
AI技术发展迅猛,利用各种先进的AI模型,可以打造聊天机器人、仿人机器人、自动驾驶汽车等。AI已经成为发展最快的技术,而对象检测和物体分类是最近的趋势。
本文将介绍使用卷积神经网络从头开始构建和训练一个图像分类模型的完整步骤。本文将使用公开的Cifar-10数据集来训练这个模型。这个数据集是独一无二的,因为它包含了像汽车、飞机、狗、猫等日常所见物体的图像。通过对这些物体进行神经网络训练,本文将开发出智能系统来对现实世界中的这些东西进行分类。它包含了6万多张32x32大小的10种不同类型的物体图像。在本教程结束时,你将拥有一个可以根据物体的视觉特征来判断对象的模型。

图1 数据集样本图像|图片来自datasets.activeloop
本文将从头开始讲述所有内容,所以如果你还没有学习过神经网络的实际实现,也完全没问题。
以下是本教程的完整工作流程:
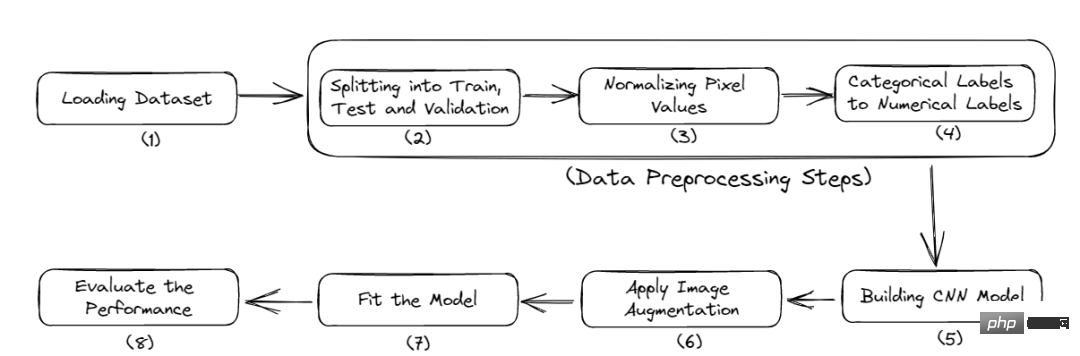
图2 完整的流程
首先必须安装一些模块才能开始这个项目。本文将使用Google Colab,因为它提供免费的GPU训练。
以下是安装所需库的命令:
<code>$ pip install tensorflow, numpy, keras, sklearn, matplotlib</code>
将库导入到Python文件中。
<code>from numpy import *from pandas import *import matplotlib.pyplot as plotter# 将数据分成训练集和测试集。from sklearn.model_selection import train_test_split# 用来评估我们的训练模型的库。from sklearn.metrics import classification_report, confusion_matriximport keras# 加载我们的数据集。from keras.datasets import cifar10# 用于数据增量。from keras.preprocessing.image import ImageDataGenerator# 下面是一些用于训练卷积Nueral网络的层。from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten</code>
现在,进入数据加载的步骤。
本节将加载数据集并执行训练-测试数据的拆分。
加载和拆分数据:
<code># 类的数量nc = 10(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()((training_data),(validation_data),(training_label),(validation_label),) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)training_data = training_data.astype("float32")testing_data = testing_data.astype("float32")validation_data = validation_data.astype("float32")</code>cifar10数据集是直接从Keras数据集库中加载的。并且这些数据也分为训练数据和测试数据。训练数据用于训练模型,以便它可以识别其中的模式。而测试数据对模型来说是不可见的,它被用来检查其性能,即相对于总的数据点,有多少数据点被正确预测。
training_label包含了与training_data中的图像对应的标签。
然后使用内置sklearn的train_test_split函数将训练数据再次拆分成验证数据。验证数据用于选择和调整最终的模型。最后,所有的训练、测试和验证数据都转换为32位的浮点数。
现在,数据集的加载已经完成。在下一节中,本文将对其执行一些预处理步骤。
数据预处理是开发机器学习模型时的第一步,也是最关键的一步。跟随本文一起看看如何做到这一点。
