

Linux下怎么用python实现语音识别功能

语音识别工作原理简介
语音识别源于 20 世纪 50 年代早期在贝尔实验室所做的研究。早期语音识别系统仅能识别单个讲话者以及只有约十几个单词的词汇量。现代语音识别系统已经取得了很大进步,可以识别多个讲话者,并且拥有识别多种语言的庞大词汇表。
语音识别的首要部分当然是语音。通过麦克风,语音便从物理声音被转换为电信号,然后通过模数转换器转换为数据。一旦被数字化,就可适用若干种模型,将音频转录为文本。
大多数现代语音识别系统都依赖于隐马尔可夫模型(HMM)。其工作原理为:语音信号在非常短的时间尺度上(比如 10 毫秒)可被近似为静止过程,即一个其统计特性不随时间变化的过程。
许多现代语音识别系统会在 HMM 识别之前使用神经网络,通过特征变换和降维的技术来简化语音信号。也可以使用语音活动检测器(VAD)将音频信号减少到可能仅包含语音的部分。
幸运的是,对于 Python 使用者而言,一些语音识别服务可通过 API 在线使用,且其中大部分也提供了 Python SDK。
选择合适的python语音识别包
PyPI中有一些现成的语音识别软件包。其中包括:
apiai
google-cloud-speech
pocketsphinx
SpeechRcognition
watson-developer-cloud
wit
一些软件包(如 wit 和 apiai )提供了一些超出基本语音识别的内置功能,如识别讲话者意图的自然语言处理功能。其他软件包,如谷歌云语音,则专注于语音向文本的转换。
其中,SpeechRecognition 就因便于使用脱颖而出。
识别语音需要输入音频,而在 SpeechRecognition 中检索音频输入是非常简单的,它无需构建访问麦克风和从头开始处理音频文件的脚本,只需几分钟即可自动完成检索并运行。
安装SpeechRecognition
SpeechRecognition 兼容 Python2.6 , 2.7 和 3.3 ,但若在 Python 2 中使用还需要一些额外的安装步骤。大家可使用 pip 命令从终端安装 SpeechRecognition:pip3 install SpeechRecognition
安装完成后可以打开解释器窗口进行验证安装:

