

ChatGPT专题之一GPT家族进化史

时间线
2018 年 6 月
OpenAI发布GPT-1模型,1.1亿参数。
2018 年 11 月
OpenAI发布GPT-2模型,15亿参数,但由于担心滥用,不向公众开放模型的全部代码及数据。
2019 年 2 月
OpenAI开放了GPT-2模型的部分代码和数据,但仍然限制了访问。
2019 年 6 月 10 日
OpenAI发布GPT-3模型,1750亿参数,并向部分合作伙伴提供了访问权限。
2019 年 9 月
OpenAI开放了GPT-2的全部代码和数据,并发布了更大版本。
2020 年 5 月
OpenAI宣布推出GPT-3模型的beta版本,该模型拥有1750亿个参数,是迄今为止最大的自然语言处理模型。
2022 年 3 月
OpenAI发布InstructGPT,用到 Instruction Tuning
2022 年 11 月 30 日
OpenAI通过GPT-3.5系列大型语言模型微调而成的,全新对话式AI模型ChatGPT正式发布。
2022 年 12 月 15 日
ChatGPT 第一次更新,提升了总体性能,增加了保存和查看历史对话记录的新功能。
2023 年 1 月 9 日
ChatGPT 第二次更新,改善了回答的真实性,增加了“停止生成”新功能。
2023 年 1 月 21 日
OpenAI发布限于部分用户使用的付费版ChatGPT Professional。
2023 年 1 月 30 日
ChatGPT第三次更新,在此提升了答案真实性的同时,还提升了数学能力。
2023 年 2 月 2 日
OpenAI正式推出ChatGPT收费版订阅服务,新版本对比免费版响应速度更快,运行更为稳定。
2023 年 3 月 15 日
OpenAI震撼推出了大型多模态模型GPT-4,不仅能够阅读文字,还能识别图像,并生成文本结果,现已接入ChatGPT 向Plus用户开放。
GPT-1:基于单向Transformer的预训练模型
在 GPT 出现之前,NLP 模型主要是基于针对特定任务的大量标注数据进行训练。这会导致一些限制:
大规模高质量的标注数据不易获得;
模型仅限于所接受的训练,泛化能力不足;
无法执行开箱即用的任务,限制了模型的落地应用。
为了克服这些问题,OpenAI走上了预训练大模型的道路。GPT-1是由OpenAI于2018年发布的第一个预训练模型,它采用了单向Transformer模型,并使用了超过40GB的文本数据进行训练。GPT-1的关键特征是:生成式预训练(无监督)+判别式任务精调(有监督)。先用无监督学习的预训练,在 8 个 GPU 上花费 了1 个月的时间,从大量未标注数据中增强AI系统的语言能力,获得大量知识,然后进行有监督的微调,与大型数据集集成来提高系统在NLP任务中的性能。GPT-1在文本生成和理解任务上表现出了很好的性能,成为了当时最先进的自然语言处理模型之一。
GPT-2:多任务预训练模型
由于单任务模型缺乏泛化性,并且多任务学习需要大量有效训练对,GPT-2在GPT-1的基础上进行了扩展和优化,去掉了有监督学习,只保留了无监督学习。GPT-2采用了更大的文本数据和更强大的计算资源进行训练,参数规模达到了1.5亿,远超过GPT-1的1.1亿参数。除了使用更大的数据集和更大的模型去学习,GPT-2还提出了一个新的更难的任务:零样本学习(zero-shot),即将预训练好的模型直接应用于诸多的下游任务。GPT-2在多项自然语言处理任务上表现出了卓越的性能,包括文本生成、文本分类、语言理解等。

