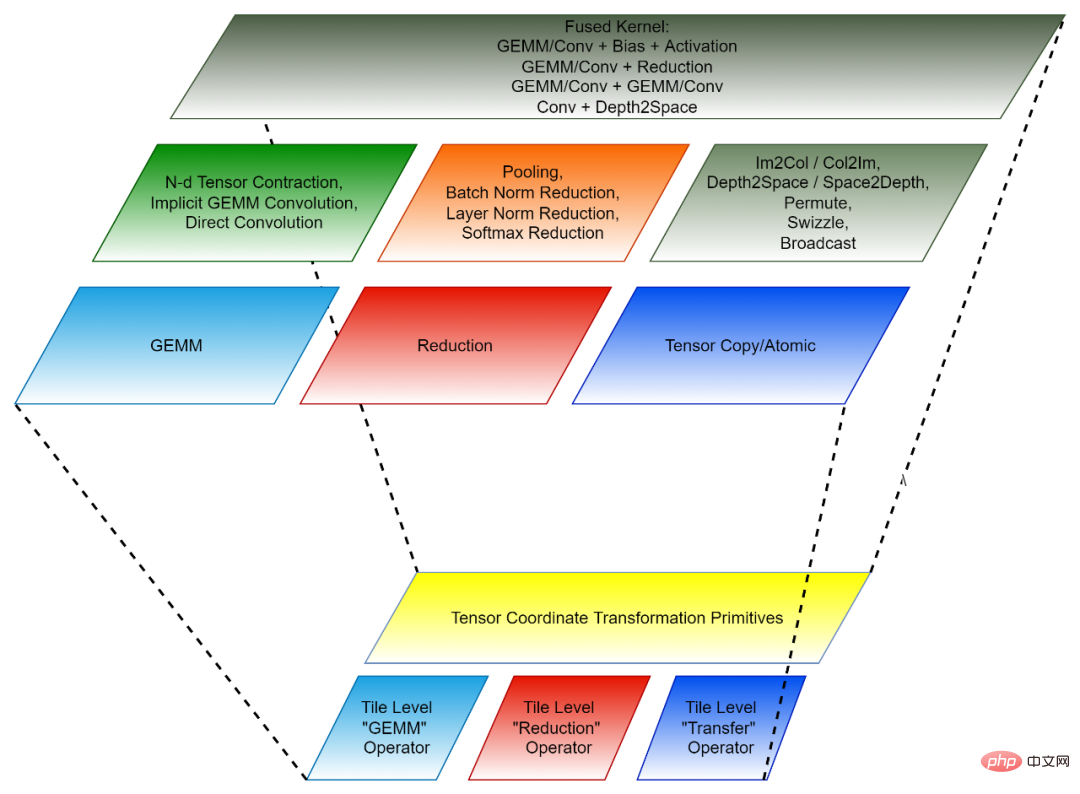
图 2,CK 的组成(下:可复用的基础模块;上:独立算子与融合算子)
代码结构
CK 库结构分为四层,从下到上分别是:Templated Tile Operator,Templated Kernel and Invoker,Instantiated Kernel and Invoker 和 Client API【3】。每一层对应不同的开发者。
- AI 系统专家:“我需要一个后端方案提供高性能的独立和融合算子让我可以直接使用”。这个例子【4】里用的 Client API 和 Instantiated Kernel and Invoker 提供了预先实例化并编译好的对象,以满足这类开发者的需求。
- AI 系统专家:“我为一个开源的 AI 框架做最先进的图优化工作。我需要一个能够为图优化所需的所有融合算子提供高性能 kernel 的后端方案。同时我也需要定制这些 kernel,所以像 “要么接受,要么弃用” 的黑盒解决方案不能满足我的需求”。Templated Kernel and Invoker 层能满足这类开发者。比如这个例子【5】中开发者可以自己使用 Templated Kernel and Invoker 层实例化出所需的 FP16 的 GEMM Add Add FastGeLU 的 kernel。
- HPC 算法专家:“我的团队为公司内部不断迭代的 AI 模型开发高性能后端算法。我们团队中有 HPC 算法专家,但我们仍然希望可以通过复用和改进硬件供应商提供的高度优化的源代码来提高我们的生产力,并且让我们的代码可以被移植到未来的硬件构架上。我们希望可以不用通过与硬件提供商分享我们的代码来做到这点”。Templated Tile Operator 层可以帮助到这一类开发者。比如这个代码【6】中开发者使用 Templated Tile Operator 来实现 GEMM 的优化管线。
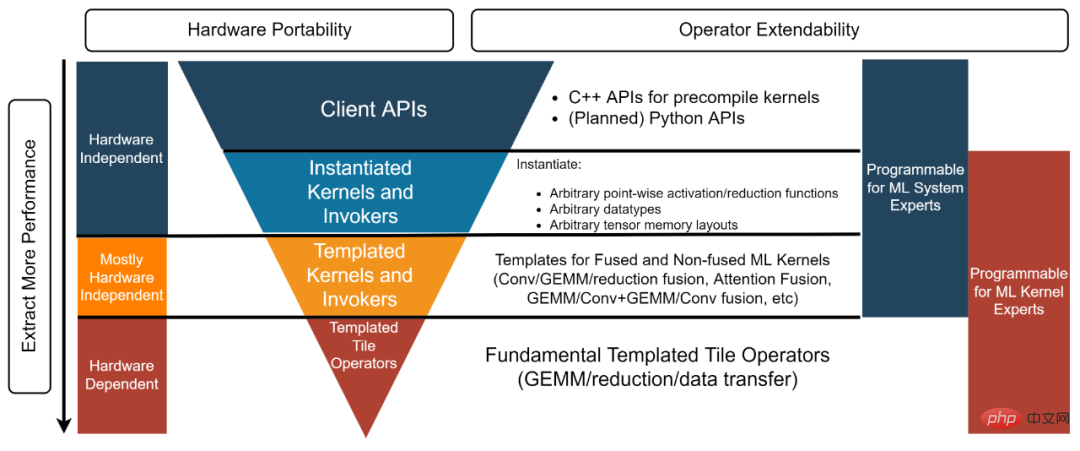
图 3,CK 库四层结构
基于 AITemplate CK 的端到端模型推理
