

YOLOv6又快又准的目标检测框架已经开源了

作者:楚怡、凯衡等
近日,美团视觉智能部研发了一款致力于工业应用的目标检测框架 YOLOv6,能够同时专注于检测的精度和推理效率。在研发过程中,视觉智能部不断进行了探索和优化,同时吸取借鉴了学术界和工业界的一些前沿进展和科研成果。在目标检测权威数据集 COCO 上的实验结果显示,YOLOv6 在检测精度和速度方面均超越其他同体量的算法,同时支持多种不同平台的部署,极大简化工程部署时的适配工作。特此开源,希望能帮助到更多的同学。
1. 概述
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中:YOLOv6-nano 在 COCO 上精度可达 35.0% AP,在 T4 上推理速度可达 1242 FPS;YOLOv6-s 在 COCO 上精度可达 43.1% AP,在 T4 上推理速度可达 520 FPS。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。目前,项目已开源至Github,传送门:YOLOv6。欢迎有需要的小伙伴们Star收藏,随时取用。
精度与速度远超 YOLOv5 和 YOLOX 的新框架
目标检测作为计算机视觉领域的一项基础性技术,在工业界得到了广泛的应用,其中 YOLO 系列算法因其较好的综合性能,逐渐成为大多数工业应用时的首选框架。至今,业界已衍生出许多 YOLO 检测框架,其中以 YOLOv5[1]、YOLOX[2] 和 PP-YOLOE[3] 最具代表性,但在实际使用中,我们发现上述框架在速度和精度方面仍有很大的提升的空间。基于此,我们通过研究并借鉴了业界已有的先进技术,开发了一套新的目标检测框架——YOLOv6。该框架支持模型训练、推理及多平台部署等全链条的工业应用需求,并在网络结构、训练策略等算法层面进行了多项改进和优化,在 COCO 数据集上,YOLOv6 在精度和速度方面均超越其他同体量算法,相关结果如下图 1 所示:
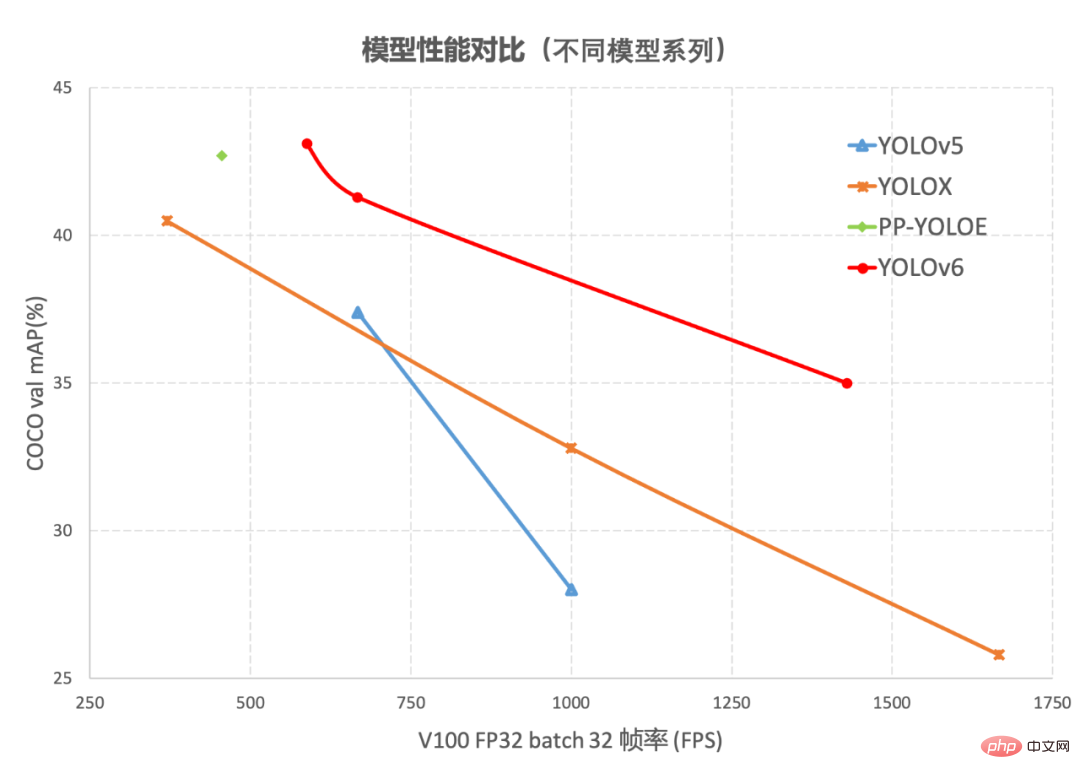
图1-1 YOLOv6 各尺寸模型与其他模型性能对比
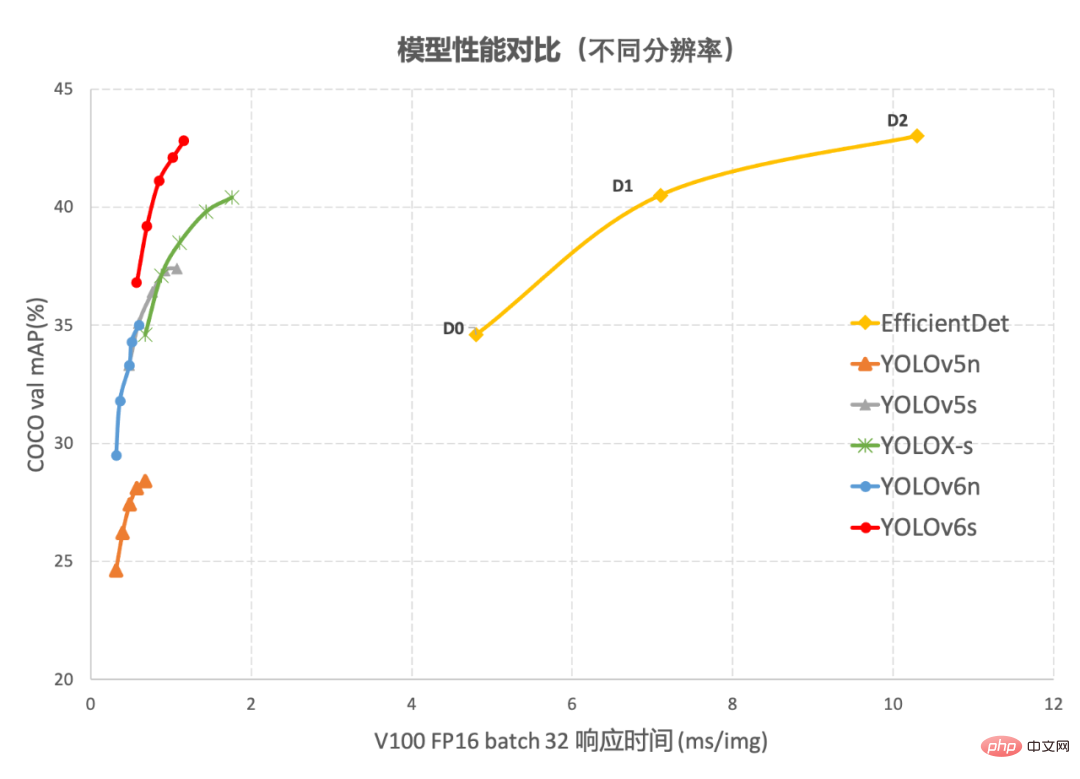