<code># 归一化training_data /= 255testing_data /= 255validation_data /= 255# 热编码training_label = keras.utils.to_categorical(training_label, nc)testing_label = keras.utils.to_categorical(testing_label, nc)validation_label = keras.utils.to_categorical(validation_label, nc)# 输出数据集print("Training: ", training_data.shape, len(training_label))print("Validation: ", validation_data.shape, len(validation_label))print("Testing: ", testing_data.shape, len(testing_label))</code>输出:
<code>Training:(40000, 32, 32, 3) 40000Validation:(10000, 32, 32, 3) 10000Testing:(10000, 32, 32, 3) 10000</code>
该数据集包含10个类别的图像,每个图像的大小为32x32像素。每个像素都有一个0-255的值,我们需要在0-1之间对其进行归一化以简化计算过程。之后,我们将把分类标签转换为单热编码标签。这样做是为了将分类数据转换为数值数据,这样我们就可以毫无问题地应用机器学习算法。
现在,进入CNN模型的构建。
CNN模型分三个阶段工作。第一阶段由卷积层组成,从图像中提取相关特征。第二阶段由池化层组成,用于降低图像的尺寸。它也有助于减少模型的过度拟合。第三阶段由密集层组成,将二维图像转换为一维数组。最后,这个数组被送入全连接层,进行最后的预测。
以下是代码:
<code>model = Sequential()model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu", input_shape=(32, 32, 3)))model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dropout(0.4))model.add(Dense(256, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(128, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(nc, activatinotallow="softmax"))</code>
本文应用了三组图层,每组包含两个卷积层、一个最大池化层和一个丢弃层。Conv2D层接收input_shape为(32,32,3),必须与图像的尺寸相同。
每个Conv2D层还需要一个激活函数,即relu。激活函数是用于增加系统中的非线性。更简单地说,它决定神经元是否需要根据某个阈值被激活。有许多类型的激活函数,如ReLu、Tanh、Sigmoid、Softmax等,它们使用不同的算法来决定神经元的激发。
之后,添加了平坦层和全连接层,在它们之间还有几个Dropout层。Dropout层随机地拒绝一些神经元对网层的贡献。它里面的参数定义了拒绝的程度。它主要用于避免过度拟合。
下面是一个CNN模型架构的示例图像。
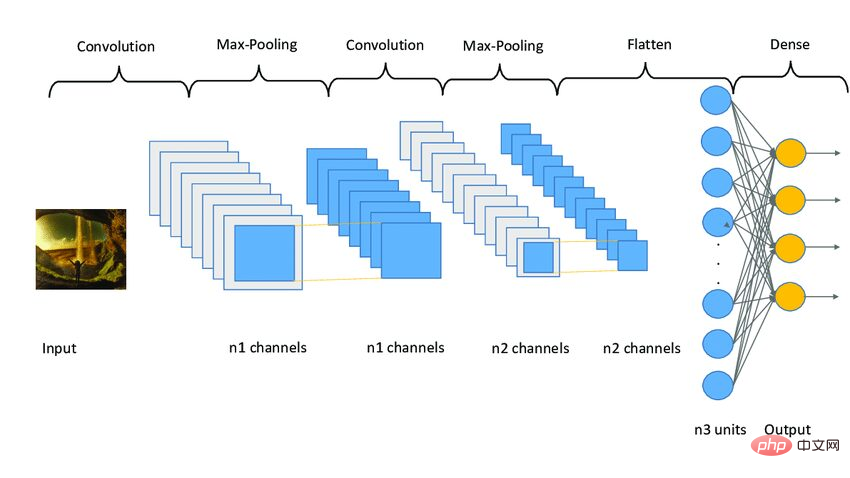
图3 Sampe CNN架构|图片来源:Researchgate
现在,本文将编译和准备训练的模型。
<code># 启动Adam优化器opt = keras.optimizers.Adam(lr=0.0001)model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])# 获得模型的摘要model.summary()</code>
输出:

图4 模型摘要
本文使用了学习率为0.0001的Adam优化器。优化器决定了模型的行为如何响应损失函数的输出而变化。学习率是训练期间更新权重的数量或步长。它是一个可配置的超参数,不能太小或太大。
现在,本文将把模型拟合到我们的训练数据,并开始训练过程。但在此之前,本文将使用图像增强技术来增加样本图像的数量。
卷积神经网络中使用的图像增强技术将增加训练图像,而不需要新的图像。它将通过在图像中产生一定量的变化来复制图像。它可以通过将图像旋转到一定程度、添加噪声、水平或垂直翻转等方式来实现。