Meta 的 AITemplate 【7】(AIT)是一个统一 AMD 和 Nvidia GPU 的 AI 推理系统。AITemplate 使用 CK 作为其 AMD GPU 上的后端,它使用的是 CK 的 Templated Kernel and Invoker 层。
AITemplate CK 在 AMD Instinct™ MI250 上取得了多个重要 AI 模型最先进的推理性能。CK 里大多数先进的融合算子的定义,都是在 AITemplate 团队的远见下推动的。许多融合算子的算法也是由 CK 和 AITemplate 团队共同设计。
本文比较了几个端到端模型在 AMD Instinct MI250 和同级别产品【8】的性能表现。本文中所有 AMD Instinct MI250 的 AI 模型的性能数据都是用 AITemplate【9】 CK【10】取得的。
实验
ResNet-50
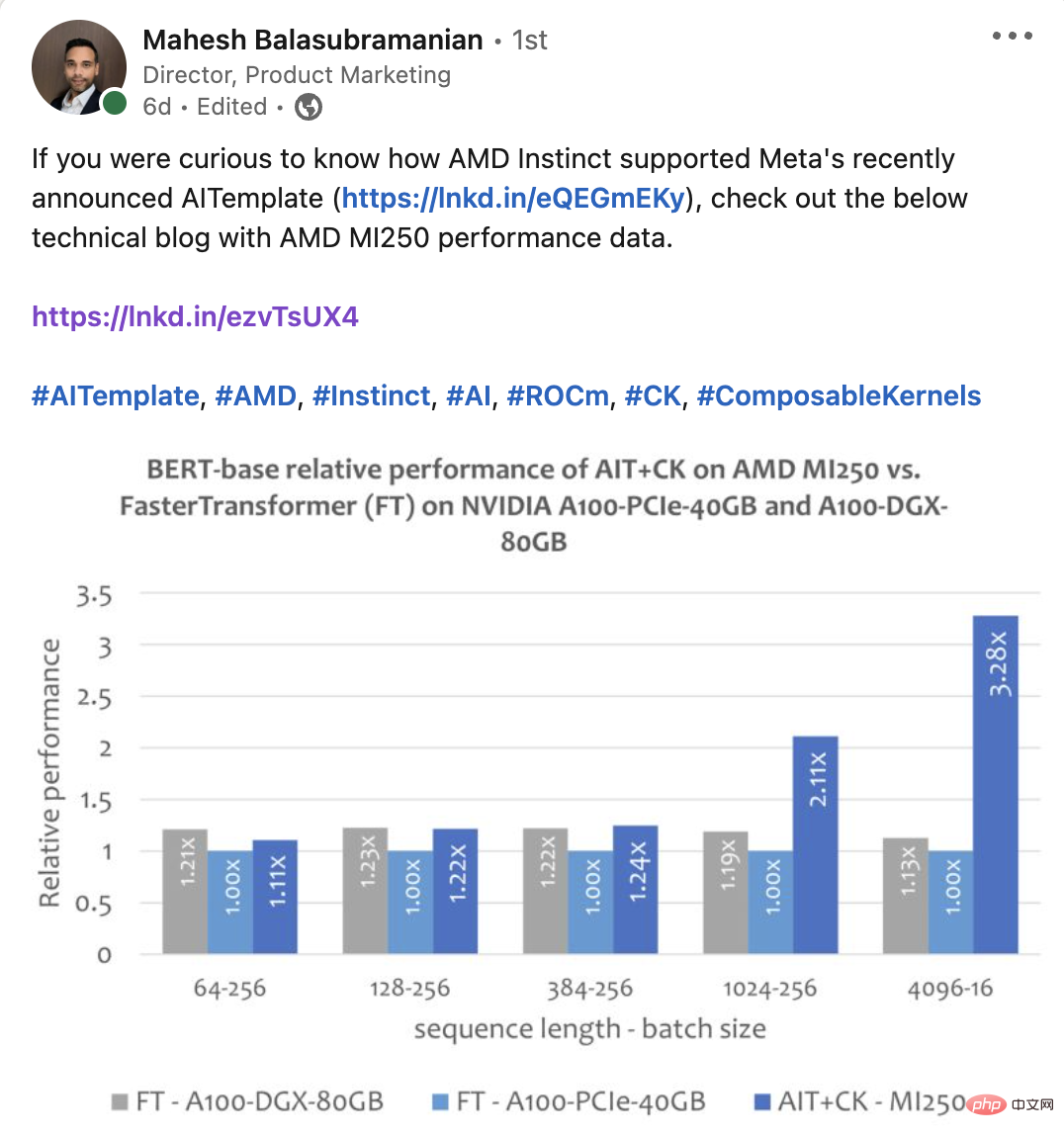
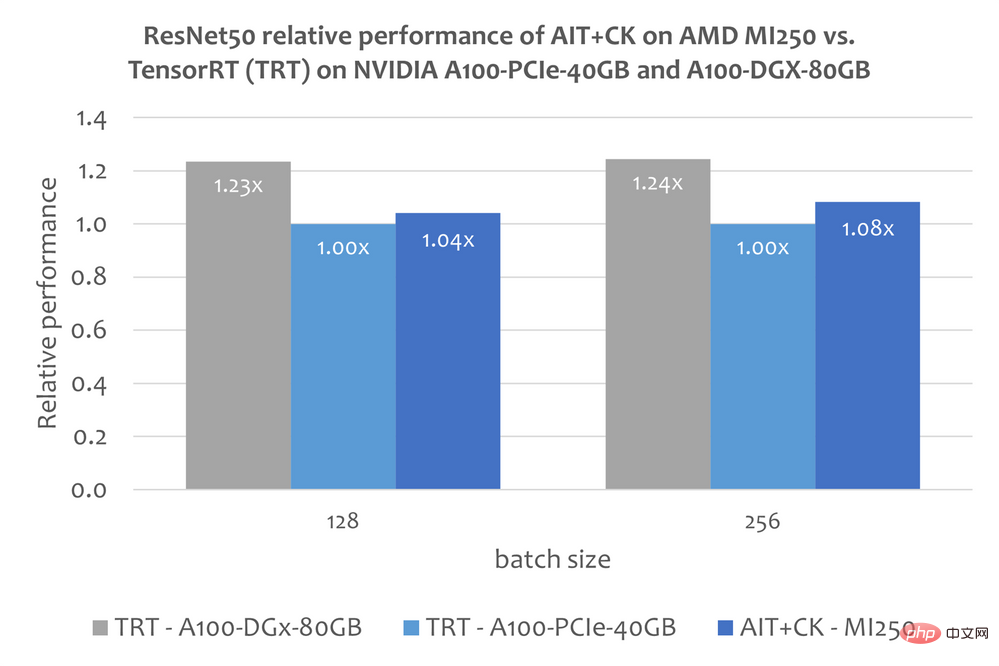
下图显示了 AMD Instinct MI250 上的 AIT CK 与 A100-PCIe-40GB 和 A100-DGX-80GB 上的 TensorRT v8.5.0.12 【11】(TRT)的性能比较。结果显示 AMD Instinct MI250 上的 AIT CK 取得了相比于 A100-PCIe-40GB 上的 TRT 1.08 倍的加速。
BERT
一个基于 CK 实现的 Batched GEMM Softmax GEMM 融合算子模版,可以完全消除掉中间结果在 GPU 计算单元(Compute Unit)与 HBM 之间的搬运。通过使用这个融合算子模版,attention layer 许多原本是带宽瓶颈(bandwidth bound)的问题变成了计算瓶颈(compute bound)的问题,这样可以更好发挥 GPU 的计算能力。这个 CK 的实现深受 FlashAttention 【12】的启发,并比原始的 FlashAttention 的实现减少了更多的数据搬运。
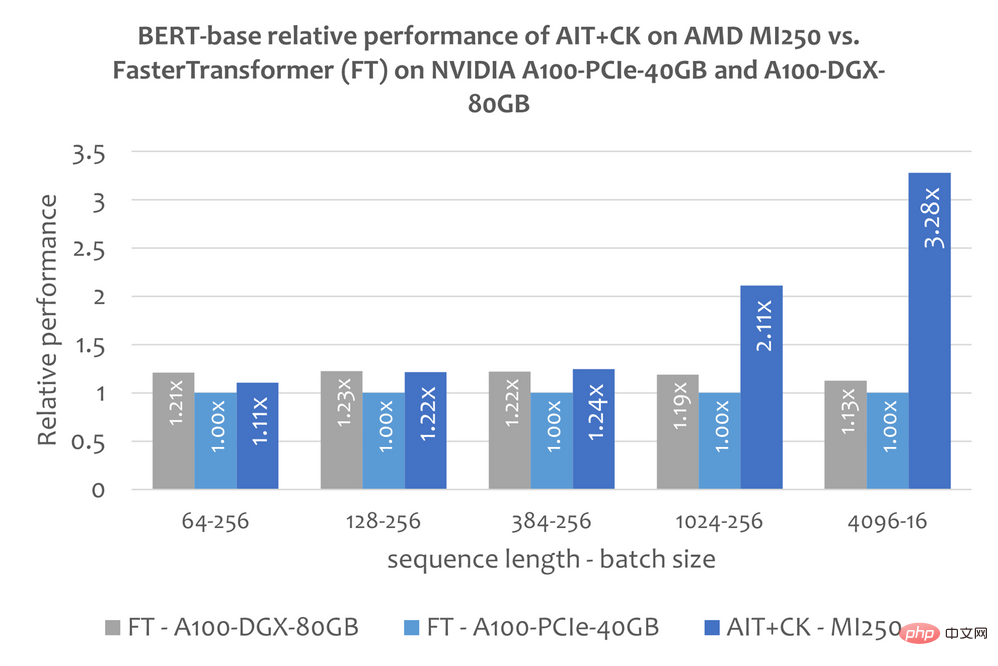
