

如何运用强化学习来提升快手用户留存?

短视频推荐系统的核心目标是通过提升用户留存,牵引 DAU 增长。因此留存是各APP的核心业务优化指标之一。然而留存是用户和系统多次交互后的长期反馈,很难分解到单个 item 或者单个 list,因此传统的 point-wise 和 list-wise 模型难以直接优化留存。
强化学习(RL)方法通过和环境交互的方式优化长期奖励,适合直接优化用户留存。该工作将留存优化问题建模成一个无穷视野请求粒度的马尔科夫决策过程(MDP),用户每次请求推荐系统决策一个动作(action),用于聚合多个不同的短期反馈预估(观看时长、点赞、关注、评论、转发等)的排序模型打分。该工作目标是学习策略(policy),最小化用户多个会话的累计时间间隔,提升 App 打开频次进而提升用户留存。
然而由于留存信号的特性,现有 RL 算法直接应用存在以下挑战:1)不确定性:留存信号不只由推荐算法决定,还受到许多外部因素干扰;2)偏差:留存信号在不同时间段、不同活跃度用户群体存在偏差;3)不稳定性:与游戏环境立即返回奖励不同,留存信号通常在数小时至几天返回,这会导致 RL 算法在线训练的不稳定问题。
该工作提出 Reinforcement Learning for User Retention algorithm(RLUR)算法解决以上挑战并直接优化留存。通过离线和在线验证,RLUR 算法相比 State of Art 基线能够显著地提升次留指标。RLUR 算法已经在快手 App 全量,并且能够持续地拿到显著的次留和 DAU 收益,是业内首次通过 RL 技术在真实生产环境提升用户留存。该工作已被 WWW 2023 Industry Track 接收。

作者:蔡庆芃,刘殊畅,王学良,左天佑,谢文涛,杨斌,郑东,江鹏
论文地址:https://arxiv.org/pdf/2302.01724.pdf
问题建模
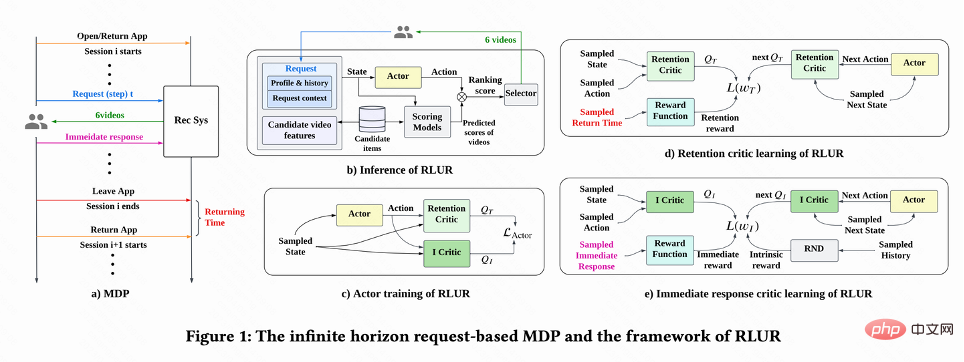
如图 1(a)所示,该工作把留存优化问题建模成一个无穷视野请求粒度马尔科夫决策过程(infinite horizon request-based Markov Decision Process),其中推荐系统是 agent,用户是环境。用户每次打开 App,开启一个新的 session i。如图 1(b),用户每次请求 推荐系统根据用户状态
推荐系统根据用户状态 决策一个参数向量
决策一个参数向量 ,同时 n 个预估不同短期指标(观看时长、点赞、关注等)的排序模型对每个候选视频 j 进行打分
,同时 n 个预估不同短期指标(观看时长、点赞、关注等)的排序模型对每个候选视频 j 进行打分 。然后排序函数输入 action 以及每个视频的打分向量,得到每个视频的最终打分,并选出得分最高的 6 个视频展示给用户,用户返回 immediate feedback