图1-2 YOLOv6 与其他模型在不同分辨率下性能对比图 1-1 展示了不同尺寸网络下各检测算法的性能对比,曲线上的点分别表示该检测算法在不同尺寸网络下(s/tiny/nano)的模型性能,从图中可以看到,YOLOv6 在精度和速度方面均超越其他 YOLO 系列同体量算法。图 1-2 展示了输入分辨率变化时各检测网络模型的性能对比,曲线上的点从左往右分别表示图像分辨率依次增大时(384/448/512/576/640)该模型的性能,从图中可以看到,YOLOv6 在不同分辨率下,仍然保持较大的性能优势。
2. YOLOv6关键技术介绍
YOLOv6 主要在 Backbone、Neck、Head 以及训练策略等方面进行了诸多的改进:
- 我们统一设计了更高效的 Backbone 和 Neck :受到硬件感知神经网络设计思想的启发,基于 RepVGG style[4] 设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 和 Rep-PAN Neck。
- 优化设计了更简洁有效的 Efficient Decoupled Head,在维持精度的同时,进一步降低了一般解耦头带来的额外延时开销。
- 在训练策略上,我们采用Anchor-free 无锚范式,同时辅以 SimOTA[2] 标签分配策略以及 SIoU[9] 边界框回归损失来进一步提高检测精度。
2.1 Hardware-friendly 的骨干网络设计
YOLOv5/YOLOX 使用的 Backbone 和 Neck 都基于 CSPNet[5] 搭建,采用了多分支的方式和残差结构。对于 GPU 等硬件来说,这种结构会一定程度上增加延时,同时减小内存带宽利用率。下图 2 为计算机体系结构领域中的 Roofline Model[8] 介绍图,显示了硬件中计算能力和内存带宽之间的关联关系。
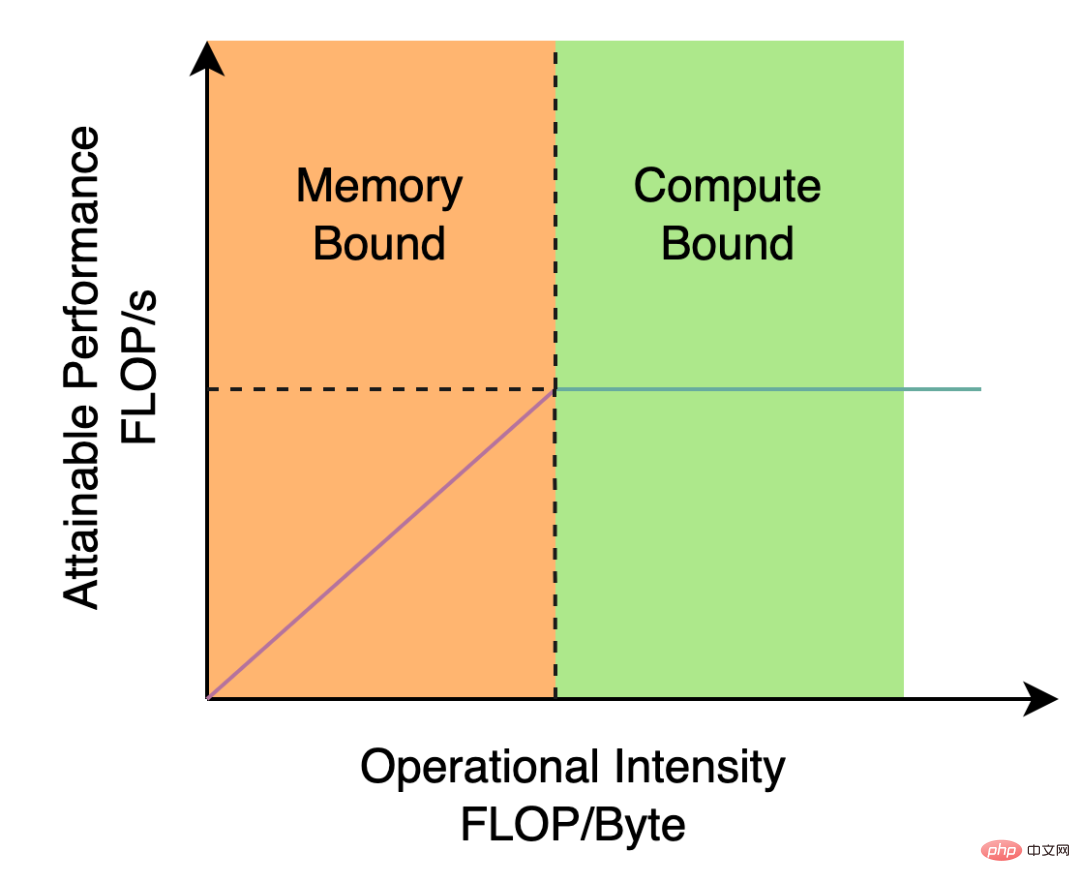
图2 Roofline Model 介绍图
于是,我们基于硬件感知神经网络设计的思想,对 Backbone 和 Neck 进行了重新设计和优化。该思想基于硬件的特性、推理框架/编译框架的特点,以硬件和编译友好的结构作为设计原则,在网络构建时,综合考虑硬件计算能力、内存带宽、编译优化特性、网络表征能力等,进而获得又快又好的网络结构。对上述重新设计的两个检测部件,我们在 YOLOv6 中分别称为 EfficientRep Backbone 和 Rep-PAN Neck,其主要贡献点在于:
- 引入了 RepVGG[4] style 结构。
- 基于硬件感知思想重新设计了 Backbone 和 Neck。