下图显示了 AMD Instinct MI250 上的 AIT CK 与 A100-PCIe-40GB 和 A100-DGX-80GB 上的 FasterTransformer v5.1.1 bug fix 【13】(FT)的 Bert Base 模型(uncased)的性能比较。当 Sequence 是 4096 时,FT 在 A100-PCIe-40GB 和 A100-DGX-80GB 上会在 Batch 32 时 GPU 内存溢出。因此,在 Sequence 是 4096 时,本文只显示 Batch 16 的结果。结果显示 AMD Instinct MI250 上的 AIT CK 取得了相比于 A100-PCIe-40GB 上的 FT 3.28 倍,以及相比于 A100-DGX-80GB 上的 FT 2.91 倍的加速。
Vision Transformer (VIT)
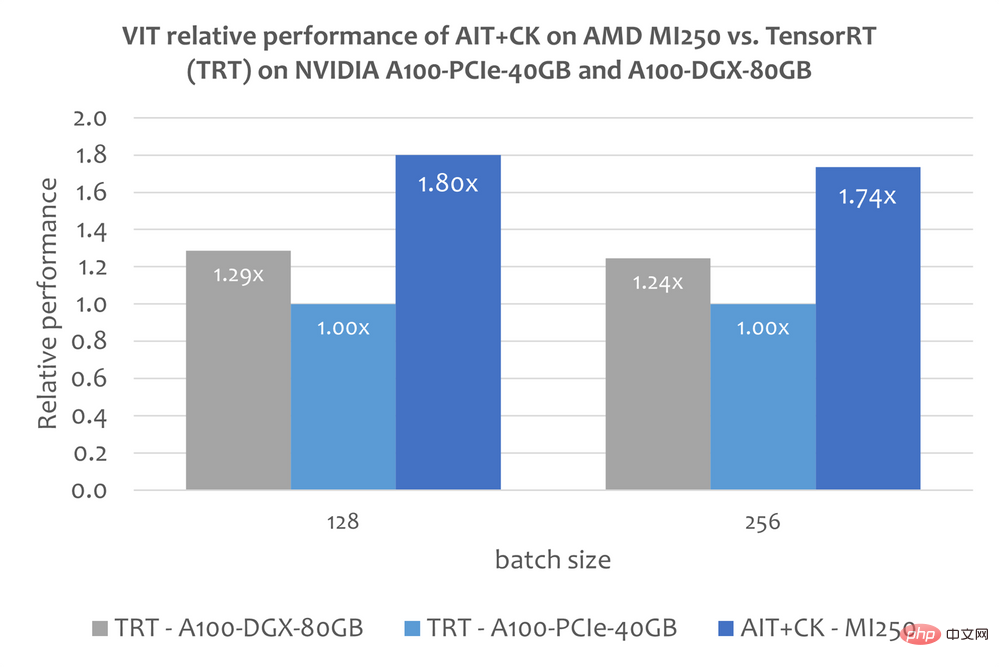
下图显示了 AMD Instinct MI250 上的 AIT CK 与 A100-PCIe-40GB 和 A100-DGX-80GB 上的 TensorRT v8.5.0.12(TRT)的 Vision Transformer Base (224x224 图片)的性能比较。结果显示 AMD Instinct MI250 上的 AIT CK 取得了相比于 A100-PCIe-40GB 上的 TRT 1.8 倍,以及相比于 A100-DGX-80GB 上的 TRT 1.4 倍的加速。
Stable Diffusion
端到端的 Stable Diffusion
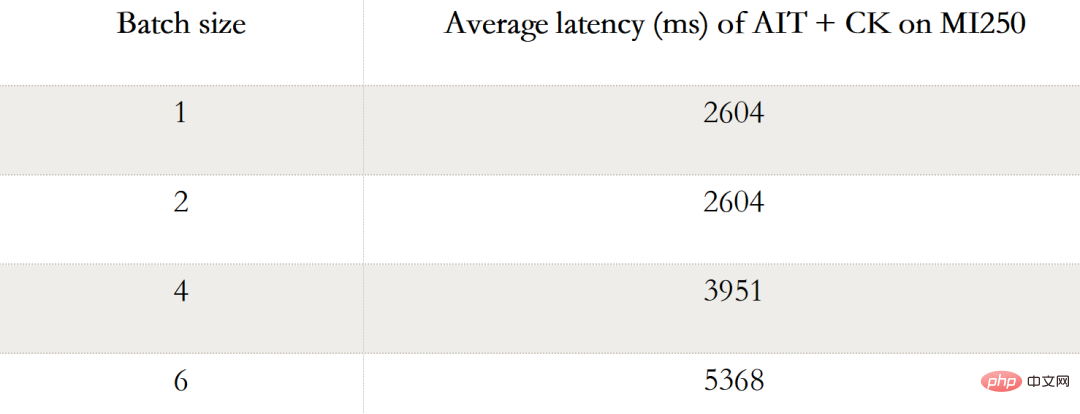
下表显示 AIT CK 在 AMD Instinct MI250 上 Stable Diffusion 端到端(Batch 1,2,4, 6)的性能数据。当 Batch 是 1 时,在 MI250 上只有一个 GCD 被使用,而在 Batch 2,4,6 时,两个 GCD 都被使用了。
Stable Diffusion 中的 UNet