。然后排序函数输入 action 以及每个视频的打分向量,得到每个视频的最终打分,并选出得分最高的 6 个视频展示给用户,用户返回 immediate feedback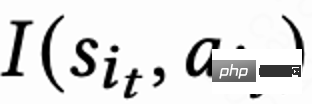 。 当用户离开 App 时本 session 结束,用户下一次打开 App session i+1 开启,上一个 session 结尾和下一个 session 开始的时间间隔被称为回访时间(Returning time),
。 当用户离开 App 时本 session 结束,用户下一次打开 App session i+1 开启,上一个 session 结尾和下一个 session 开始的时间间隔被称为回访时间(Returning time), 。 该研究的目标是训练策略最小化多个 session 的回访时间之和。
。 该研究的目标是训练策略最小化多个 session 的回访时间之和。
RLUR 算法
该工作首先讨论怎么预估累计回访时间,然后提出方法解决留存信号的几个关键挑战。这些方法汇总成 Reinforcement Learning for User Retention algorithm,简写为 RLUR。
回访时间预估
如图 1(d)所示,由于动作是连续的,该工作采取 DDPG 算法的 temporal difference(TD)学习方式预估回访时间。
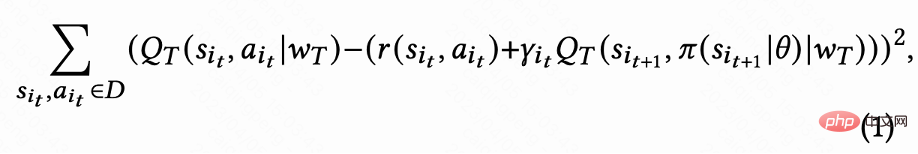
由于每个 session 最后一次请求才有回访时间 reward,中间 reward 为 0,作者设置折扣因子 在每个 session 最后一次请求取值为
在每个 session 最后一次请求取值为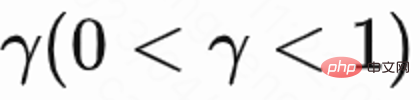 ,其他请求为 1。这样的设定能够避免回访时间指数衰减。并且从理论上可以证明当 loss(1)为 0 时,Q 实际上预估多个 session 的累计回访时间,
,其他请求为 1。这样的设定能够避免回访时间指数衰减。并且从理论上可以证明当 loss(1)为 0 时,Q 实际上预估多个 session 的累计回访时间,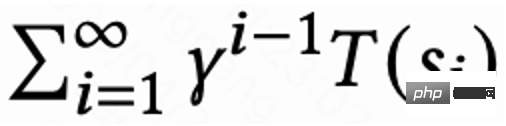 。
。
解决延迟奖励问题
由于回访时间只发生在每个 session 结束,这会带来学习效率低的问题。因而作者运用启发式奖励来增强策略学习。由于短期反馈和留存是正相关关系,因而作者把短期反馈作为第一种启发式奖励。并且作者采用 Random Network Distillation(RND)网络来计算每个样本的内在奖励作为第二种启发式奖励。具体而言 RND 网络采用 2 个相同的网络结构,一个网络随机初始化 fixed,另外一个网络拟合这个固定网络,拟合 loss 作为内在奖励。如图 1(e)所示,为了减少启发式奖励对留存奖励的干扰,该工作学习一个单独的 Critic 网络,用来估计短期反馈和内在奖励之和。即 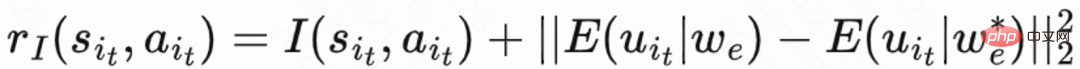 。
。
解决不确定性问题
由于回访时间受到很多推荐之外的因素影响,不确定度高,这会影响学习效果。该工作提出一个正则化方法来减少方差:首先预估一个分类模型 来预估回访时间概率,即预估回访时间是否短于
来预估回访时间概率,即预估回访时间是否短于 ;然后用马尔可夫不等式得到回访时间下界,