RepVGG[4] Style 结构是一种在训练时具有多分支拓扑,而在实际部署时可以等效融合为单个 3x3 卷积的一种可重参数化的结构(融合过程如下图 3 所示)。通过融合成的 3x3 卷积结构,可以有效利用计算密集型硬件计算能力(比如 GPU),同时也可获得 GPU/CPU 上已经高度优化的 NVIDIA cuDNN 和 Intel MKL 编译框架的帮助。
实验表明,通过上述策略,YOLOv6 减少了在硬件上的延时,并显著提升了算法的精度,让检测网络更快更强。以 nano 尺寸模型为例,对比 YOLOv5-nano 采用的网络结构,本方法在速度上提升了21%,同时精度提升 3.6% AP。
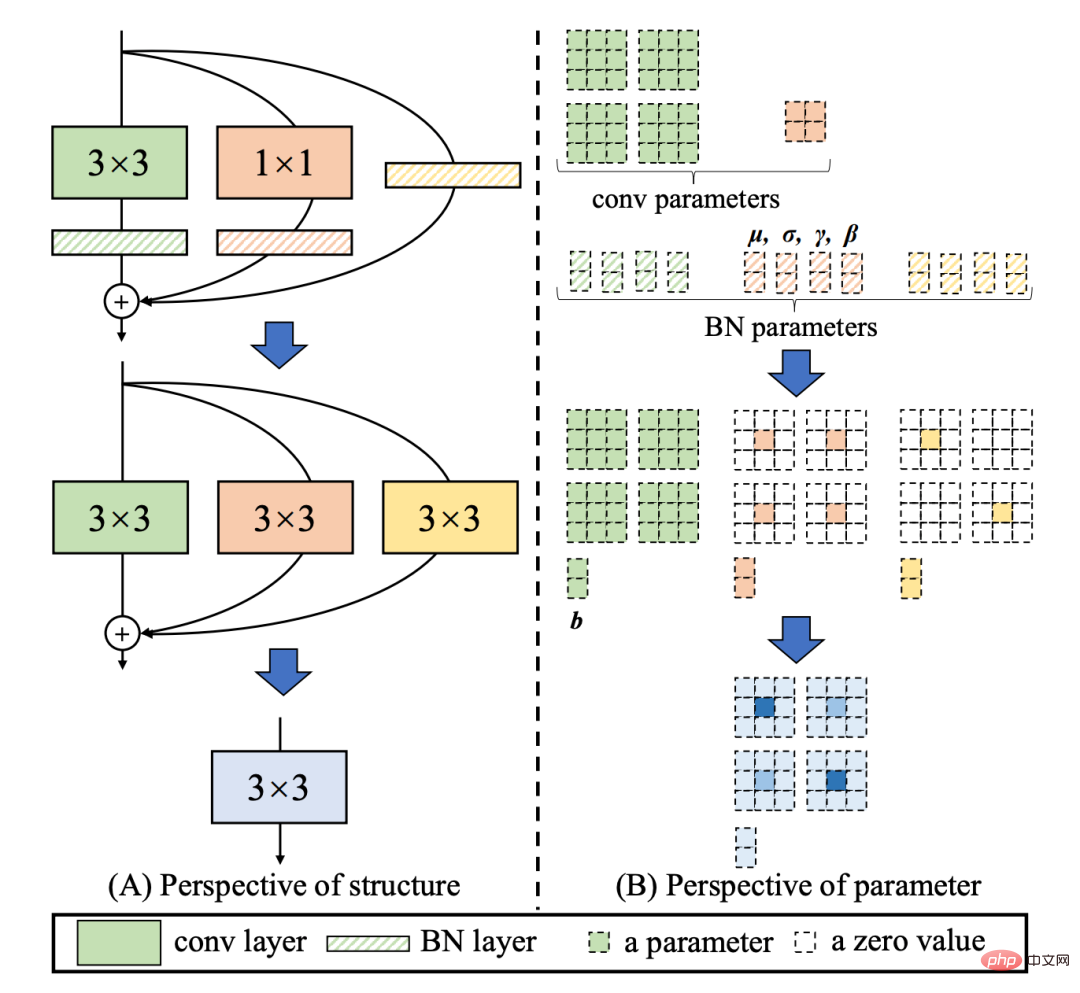
图3 Rep算子的融合过程[4]
EfficientRep Backbone:在 Backbone 设计方面,我们基于以上 Rep 算子设计了一个高效的Backbone。相比于 YOLOv5 采用的 CSP-Backbone,该 Backbone 能够高效利用硬件(如 GPU)算力的同时,还具有较强的表征能力。
下图 4 为 EfficientRep Backbone 具体设计结构图,我们将 Backbone 中 stride=2 的普通 Conv 层替换成了 stride=2 的 RepConv层。同时,将原始的 CSP-Block 都重新设计为 RepBlock,其中 RepBlock 的第一个 RepConv 会做 channel 维度的变换和对齐。另外,我们还将原始的 SPPF 优化设计为更加高效的 SimSPPF。
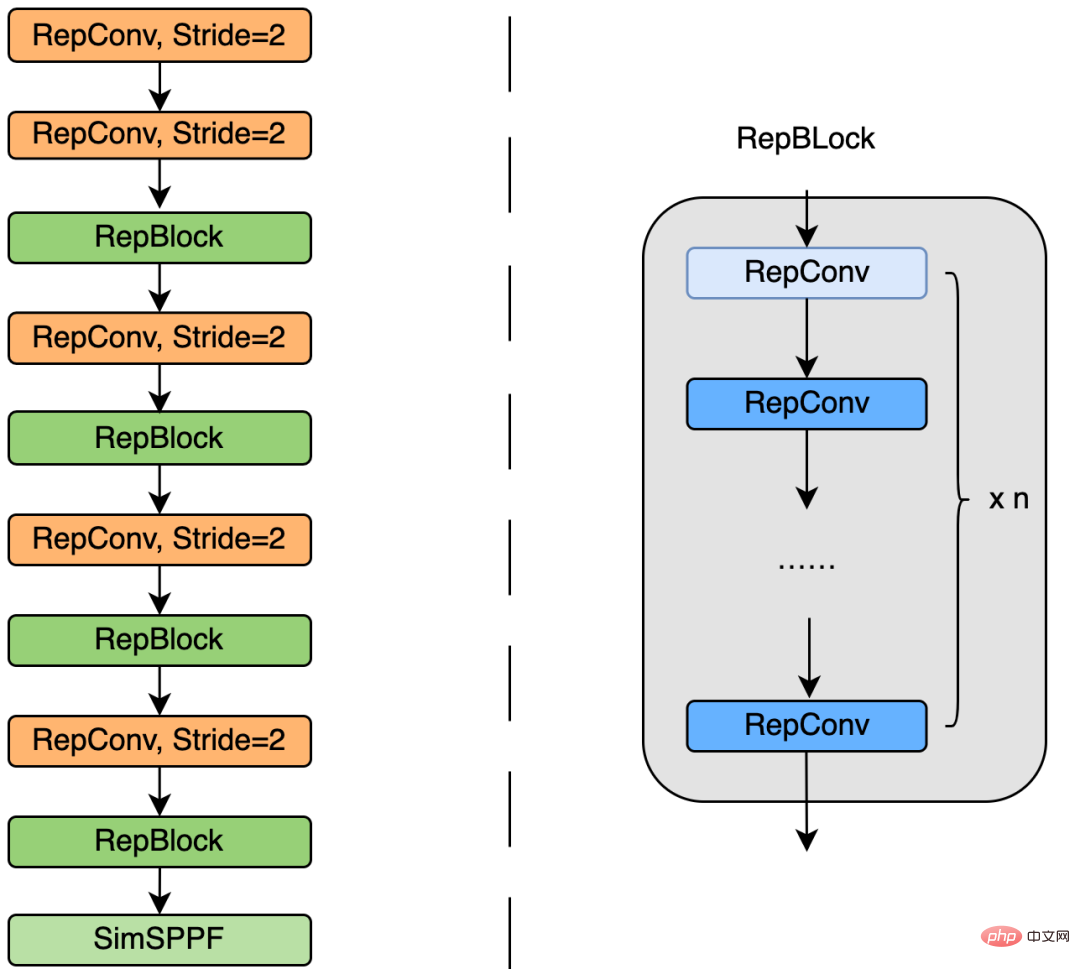
图4 EfficientRep Backbone 结构图
Rep-PAN:在 Neck 设计方面,为了让其在硬件上推理更加高效,以达到更好的精度与速度的平衡,我们基于硬件感知神经网络设计思想,为 YOLOv6 设计了一个更有效的特征融合网络结构。
Rep-PAN 基于 PAN[6] 拓扑方式,用 RepBlock 替换了 YOLOv5 中使用的 CSP-Block,同时对整体 Neck 中的算子进行了调整,目的是在硬件上达到高效推理的同时,保持较好的多尺度特征融合能力(Rep-PAN 结构图如下图 5 所示)。
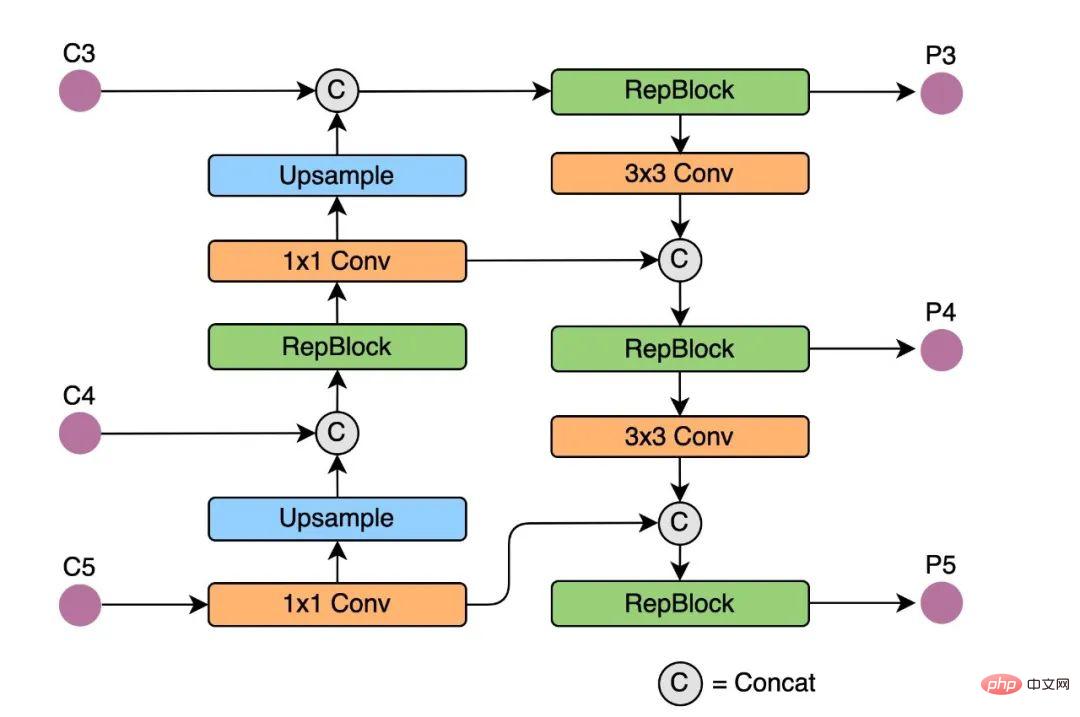
图5 Rep-PAN 结构图
2.2 更简洁高效的 Decoupled Head