不过本文还没有关于使用 TensorRT 运行 Stable Diffusion 端到端模型的公开的信息。但这篇文章“Make stable diffusion 25% faster using TensorRT” 【14】说明了怎么使用 TensorRT 加速 Stable Diffusion 中的 UNet 模型。UNet 是 Stable Diffusion 中最重要最花时间的部分,因此 UNet 的性能大致反应了 Stable Diffusion 的性能。
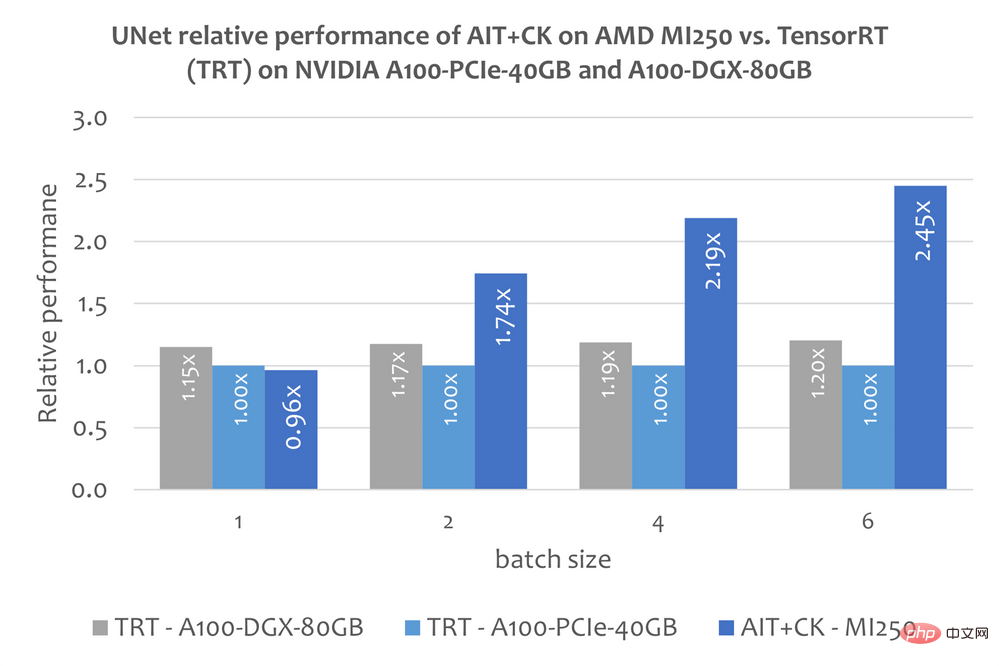
下图显示了 AMD Instinct MI250 上的 AIT CK 与 A100-PCIe-40GB 和 A100-DGX-80GB 上的 TensorRT v8.5.0.12(TRT)的 UNet 的性能比较。结果显示 AMD Instinct MI250 上的 AIT CK 取得了相比于 A100-PCIe-40GB 上的 TRT 2.45 倍,以及相比于 A100-DGX-80GB 上的 TRT 2.03 倍的加速。
更多信息
ROCm webpage: AMD ROCm™ Open Software Platform | AMD
ROCm Information Portal: AMD Documentation - Portal
AMD Instinct Accelerators: AMD Instinct™ Accelerators | AMD
AMD Infinity Hub: AMD Infinity Hub | AMD
Endnotes:
1.Chao Liu is PMTS Software Development Engineer at AMD. Jing Zhang is SMTS Software Development Engineer at AMD. Their postings are their own opinions and may not represent AMD’s positions, strategies, or opinions. Links to third party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites and no endorsement is implied. GD-5