注:不要关闭此会话,在后几个步骤中你将要使用它。
若处理现有的音频文件,只需直接调用 SpeechRecognition ,注意具体的用例的一些依赖关系。同时注意,安装 PyAudio 包来获取麦克风输入
识别器类
SpeechRecognition 的核心就是识别器类。
Recognizer API 主要目是识别语音,每个 API 都有多种设置和功能来识别音频源的语音,这里我选择的是recognize_sphinx(): CMU Sphinx - requires installing PocketSphinx(支持离线的语音识别)
那么我们就需要通过pip命令来安装PocketSphinx,在安装过程中也容易出现一大串红色字体的错误。
音频文件的使用
下载相关的音频文件保存到特定的目录(直接保存到ubuntu桌面)
注意:
AudioFile 类可以通过音频文件的路径进行初始化,并提供用于读取和处理文件内容的上下文管理器界面。
SpeechRecognition 目前支持的文件类型有:
WAV: 必须是 PCM/LPCM 格式
AIFF
AIFF-CFLAC: 必须是初始 FLAC 格式;OGG-FLAC 格式不可用
英文的语音识别
在完成以上基础工作以后,就可以进行英文的语音识别了。
(1)打开终端
(2)进入语音测试文件所在目录(博主的是 桌面)
(3)打开python解释器
(4)按照下图输入相关命令
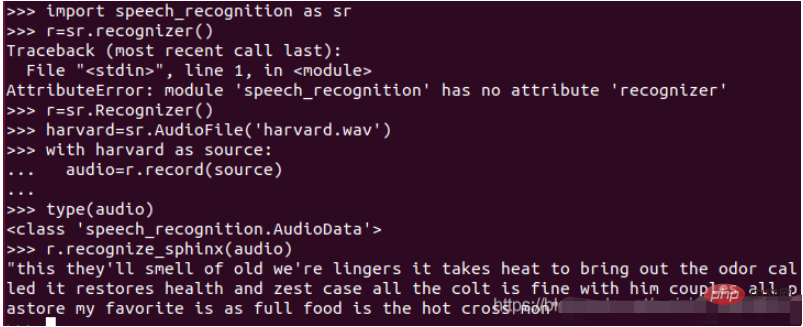
最后就可以看到语音转文字的内容(this they’ll smell …),其实效果还是很不错的!因为是英文,并且没有噪音。
噪音对语音识别的影响
噪声在现实世界中确实存在,所有录音都有一定程度的噪声,而未经处理的噪音可能会破坏语音识别应用程序的准确性。
通过尝试转录效果并不好,我们可以通过尝试调用 Recognizer 类的adjust_for_ambient_noise()命令。
麦克风的使用
若要使用 SpeechRecognizer 访问麦克风则必须安装 PyAudio 软件包。
如果使用的是基于 Debian的Linux(如 Ubuntu ),则可使用 apt 安装 PyAudio:sudo apt-get install python-pyaudio python3-pyaudio安装完成后可能仍需要启用 pip3 install pyaudio ,尤其是在虚拟情况下运行。
在安装完pyaudio的情况下可以通过python实现语音录入生成相关文件。
pocketsphinx的使用注意:
支持文件格式:wav
音频文件的解码要求:16KHZ,单声道
利用python实现录音并生成相关文件程序代码如下:
from pyaudio import PyAudio, paInt16
import numpy as np
import wave
class recoder:
NUM_SAMPLES = 2000
SAMPLING_RATE = 16000
LEVEL = 500
COUNT_NUM = 20
SAVE_LENGTH = 8
Voice_String = []
def savewav(self,filename):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
wf.close()
def recoder(self):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True,frames_per_buffer=self.NUM_SAMPLES)
save_count = 0
save_buffer = []
while True:
string_audio_data = stream.read(self.NUM_SAMPLES)
audio_data = np.fromstring(string_audio_data, dtype=np.short)
large_sample_count = np.sum(audio_data > self.LEVEL)
print(np.max(audio_data))
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
if save_count < 0:
save_count = 0
if save_count > 0:
save_buffer.append(string_audio_data )
else:
if len(save_buffer) > 0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
else:
return False
if __name__ == "__main__":
r = recoder()
r.recoder()
r.savewav("test.wav")注意:在利用python解释器实现时一定要注意空格!!!
最后生成的文件就在Python解释器回话所在目录下,可以通过play来播放测试一下,如果没有安装play可以通过apt命令来安装。
中文的语音识别
在进行完以前的工作以后,我们对语音识别的流程大概有了一定的了解,但是作为一个中国人总得做一个中文的语音识别吧!
我们要在CMU Sphinx语音识别工具包里面下载对应的普通话升学和语言模型。
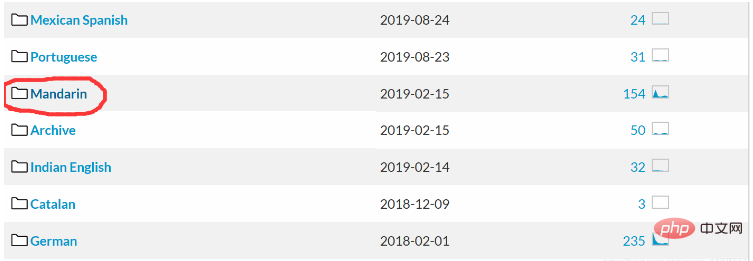
图片中标记的就是普通话!下载相关的语音识别工具包。
但是我们要把zh_broadcastnews_64000_utf8.DMP转化成language-model.lm.bin,再解压zh_broadcastnews_16k_ptm256_8000.tar.bz2得到zh_broadcastnews_ptm256_8000文件夹。
借鉴刚才那位博主的方法,在Ubuntu下找到speech_recognition文件夹。可能会有很多小伙伴找不到相关的文件夹,其实是在隐藏文件下。大家可以点击文件夹右上角的三条杠。如下图所示:

然后给显示隐藏文件打个勾,如下图所示:
然后依次按照以下目录就可以找到啦:

然后把原来的en-US改名成en-US-bak,新建一个文件夹en-US,把解压出来的zh_broadcastnews_ptm256_8000改成acoustic-model,把chinese.lm.bin改成language-model.lm.bin,把pronounciation-dictionary.dic改后缀成dict,复制这三个文件到en-US里。同时把原来en-US文件目录下的LICENSE.txt复制到现在的文件夹下。
最终该文件夹下有以下文件:
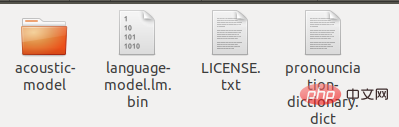
然后我们就可以通过麦克风录入一个语音文件文件(“test.wav”)
在该文件目录下打开python解释器输入以下内容:
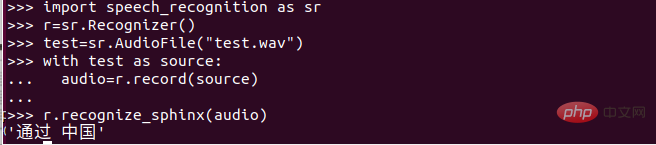
就看到了输出内容,但是我说的是两个中国,也测试了一下其他的发现识别效果很不好!!!
小范围中文识别
用官方提供的效果太差,几乎不能用!那么我看了很多文章以后就想到了一种优化方法,但是只适合小范围的识别!一些命令啥的应该没有问题,但是聊天什么的可能就效果不太好。
找到刚才复制的4个文件夹,有一个pronounciation-dictionary.dict的文件夹,打开以后是以下内容:

感觉这内容就是类似于一个字典,很多用词和平时交流的用词差距比较大。那么我们改成我们习惯的用词就可以啦! 抱着试一试的想法,结果还真的可以。识别效果真的不错!
我的做法是:
(1)把图片中红色标记以上的内容继续保留,红色以下的内容删除掉。当然处于保险考虑建议大家给该文件备份一下!
(2)给红色线以下输入自己想识别的内容!(按照规则输入,不同于拼音!!!)最近新型肺炎的情况不断的变好,听到最多的一句话就是“中国加油”那么今天的内容就是将“中国加油”实现语音转文字!希望能早日开学,哈哈哈哈。

3)输入以下内容:
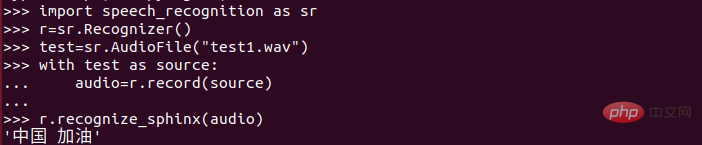
语音合成
语音合成个人的理解就是文字转语音。不过这句话中可以设置client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5,'spd': 3,'pit':9,'per': 3})音量、声调、速度、男/女/萝莉/逍遥。
以上是Linux下怎么用python实现语音识别功能的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 vscode需要什么电脑配置
Apr 15, 2025 pm 09:48 PM
vscode需要什么电脑配置
Apr 15, 2025 pm 09:48 PM
VS Code 系统要求:操作系统:Windows 10 及以上、macOS 10.12 及以上、Linux 发行版处理器:最低 1.6 GHz,推荐 2.0 GHz 及以上内存:最低 512 MB,推荐 4 GB 及以上存储空间:最低 250 MB,推荐 1 GB 及以上其他要求:稳定网络连接,Xorg/Wayland(Linux)
 vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
VS Code 扩展存在恶意风险,例如隐藏恶意代码、利用漏洞、伪装成合法扩展。识别恶意扩展的方法包括:检查发布者、阅读评论、检查代码、谨慎安装。安全措施还包括:安全意识、良好习惯、定期更新和杀毒软件。
 vscode 可以在 mac 上吗
Apr 15, 2025 pm 07:45 PM
vscode 可以在 mac 上吗
Apr 15, 2025 pm 07:45 PM
VS Code 在 macOS 上表现良好,可提升开发效率。安装和配置步骤包括:安装 VS Code 并进行配置。安装特定语言的扩展(如 JavaScript 的 ESLint)。谨慎安装扩展,避免过多导致启动变慢。学习基本功能,如 Git 集成、终端和调试器。设置合适的主题和代码字体。注意潜在问题:扩展兼容性、文件权限等。
 vscode用的是什么语言
Apr 15, 2025 pm 11:03 PM
vscode用的是什么语言
Apr 15, 2025 pm 11:03 PM
Visual Studio Code (VSCode) 由 Microsoft 开发,使用 Electron 框架构建,主要以 JavaScript 编写。它支持广泛的编程语言,包括 JavaScript、Python、C 、Java、HTML、CSS 等,并且可以通过扩展程序添加对其他语言的支持。
 Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python:自动化,脚本和任务管理
Apr 16, 2025 am 12:14 AM
Python在自动化、脚本编写和任务管理中表现出色。1)自动化:通过标准库如os、shutil实现文件备份。2)脚本编写:使用psutil库监控系统资源。3)任务管理:利用schedule库调度任务。Python的易用性和丰富库支持使其在这些领域中成为首选工具。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
 vs code 可以运行 python 吗
Apr 15, 2025 pm 08:21 PM
vs code 可以运行 python 吗
Apr 15, 2025 pm 08:21 PM
是的,VS Code 可以运行 Python 代码。为在 VS Code 中高效运行 Python,请完成以下步骤:安装 Python 解释器并配置环境变量。安装 VS Code 中的 Python 扩展。通过命令行在 VS Code 的终端中运行 Python 代码。利用 VS Code 的调试功能和代码格式化来提高开发效率。采用良好的编程习惯并使用性能分析工具优化代码性能。
 vscode运行任务快捷键
Apr 15, 2025 pm 09:39 PM
vscode运行任务快捷键
Apr 15, 2025 pm 09:39 PM
在 VSCode 中运行任务:创建 tasks.json 文件,指定 version 和任务列表;配置任务的 label、command、args 和 type;保存并重新加载任务;使用快捷键 Ctrl Shift B (macOS 为 Cmd Shift B) 运行任务。