在 YOLOv6 中,我们采用了解耦检测头(Decoupled Head)结构,并对其进行了精简设计。原始 YOLOv5 的检测头是通过分类和回归分支融合共享的方式来实现的,而 YOLOX 的检测头则是将分类和回归分支进行解耦,同时新增了两个额外的 3x3 的卷积层,虽然提升了检测精度,但一定程度上增加了网络延时。
因此,我们对解耦头进行了精简设计,同时综合考虑到相关算子表征能力和硬件上计算开销这两者的平衡,采用 Hybrid Channels 策略重新设计了一个更高效的解耦头结构,在维持精度的同时降低了延时,缓解了解耦头中 3x3 卷积带来的额外延时开销。通过在 nano 尺寸模型上进行消融实验,对比相同通道数的解耦头结构,精度提升 0.2% AP 的同时,速度提升6.8%。
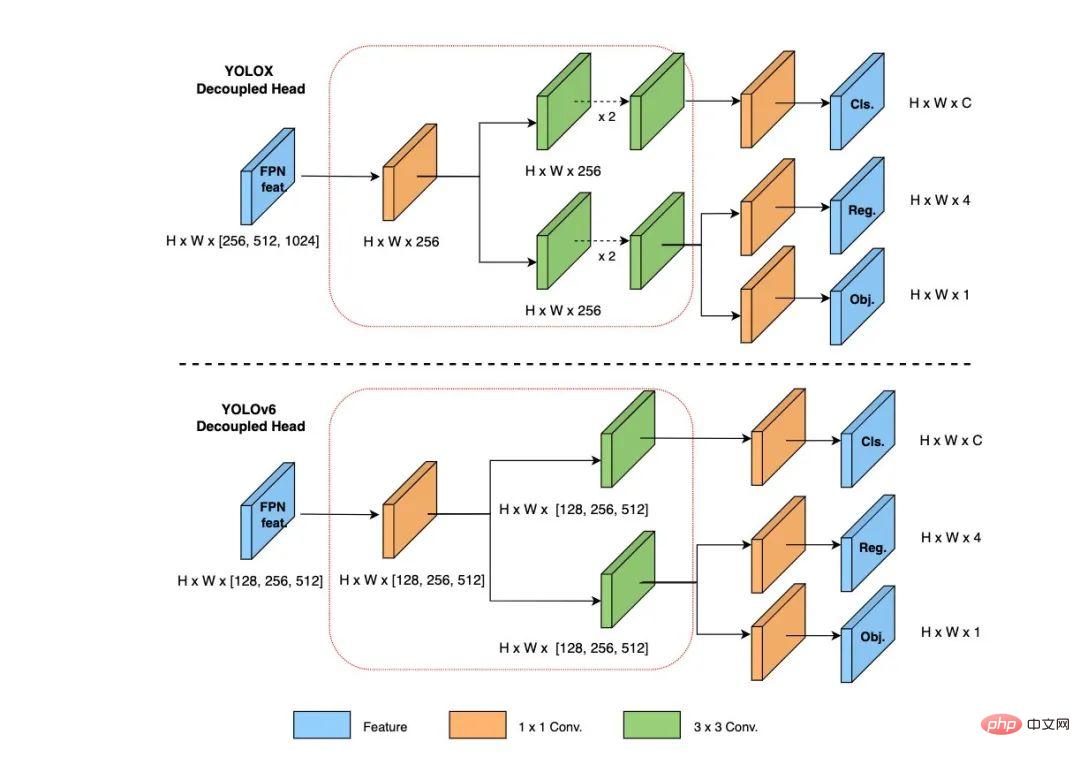
图6 Efficient Decoupled Head 结构图
2.3 更有效的训练策略
为了进一步提升检测精度,我们吸收借鉴了学术界和业界其他检测框架的先进研究进展:Anchor-free 无锚范式 、SimOTA 标签分配策略以及 SIoU 边界框回归损失。
Anchor-free 无锚范式
YOLOv6 采用了更简洁的 Anchor-free 检测方法。由于 Anchor-based检测器需要在训练之前进行聚类分析以确定最佳 Anchor 集合,这会一定程度提高检测器的复杂度;同时,在一些边缘端的应用中,需要在硬件之间搬运大量检测结果的步骤,也会带来额外的延时。而 Anchor-free 无锚范式因其泛化能力强,解码逻辑更简单,在近几年中应用比较广泛。经过对 Anchor-free 的实验调研,我们发现,相较于Anchor-based 检测器的复杂度而带来的额外延时,Anchor-free 检测器在速度上有51%的提升。
SimOTA 标签分配策略
为了获得更多高质量的正样本,YOLOv6 引入了 SimOTA [4]算法动态分配正样本,进一步提高检测精度。YOLOv5 的标签分配策略是基于 Shape 匹配,并通过跨网格匹配策略增加正样本数量,从而使得网络快速收敛,但是该方法属于静态分配方法,并不会随着网络训练的过程而调整。