2.CPU CK 处于早期开发阶段。
3.C目前 API,Python API 正在规划中。
4.GEMM 的 CK “客户端 API”示例 添加 添加 FastGeLU 融合运算符。 https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
5.CK“模板化 Ker 示例”内尔GEMM 的“Invoker”和“Invoker”添加 添加 FastGeLU 熔断运算符。 https://github.com/rocmsoftwareplatform/composable_kernel/blob/685860C2A9483C9E909D2F8BFBFBFB95056672491..........。 Tile Operator”原语用于编写 GEMM 管道。 https://github.com/rocmsoftwareplatform/composable_kernel/blob/685860C2A9483C9E909D2F8BFBFB95056672491.............upostecome https://github.com/facebookincubator/AITemplate
8.MI200-71:由 AMD MLSE 10.23.22 使用进行的测试AITemplate https://github.com/ROCmSoftwarePlatform/AITemplate,提交 f940d9b) 可组合内核 https://github.com/ROCmSoftwarePlatform/composable_kernel,提交 40942b9),ROCm™5.3 在 2 个 AMD EPYC 7713 64 核处理器服务器(4 个)上运行采用 AMD Infinity Fabric™ 技术的 AMD Instinct MI250 OAM (128 GB HBM2e) 560W GPU 与 TensorRT v8.5.0.12 和 FasterTransformer(v5.1.1 