;然后用马尔可夫不等式得到回访时间下界,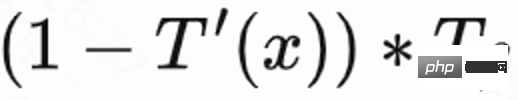 ; 最后用真实回访时间 / 预估回访时间下界作为正则化的回访 reward。
; 最后用真实回访时间 / 预估回访时间下界作为正则化的回访 reward。
解决偏差问题
由于不同活跃度群体的行为习惯差异大,高活用户留存率高并且训练样本数量也显著多于低活用户,这会导致模型学习被高活用户主导。为解决这个问题,该工作对高活和低活不同群体学习 2 个独立策略,采用不同的数据流进行训练,Actor 最小化回访时间同时最大化辅助奖励。如图 1(c),以高活群体为例,Actor loss 为:
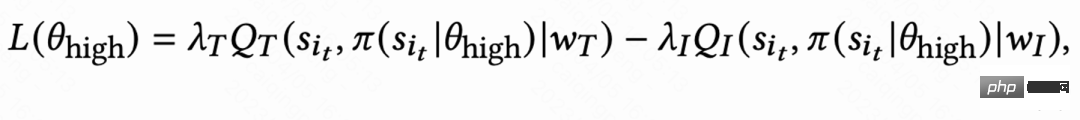
解决不稳定性问题
由于回访时间信号延迟,一般在几个小时到数天内返回,这会导致 RL 在线训练不稳定。而直接使用现有的 behavior cloning 的方式要么极大限制学习速度要么不能保证稳定学习。因而该工作提出一个新的软正则化方法,即在 actor loss 乘上一个软正则化系数:
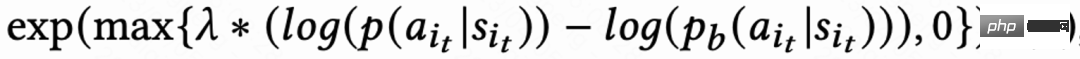
这个正则化方法本质上是一种制动效应:如果当前学习策略和样本策略偏差很大,这个 loss 会变小,学习会趋于稳定;如果学习速度趋于稳定,这个 loss 重新变大,学习速度加快。当 ,代表着对学习过程不加任何约束。
,代表着对学习过程不加任何约束。
离线实验
该工作把 RLUR 和 State of the Art 的强化学习算法 TD3,以及黑盒优化方法 Cross Entropy Method (CEM) 在公开数据集 KuaiRand 进行对比。该工作首先基于 KuaiRand 数据集搭建一个留存模拟器:包含用户立即反馈,用户离开 Session 以及用户回访 App 三个模块,然后在这个留存模拟器评测方法。
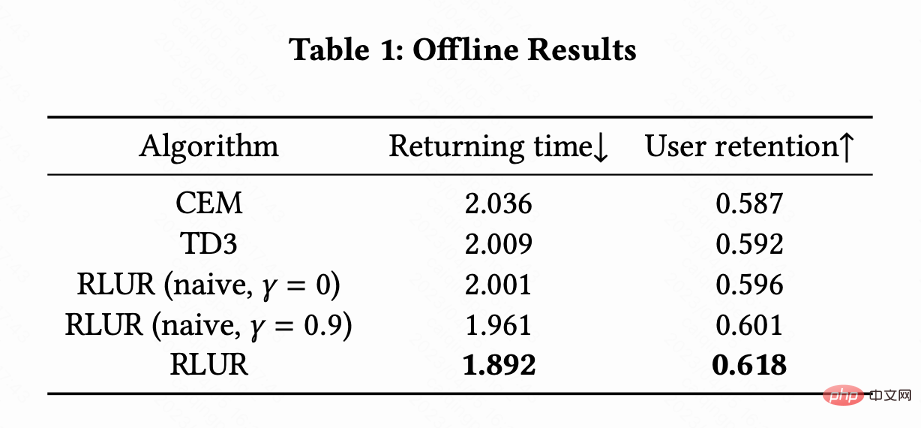
表 1 说明 RLUR 在回访时间和次留指标显著优于 CEM 和 TD3。该研究进行消融实验,对比 RLUR 和只保留留存学习部分 (RLUR (naive)),可以说明该研究针对留存挑战解决方法的有效性。并且通过 和
和 对比,说明最小化多个 session 的回访时间的算法效果优于只最小化单个 session 的回访时间。
对比,说明最小化多个 session 的回访时间的算法效果优于只最小化单个 session 的回访时间。
在线实验
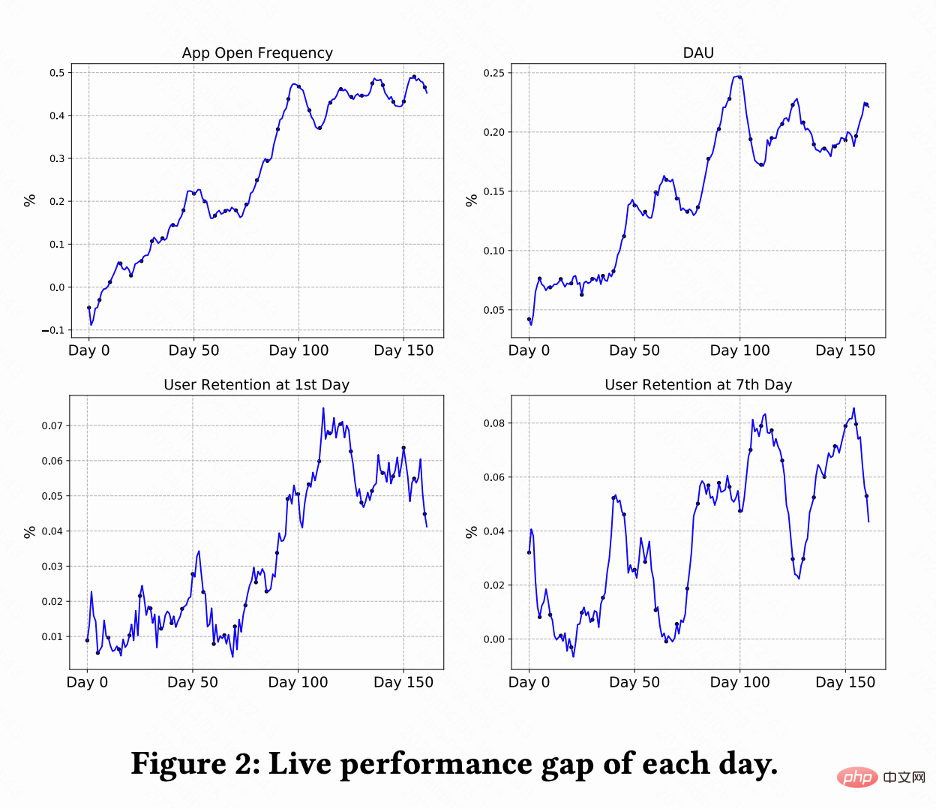
该工作在快手短视频推荐系统进行 A/B 测试对比 RLUR 和 CEM 方法。图 2 分别显示 RLUR 对比 CEM 的 App 打开频次、DAU、次留、7 留的提升百分比。可以发现 App 打开频次在 0-100 天逐渐提升乃至收敛。并且也拉动次留、7 留以及 DAU 指标的提升(0.1% 的 DAU 以及 0.01% 的次留提升视为统计显著)。
总结与未来工作