GPT-3:创造出新的自然语言生成和理解能力
GPT-3是GPT系列模型中最新的一款模型,采用了更大的参数规模和更丰富的训练数据。GPT-3的参数规模达到了1.75万亿,是GPT-2的100倍以上。GPT-3在自然语言生成、对话生成和其他语言处理任务上表现出了惊人的能力,在一些任务上甚至能够创造出新的语言表达形式。
GPT-3提出了一个非常重要的概念:情境学习(In-context learning),具体内容会在下次推文中进行解释。
InstructGPT & ChatGPT
InstructGPT/ChatGPT的训练分成3步,每一步需要的数据也有些许差异,下面我们分别介绍它们。
从一个预训练的语言模型开始,应用以下三个步骤。
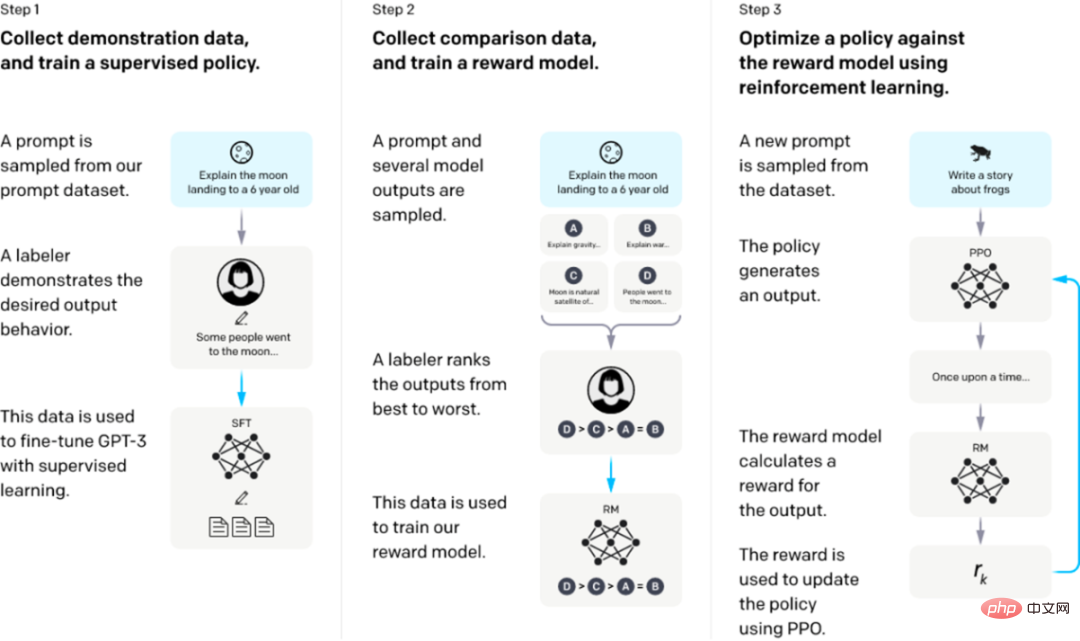
步骤1:监督微调SFT:收集演示数据,训练一个受监督的策略。我们的标签器提供了输入提示分布上所需行为的演示。然后,我们使用监督学习在这些数据上对预训练的GPT-3模型进行微调。
步骤2:奖励模型Reward Model训练。收集比较数据,训练一个奖励模型。我们收集了一个模型输出之间比较的数据集,其中标签者表示他们更喜欢给定输入的哪个输出。然后我们训练一个奖励模型来预测人类偏好的输出。
步骤3:通过奖励模型上的近端策略优化(PPO)强化学习:使用RM的输出作为标量奖励。我们使用PPO算法对监督策略进行微调,以优化该奖励。
步骤2和步骤3可以连续迭代;在当前最优策略上收集更多的比较数据,这些数据用于训练一个新的RM,然后是一个新的策略。
前两步的prompts,来自于OpenAI的在线API上的用户使用数据,以及雇佣的标注者手写的。最后一步则全都是从API数据中采样的,InstructGPT的具体数据:
1. SFT数据集
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示。
2. RM数据集
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT/ChatGPT的训练设置一个奖励目标。这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT/ChatGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序。
3. PPO数据集
InstructGPT的PPO数据没有进行标注,它均来自GPT-3的API的用户。既又不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
附 录:
ChatGPT 的各项能力来源:
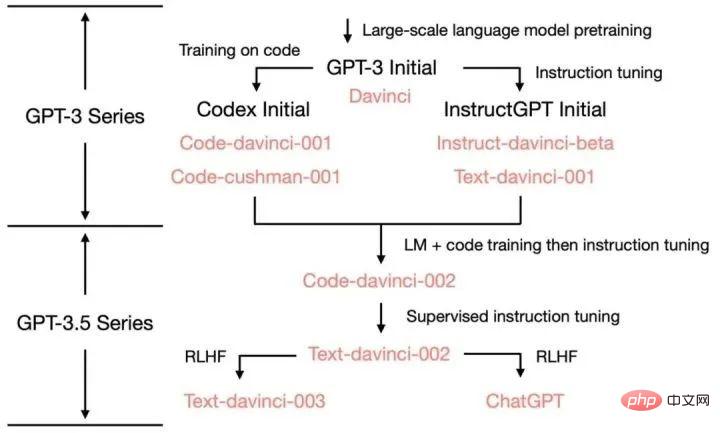
GPT-3 到 ChatGPT 以及这之间的迭代版本的能力和训练方法:

参考文献
1、拆解追溯 GPT-3.5 各项能力的起源:https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
2、全网最全时间线梳理!从ChatGPT的前世今生,到如今AI领域的竞争格局https://www.bilibili.com/read/cv22541079
3、GPT-1论文:Improving Language Understanding by Generative Pre-Training, OpenAI.