错误修复)以及 CUDA® 11.8 在 2 个 AMD EPYC 7742 64 核处理器服务器上运行4x Nvidia A100-PCIe-40GB (250W) GPU 和 TensorRT v8.5.0.12 和 FasterTransformer(v5.1.1 错误修复),带有 CUDA® 11.8,在 2xAMD EPYC 7742 64 核处理器服务器上运行,具有 8x NVIDIA A100 SXM 80GB (400W)图形处理器。服务器制造商可能会改变配置,从而产生不同的结果。性能可能会因使用最新驱动程序和优化等因素而有所不同。
9.https://github.com/ROCmSoftwarePlatform/AITemplate/tree/f940d9b7ac8b976fba127e2c269dc5b368f30e4e
10.https://github.com/ROCmSoftwarePlatform/composable_kernel/tree/40942b909801dd721769834fc61ad201b5795...
11.TensorRT GitHub 存储库。 https://github.com/NVIDIA/TensorRT
12.FlashAttention:具有 IO 感知的快速、内存高效的精确注意力。 https://arxiv.org/abs/2205.14135
13.FasterTransformer GitHub 存储库。 https://github.com/NVIDIA/FasterTransformer
14.使用 TensorRT 使稳定扩散速度提高 25%。 https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/
15 .在 AMD 期间
以上是通过定制化算子融合提高AI端到端性能的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 十个推荐开源免费文本标注工具
Mar 26, 2024 pm 08:20 PM
十个推荐开源免费文本标注工具
Mar 26, 2024 pm 08:20 PM