近年来,也出现不少基于动态标签分配的方法,此类方法会根据训练过程中的网络输出来分配正样本,从而可以产生更多高质量的正样本,继而又促进网络的正向优化。例如,OTA[7] 通过将样本匹配建模成最佳传输问题,求得全局信息下的最佳样本匹配策略以提升精度,但 OTA 由于使用了Sinkhorn-Knopp 算法导致训练时间加长,而 SimOTA[4]算法使用 Top-K 近似策略来得到样本最佳匹配,大大加快了训练速度。故 YOLOv6 采用了SimOTA 动态分配策略,并结合无锚范式,在 nano 尺寸模型上平均检测精度提升 1.3% AP。
SIoU 边界框回归损失
为了进一步提升回归精度,YOLOv6 采用了 SIoU[9] 边界框回归损失函数来监督网络的学习。目标检测网络的训练一般需要至少定义两个损失函数:分类损失和边界框回归损失,而损失函数的定义往往对检测精度以及训练速度产生较大的影响。
近年来,常用的边界框回归损失包括IoU、GIoU、CIoU、DIoU loss等等,这些损失函数通过考虑预测框与目标框之前的重叠程度、中心点距离、纵横比等因素来衡量两者之间的差距,从而指导网络最小化损失以提升回归精度,但是这些方法都没有考虑到预测框与目标框之间方向的匹配性。SIoU 损失函数通过引入了所需回归之间的向量角度,重新定义了距离损失,有效降低了回归的自由度,加快网络收敛,进一步提升了回归精度。通过在 YOLOv6s 上采用 SIoU loss 进行实验,对比 CIoU loss,平均检测精度提升 0.3% AP。
3. 实验结果
经过以上优化策略和改进,YOLOv6 在多个不同尺寸下的模型均取得了卓越的表现。下表 1 展示了 YOLOv6-nano 的消融实验结果,从实验结果可以看出,我们自主设计的检测网络在精度和速度上都带来了很大的增益。
表1 YOLOv6-nano 消融实验结果下表 2 展示了 YOLOv6 与当前主流的其他 YOLO 系列算法相比较的实验结果。从表格中可以看到:
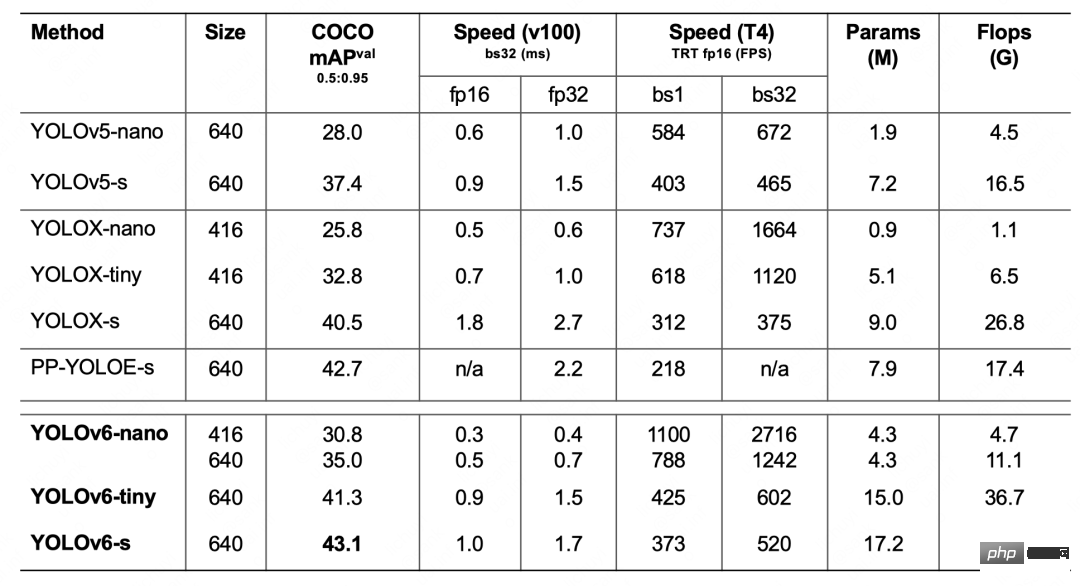
表2 YOLOv6各尺寸模型性能与其他模型的比较
- YOLOv6-nano 在 COCO val 上 取得了 35.0% AP 的精度,同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 1242FPS 的性能,相较于 YOLOv5-nano 精度提升 7% AP,速度提升 85%。
- YOLOv6-tiny 在 COCO val 上 取得了 41.3% AP 的精度, 同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 602FPS 的性能,相较于 YOLOv5-s 精度提升 3.9% AP,速度提升 29.4%。