<code>augmentor = ImageDataGenerator(width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=False,vertical_flip=True,)# 在augmentor中进行拟合augmentor.fit(training_data)# 获得历史数据history = model.fit(augmentor.flow(training_data, training_label, batch_size=32),epochs=100,validation_data=(validation_data, validation_label),)</code>
输出:

图5 每个时期的准确度和损失
ImageDataGenerator()函数用于创建增强的图像。fit()用于拟合模型。它以训练和验证数据、Batch Size和Epochs的数量作为输入。
Batch Size是在模型更新之前处理的样本数量。一个关键的超参数必须大于等于1且小于等于样本数。通常情况下,32或64被认为是最好的Batch Size。
Epochs的数量代表了所有样本在网络的前向和后向都被单独处理了多少次。100个epochs意味着整个数据集通过模型100次,模型本身运行100次。
我们的模型已经训练完毕,现在我们将评估它在测试集上的表现。
本节将在测试集上检查模型的准确性和损失。此外,本文还将绘制训练和验证数据的准确率与时间之间和损失与时间之间的关系图。
<code>model.evaluate(testing_data, testing_label)</code>
输出:
<code>313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545[0.8554493188858032, 0.7545000195503235]</code>
本文的模型达到了75.34%的准确率,损失为0.8554。这个准确率还可以提高,因为这不是一个最先进的模型。本文用这个模型来解释建立模型的过程和流程。CNN模型的准确性取决于许多因素,如层的选择、超参数的选择、使用的数据集的类型等。
现在我们将绘制曲线来检查模型中的过度拟合情况。
<code>def acc_loss_curves(result, epochs):acc = result.history["accuracy"]# 获得损失和准确性loss = result.history["loss"]# 声明损失和准确度的值val_acc = result.history["val_accuracy"]val_loss = result.history["val_loss"]# 绘制图表plotter.figure(figsize=(15, 5))plotter.subplot(121)plotter.plot(range(1, epochs), acc[1:], label="Train_acc")plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")# 给予绘图的标题plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)plotter.legend()plotter.grid(True)# 传递值122plotter.subplot(122)# 使用训练损失plotter.plot(range(1, epochs), loss[1:], label="Train_loss")plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")# 使用 ephocsplotter.title("Loss over " + str(epochs) + " Epochs", size=15)plotter.legend()# 传递真值plotter.grid(True)# 打印图表plotter.show()acc_loss_curves(history, 100)</code>输出:
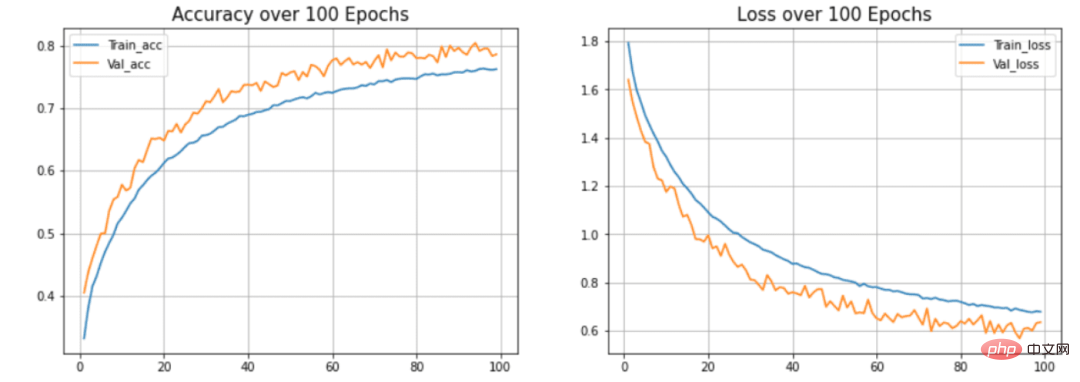
图6 准确度和损失与历时的关系
在本文的模型中,可以看到模型过度拟合测试数据集。(蓝色)线表示训练精度,(橙色)线表示验证精度。训练精度持续提高,但验证误差在20个历时后恶化。
本文展示了构建和训练卷积神经网络的整个过程。最终得到了大约75%的准确率。你可以使用超参数并使用不同的卷积层和池化层来提高准确性。你也可以尝试迁移学习,它使用预先训练好的模型,如ResNet或VGGNet,并在某些情况下可以提供非常好的准确性。
以上是用TensorFlow和Keras来构建和训练你的第一个神经网络非常容易的详细内容。更多信息请关注PHP中文网其他相关文章!






