文本标注工作是将标签或标记与文本中特定内容相对应的工作。其主要目的是为文本提供额外的信息,以便进行更深入的分析和处理,尤其是在人工智能领域。文本标注对于人工智能应用中的监督机器学习任务至关重要。用于训练AI模型,有助更准确地理解自然语言文本信息,提高文本分类、情感分析和语言翻译等任务的性能。通过文本标注,我们可以教AI模型识别文本中的实体、理解上下文,并在出现新的类似数据时做出准确的预测。本文主要推荐一些较好的开源文本标注工具。1.LabelStudiohttps://github.com/Hu
 15个值得推荐的开源免费图像标注工具
Mar 28, 2024 pm 01:21 PM
15个值得推荐的开源免费图像标注工具
Mar 28, 2024 pm 01:21 PM
图像标注是将标签或描述性信息与图像相关联的过程,以赋予图像内容更深层次的含义和解释。这一过程对于机器学习至关重要,它有助于训练视觉模型以更准确地识别图像中的各个元素。通过为图像添加标注,使得计算机能够理解图像背后的语义和上下文,从而提高对图像内容的理解和分析能力。图像标注的应用范围广泛,涵盖了许多领域,如计算机视觉、自然语言处理和图视觉模型具有广泛的应用领域,例如,辅助车辆识别道路上的障碍物,帮助疾病的检测和诊断通过医学图像识别。本文主要推荐一些较好的开源免费的图像标注工具。1.Makesens
 win10gpu共享内存关闭方法
Jan 12, 2024 am 09:45 AM
win10gpu共享内存关闭方法
Jan 12, 2024 am 09:45 AM
对电脑有了解的小伙伴肯定都知道gpu有着共享内存,而许多小伙伴都担心共享内存会导致内存数变小影响电脑而想着关闭它,下面就给大家带来了关闭它的方法,一起看看吧。win10gpu共享内存关闭:注:GPU的共享内存是无法关闭的,但是可以将它的数值设置为最小值。1、开机时按DEL进入BIOS,部分主板需要按F2/F9/F12进入,在BIOS界面的最上方有很多Tab,包含“Main、Advanced”等等设定,找到“Chipset”选项。在下面的界面中找到SouthBridge设定选项,点击Enter进入
 是否需要启用GPU硬件加速?