- YOLOv6-s 在 COCO val 上 取得了 43.1% AP 的精度, 同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 520FPS 的性能,相较于 YOLOX-s 精度提升 2.6% AP,速度提升 38.6%;相较于 PP-YOLOE-s 精度提升 0.4% AP的条件下,在T4上使用 TRT FP16 进行单 batch 推理,速度提升 71.3%。
4. 总结与展望
本文介绍了美团视觉智能部在目标检测框架方面的优化及实践经验,我们针对 YOLO 系列框架,在训练策略、主干网络、多尺度特征融合、检测头等方面进行了思考和优化,设计了新的检测框架-YOLOv6,初衷来自于解决工业应用落地时所遇到的实际问题。
在打造 YOLOv6 框架的同时,我们探索和优化了一些新的方法,例如基于硬件感知神经网络设计思想自研了 EfficientRep Backbone、Rep-Neck 和 Efficient Decoupled Head,同时也吸收借鉴了学术界和工业界的一些前沿进展和成果,例如 Anchor-free、SimOTA 和 SIoU 回归损失。在 COCO 数据集上的实验结果显示,YOLOv6 在检测精度和速度方面都属于佼佼者。
未来我们会持续建设和完善 YOLOv6 生态,主要工作包括以下几个方面:
- 完善 YOLOv6 全系列模型,持续提升检测性能。
- 在多种硬件平台上,设计硬件友好的模型。
- 支持 ARM 平台部署以及量化蒸馏等全链条适配。
- 横向拓展和引入关联技术,如半监督、自监督学习等等。
- 探索 YOLOv6 在更多的未知业务场景上的泛化性能。
以上是YOLOv6又快又准的目标检测框架已经开源了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 十个推荐开源免费文本标注工具
Mar 26, 2024 pm 08:20 PM
十个推荐开源免费文本标注工具
Mar 26, 2024 pm 08:20 PM
文本标注工作是将标签或标记与文本中特定内容相对应的工作。其主要目的是为文本提供额外的信息,以便进行更深入的分析和处理,尤其是在人工智能领域。文本标注对于人工智能应用中的监督机器学习任务至关重要。用于训练AI模型,有助更准确地理解自然语言文本信息,提高文本分类、情感分析和语言翻译等任务的性能。通过文本标注,我们可以教AI模型识别文本中的实体、理解上下文,并在出现新的类似数据时做出准确的预测。本文主要推荐一些较好的开源文本标注工具。1.LabelStudiohttps://github.com/Hu