4、GPT-2论文:Language Models are Unsupervised Multitask Learners, OpenAI.
5、GPT-3论文:Language Models are Few-Shot Learners, OpenAI.
6、Jason W, Maarten B, Vincent Y, et al. Finetuned Language Models Are Zero-Shot Learners[J]. arXiv preprint arXiv: 2109.01652, 2021.
7、OpenAI是如何“魔鬼调教” GPT的?——InstructGPT论文解读 https://cloud.tencent.com/developer/news/979148
以上是ChatGPT专题之一GPT家族进化史的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 于 2023 年 9 月正式推出,是比其前身大幅改进的型号。它被认为是迄今为止最好的人工智能图像生成器之一,能够创建具有复杂细节的图像。然而,在推出时,它不包括
 YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度学习方法专注于设计最适合的目标函数,以使模型的预测结果与实际情况最接近。同时,必须设计一个合适的架构,以便为预测获取足够的信息。现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。本文将深入探讨数据通过深度网络传输时的重要问题,即信息瓶颈和可逆函数。基于此提出了可编程梯度信息(PGI)的概念,以应对深度网络实现多目标所需的各种变化。PGI可以为目标任务提供完整的输入信息,以计算目标函数,从而获得可靠的梯度信息以更新网络权重。此外设计了一种新的轻量级网络架
 ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人引言:在当今信息时代,智能客服系统已经成为企业与客户之间重要的沟通工具。而为了提供更好的客户服务体验,许多企业开始转向采用聊天机器人的方式来完成客户咨询、问题解答等任务。在这篇文章中,我们将介绍如何使用OpenAI的强大模型ChatGPT和Python语言结合,来打造一个智能客服聊天机器人,以提高
 手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
安装步骤:1、在ChatGTP官网或手机商店上下载ChatGTP软件;2、打开后在设置界面中,选择语言为中文;3、在对局界面中,选择人机对局并设置中文相谱;4、开始后在聊天窗口中输入指令,即可与软件进行交互。
 win7硬盘格式应该选择MBR还是GPT?
Jan 03, 2024 pm 08:09 PM
win7硬盘格式应该选择MBR还是GPT?
Jan 03, 2024 pm 08:09 PM
我们在使用win7操作系统的时候,有的情况下可能就会遇到需要我们重装系统,为硬盘分区的情况。对于win7硬盘格式要求mbr还是gpt这种问题小编觉得,还是要根据自己系统以及硬件配置的详细情况来进行选择即可。如果按兼容性来说的话最好还是选择mbr格式。详细内容还是来看下小编是怎么做的吧~win7硬盘格式要求mbr还是gpt1.如果系统装的是Win7的话,建议还是MBR,兼容性好。2.超过3T或装win8,可以用GPT。3.虽然GPT确实比MBR先进,但兼容性方面肯定是MBR无敌。GPT和MBR的区
 深入了解Win10分区格式:GPT和MBR的比较
Dec 22, 2023 am 11:58 AM
深入了解Win10分区格式:GPT和MBR的比较
Dec 22, 2023 am 11:58 AM
对自己的系统分区时由于用户使用的硬盘不同因此很多的用户也不知道win10分区格式gpt还是mbr,为此我们给大家带来了详细的介绍,帮助大家了解两者间的不同。win10分区格式gpt还是mbr:答:如果你使用的是超过3t的硬盘,可以用gpt。gpt相比mbr更加的先进,但是兼容性方面还是mbr更厉害。当然这也是完全可以根据用户的喜好来进行选择的。gpt和mbr的区别:一、支持的分区个数:1、MBR最多支持划分4个主分区。2、GPT则不受分区个数的限制。二、支持的硬盘大小:1、MBR最大仅支持2TB
 Kubernetes调试终极武器: K8sGPT
Feb 26, 2024 am 11:40 AM
Kubernetes调试终极武器: K8sGPT
Feb 26, 2024 am 11:40 AM
随着人工智能和机器学习技术的不断发展,企业和组织开始积极探索创新战略,以利用这些技术来提升竞争力。K8sGPT[2]是该领域内功能强大的工具之一,它是基于k8s的GPT模型,兼具k8s编排的优势和GPT模型出色的自然语言处理能力。什么是K8sGPT?先看一个例子:根据K8sGPT官网解释:K8sgpt是一个专为扫描、诊断和分类kubernetes集群问题而设计的工具,它整合了SRE经验到其分析引擎中,以提供最相关的信息。通过人工智能技术的应用,K8sgpt不断丰富其内容,帮助用户更快速、准确地解
 1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显着的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