Feb 26, 2024 pm 08:45 PM
是否需要启用GPU硬件加速?
Feb 26, 2024 pm 08:45 PM
硬件加速GPU有必要开吗?随着科技的不断发展与进步,GPU(GraphicsProcessingUnit)作为计算机图形处理的核心组件,扮演着至关重要的角色。然而,一些用户或许对于是否需要开启硬件加速功能持有疑问。本文将探讨硬件加速GPU的必要性,以及开启硬件加速对计算机性能和使用体验的影响。首先,我们需要了解硬件加速GPU的工作原理。GPU是一种专门用
 消息称 AMD 将推新款 RX 7700M / 7800M 笔记本 GPU
Jan 06, 2024 pm 11:30 PM
消息称 AMD 将推新款 RX 7700M / 7800M 笔记本 GPU
Jan 06, 2024 pm 11:30 PM
本站1月2日消息,据TechPowerUp消息,AMD即将推出基于Navi32GPU的笔记本显卡,具体的型号可能是RX7700M和RX7800M。目前,AMD已经推出了多款RX7000系列的笔记本GPU,包括高端的RX7900M(72CU)以及主流的RX7600M/7600MXT(28/32CU)系列和RX7600S/7700S(28/32CU)系列。Navi32GPU拥有60CU,AMD可能会将其做成RX7700M和RX7800M两款,也有可能会做一款低功耗的RX7900S型号。预计AMD将在
 Beelink EX显卡扩展坞承诺GPU性能零损失
Aug 11, 2024 pm 09:55 PM
Beelink EX显卡扩展坞承诺GPU性能零损失
Aug 11, 2024 pm 09:55 PM
最近推出的 Beelink GTi 14 的突出特点之一是迷你 PC 下方有一个隐藏的 PCIe x8 插槽。该公司在发布时表示,这将使外部显卡更容易连接到系统。 Beelink有n
 推荐:优秀JS开源人脸检测识别项目
Apr 03, 2024 am 11:55 AM
推荐:优秀JS开源人脸检测识别项目
Apr 03, 2024 am 11:55 AM
人脸检测识别技术已经是一个比较成熟且应用广泛的技术。而目前最为广泛的互联网应用语言非JS莫属,在Web前端实现人脸检测识别相比后端的人脸识别有优势也有弱势。优势包括减少网络交互、实时识别,大大缩短了用户等待时间,提高了用户体验;弱势是:受到模型大小限制,其中准确率也有限。如何在web端使用js实现人脸检测呢?为了实现Web端人脸识别,需要熟悉相关的编程语言和技术,如JavaScript、HTML、CSS、WebRTC等。同时还需要掌握相关的计算机视觉和人工智能技术。值得注意的是,由于Web端的计
 AMD FSR 3.1 推出:帧生成功能也适用于 Nvidia GeForce RTX 和 Intel Arc GPU
Jun 29, 2024 am 06:57 AM
AMD FSR 3.1 推出:帧生成功能也适用于 Nvidia GeForce RTX 和 Intel Arc GPU
Jun 29, 2024 am 06:57 AM
AMD 兑现了 24 年 3 月的最初承诺,将于今年第二季度推出 FSR 3.1。 3.1 版本的真正与众不同之处在于帧生成方面与升级方面的解耦。这使得 Nvidia 和 Intel GPU 所有者可以应用 FSR 3。