 15个值得推荐的开源免费图像标注工具
Mar 28, 2024 pm 01:21 PM
15个值得推荐的开源免费图像标注工具
Mar 28, 2024 pm 01:21 PM
图像标注是将标签或描述性信息与图像相关联的过程,以赋予图像内容更深层次的含义和解释。这一过程对于机器学习至关重要,它有助于训练视觉模型以更准确地识别图像中的各个元素。通过为图像添加标注,使得计算机能够理解图像背后的语义和上下文,从而提高对图像内容的理解和分析能力。图像标注的应用范围广泛,涵盖了许多领域,如计算机视觉、自然语言处理和图视觉模型具有广泛的应用领域,例如,辅助车辆识别道路上的障碍物,帮助疾病的检测和诊断通过医学图像识别。本文主要推荐一些较好的开源免费的图像标注工具。1.Makesens
 美团外卖柜怎么取
Apr 08, 2024 pm 03:41 PM
美团外卖柜怎么取
Apr 08, 2024 pm 03:41 PM
1、当外卖员将餐食放入柜中后,会通过短信、电话或美团消息通知顾客取餐。2、顾客可以通过微信或美团APP扫描取餐柜上的二维码,进入智能取餐柜小程序。3、输入取件码或使用“一键开柜”功能,即可轻松开启柜门,取走外卖。
 推荐:优秀JS开源人脸检测识别项目
Apr 03, 2024 am 11:55 AM
推荐:优秀JS开源人脸检测识别项目
Apr 03, 2024 am 11:55 AM
人脸检测识别技术已经是一个比较成熟且应用广泛的技术。而目前最为广泛的互联网应用语言非JS莫属,在Web前端实现人脸检测识别相比后端的人脸识别有优势也有弱势。优势包括减少网络交互、实时识别,大大缩短了用户等待时间,提高了用户体验;弱势是:受到模型大小限制,其中准确率也有限。如何在web端使用js实现人脸检测呢?为了实现Web端人脸识别,需要熟悉相关的编程语言和技术,如JavaScript、HTML、CSS、WebRTC等。同时还需要掌握相关的计算机视觉和人工智能技术。值得注意的是,由于Web端的计
 美团支付密码忘记了怎么找回_美团找回支付密码忘记的方法
Mar 28, 2024 pm 03:29 PM
美团支付密码忘记了怎么找回_美团找回支付密码忘记的方法
Mar 28, 2024 pm 03:29 PM