本文研究如何通过 RL 技术提升推荐系统用户留存,该工作将留存优化建模成一个无穷视野请求粒度的马尔可夫决策过程,该工作提出 RLUR 算法直接优化留存并有效地应对留存信号的几个关键挑战。RLUR 算法已在快手 App 全量,能够拿到显著的次留和 DAU 收益。关于未来工作,如何采用离线强化学习、Decision Transformer 等方法更有效地提升用户留存是一个很有前景的方向。
以上是如何运用强化学习来提升快手用户留存?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
写在前面&笔者的个人理解目前,在整个自动驾驶系统当中,感知模块扮演了其中至关重要的角色,行驶在道路上的自动驾驶车辆只有通过感知模块获得到准确的感知结果后,才能让自动驾驶系统中的下游规控模块做出及时、正确的判断和行为决策。目前,具备自动驾驶功能的汽车中通常会配备包括环视相机传感器、激光雷达传感器以及毫米波雷达传感器在内的多种数据信息传感器来收集不同模态的信息,用于实现准确的感知任务。基于纯视觉的BEV感知算法因其较低的硬件成本和易于部署的特点,以及其输出结果能便捷地应用于各种下游任务,因此受到工业
 使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
使用C++实现机器学习算法:常见挑战及解决方案
Jun 03, 2024 pm 01:25 PM
C++中机器学习算法面临的常见挑战包括内存管理、多线程、性能优化和可维护性。解决方案包括使用智能指针、现代线程库、SIMD指令和第三方库,并遵循代码风格指南和使用自动化工具。实践案例展示了如何利用Eigen库实现线性回归算法,有效地管理内存和使用高性能矩阵操作。
 使用Panda-Gym的机器臂模拟实现Deep Q-learning强化学习
Oct 31, 2023 pm 05:57 PM
使用Panda-Gym的机器臂模拟实现Deep Q-learning强化学习
Oct 31, 2023 pm 05:57 PM
强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体会因为采取行动导致预期结果而获得奖励或受到惩罚。随着时间的推移,代理会学会采取行动,以使得其预期回报最大化RL代理通常使用马尔可夫决策过程(MDP)进行训练,MDP是为顺序决策问题建模的数学框架。MDP由四个部分组成:状态:环境的可能状态的集合。动作:代理可以采取的一组动作。转换函数:在给定当前状态和动作的情况下,预测转换到新状态的概率的函数。奖励函数:为每次转换分配奖励给代理的函数。代理的目标是学习策略函数,
 探究C++sort函数的底层原理与算法选择
Apr 02, 2024 pm 05:36 PM
探究C++sort函数的底层原理与算法选择
Apr 02, 2024 pm 05:36 PM
C++sort函数底层采用归并排序,其复杂度为O(nlogn),并提供不同的排序算法选择,包括快速排序、堆排序和稳定排序。
 人工智能可以预测犯罪吗?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智能可以预测犯罪吗?探索CrimeGPT的能力