1、首先我们进入美团软件,在我的菜单页面中找到设置,点击进入设置。2、接着我们在设置页面中找到支付设置,点击进入支付设置。3、进入支付中心,找到支付密码设置,点击进入支付密码设置。4、在支付密码设置页面中,找到找回支付密码,点击进入页面选项。5、输入想要找回的支付密码信息,点击验证,通过后即可找回支付密码。
 美团怎么删除评价 删除评价操作方法
Mar 12, 2024 pm 07:31 PM
美团怎么删除评价 删除评价操作方法
Mar 12, 2024 pm 07:31 PM
我们在使用这款平台的时候,上面也是拥有对于各种美食还有消费方面都是有评价的,其中的一些操作方法也是极为简单的,我们所去消费的时候,都应该能够看到上面对于一些功能方面的一些选择,都是可以自己来进行一些打分评价的,不过有些时候我们可能要自己来删除对于一些店铺方面的错误评价,但是用户们不知道怎么去进行这些评价,所以今日小编就来给你们详细的讲解上面的一些功能,所以有任何想法的,今日小编就来给你们详解怎么去进行删除,有兴趣的话,现在就和小编一起来看看吧,我相信大家们应该都会有所了解,不要错过了。 删
 阿里7B多模态文档理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
阿里7B多模态文档理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
多模态文档理解能力新SOTA!阿里mPLUG团队发布最新开源工作mPLUG-DocOwl1.5,针对高分辨率图片文字识别、通用文档结构理解、指令遵循、外部知识引入四大挑战,提出了一系列解决方案。话不多说,先来看效果。复杂结构的图表一键识别转换为Markdown格式:不同样式的图表都可以:更细节的文字识别和定位也能轻松搞定:还能对文档理解给出详细解释:要知道,“文档理解”目前是大语言模型实现落地的一个重要场景,市面上有很多辅助文档阅读的产品,有的主要通过OCR系统进行文字识别,配合LLM进行文字理
 美团地址在哪里改?美团地址修改教程!
Mar 15, 2024 pm 04:07 PM
美团地址在哪里改?美团地址修改教程!
Mar 15, 2024 pm 04:07 PM
一、美团地址在哪里改?美团地址修改教程!方法(一)1.进入美团我的页面,点击设置。2.选择个人信息。3.再点击收货地址。4.最后选择要修改的地址,点击地址右侧的笔图标,修改即可。方法(二)1.在美团app首页,单击外卖,进入后点击更多功能。2.在更多界面,点击管理地址。3.在我的收货地址界面,选择编辑。4.根据需求一一进行修改,最后点击保存地址即可。