Mar 22, 2024 pm 10:10 PM
人工智能(AI)与执法领域的融合为犯罪预防和侦查开辟了新的可能性。人工智能的预测能力被广泛应用于CrimeGPT(犯罪预测技术)等系统,用于预测犯罪活动。本文探讨了人工智能在犯罪预测领域的潜力、目前的应用情况、所面临的挑战以及相关技术可能带来的道德影响。人工智能和犯罪预测:基础知识CrimeGPT利用机器学习算法来分析大量数据集,识别可以预测犯罪可能发生的地点和时间的模式。这些数据集包括历史犯罪统计数据、人口统计信息、经济指标、天气模式等。通过识别人类分析师可能忽视的趋势,人工智能可以为执法机构
 改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
改进的检测算法:用于高分辨率光学遥感图像目标检测
Jun 06, 2024 pm 12:33 PM
01前景概要目前,难以在检测效率和检测结果之间取得适当的平衡。我们就研究出了一种用于高分辨率光学遥感图像中目标检测的增强YOLOv5算法,利用多层特征金字塔、多检测头策略和混合注意力模块来提高光学遥感图像的目标检测网络的效果。根据SIMD数据集,新算法的mAP比YOLOv5好2.2%,比YOLOX好8.48%,在检测结果和速度之间实现了更好的平衡。02背景&动机随着远感技术的快速发展,高分辨率光学远感图像已被用于描述地球表面的许多物体,包括飞机、汽车、建筑物等。目标检测在远感图像的解释中
 算法在 58 画像平台建设中的应用
May 09, 2024 am 09:01 AM
算法在 58 画像平台建设中的应用
May 09, 2024 am 09:01 AM
一、58画像平台建设背景首先和大家分享下58画像平台的建设背景。1.传统的画像平台传统的思路已经不够,建设用户画像平台依赖数据仓库建模能力,整合多业务线数据,构建准确的用户画像;还需要数据挖掘,理解用户行为、兴趣和需求,提供算法侧的能力;最后,还需要具备数据平台能力,高效存储、查询和共享用户画像数据,提供画像服务。业务自建画像平台和中台类型画像平台主要区别在于,业务自建画像平台服务单条业务线,按需定制;中台平台服务多条业务线,建模复杂,提供更为通用的能力。2.58中台画像建设的背景58的用户画像
 20分钟学会装配电路板!开源SERL框架精密操控成功率100%,速度三倍于人类
Feb 21, 2024 pm 03:31 PM
20分钟学会装配电路板!开源SERL框架精密操控成功率100%,速度三倍于人类
Feb 21, 2024 pm 03:31 PM
现在,机器人学会工厂精密操控任务了。近年来,机器人强化学习技术领域取得显着的进展,例如四足行走,抓取,灵巧操控等,但大多数局限于实验室展示阶段。将机器人强化学习技术广泛应用到实际生产环境仍面临众多挑战,这在一定程度上限制了其在真实场景的应用范围。强化学习技术在实际应用的过程中,任需克服包括奖励机制设定、环境重置、样本效率提升及动作安全性保障等多重复杂的问题。业内专家强调,解决强化学习技术实际落地的诸多难题,与算法本身的持续创新同等重要。面对这一挑战,来自加州大学伯克利、斯坦福大学、华盛顿大学以及
