

训练提速17%,第四范式开源强化学习研究框架,支持单、多智能体训练

OpenRL 是由第四范式强化学习团队开发的基于 PyTorch 的强化学习研究框架,支持单智能体、多智能体、自然语言等多种任务的训练。OpenRL 基于 PyTorch 进行开发,目标是为强化学习研究社区提供一个简单易用、灵活高效、可持续扩展的平台。目前,OpenRL 支持的特性包括:
- 简单易用且支持单智能体、多智能体训练的通用接口
- 支持自然语言任务(如对话任务)的强化学习训练
- 支持从 Hugging Face 上导入模型和数据
- 支持 LSTM,GRU,Transformer 等模型
- 支持多种训练加速,例如:自动混合精度训练,半精度策略网络收集数据等
- 支持用户自定义训练模型、奖励模型、训练数据以及环境
- 支持 gymnasium 环境
- 支持字典观测空间
- 支持 wandb,tensorboardX 等主流训练可视化工具
- 支持环境的串行和并行训练,同时保证两种模式下的训练效果一致
- 中英文文档
- 提供单元测试和代码覆盖测试
- 符合 Black Code Style 和类型检查
目前,OpenRL 已经在 GitHub 开源:
项目地址:https://github.com/OpenRL-Lab/openrl
OpenRL 初体验
OpenRL 目前可以通过 pip 进行安装:
<code>pip install openrl</code>
也可以通过 conda 安装:
<code>conda install -c openrl openrl</code>
OpenRL 为强化学习入门用户提供了简单易用的接口, 下面是一个使用 PPO 算法训练 CartPole 环境的例子:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make ("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为 9net = Net (env) # 创建神经网络agent = Agent (net) # 初始化智能体agent.train (total_time_steps=20000) # 开始训练,并设置环境运行总步数为 20000</code>使用 OpenRL 训练智能体只需要简单的四步:创建环境 => 初始化模型 => 初始化智能体 => 开始训练!
在普通笔记本电脑上执行以上代码,只需要几秒钟,便可以完成该智能体的训练:
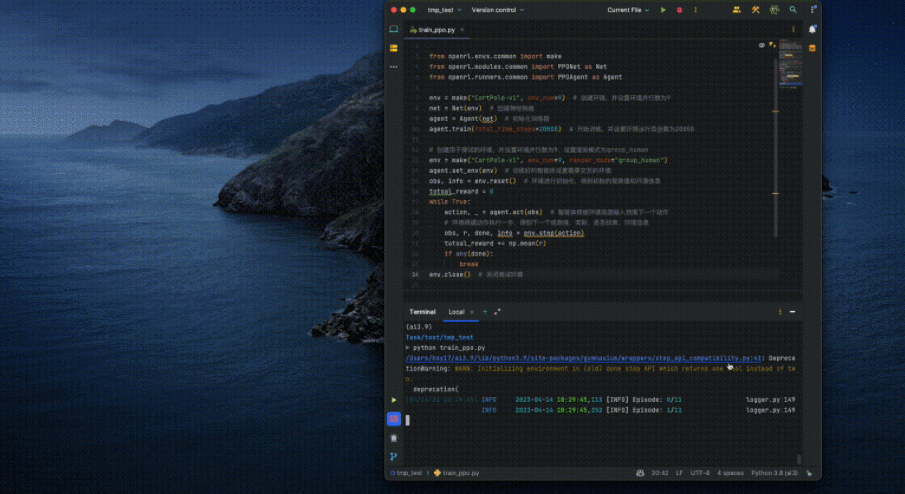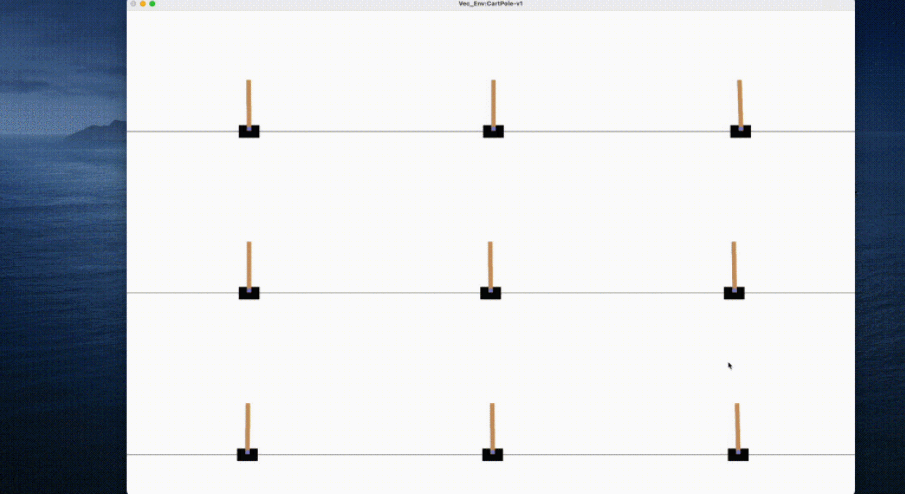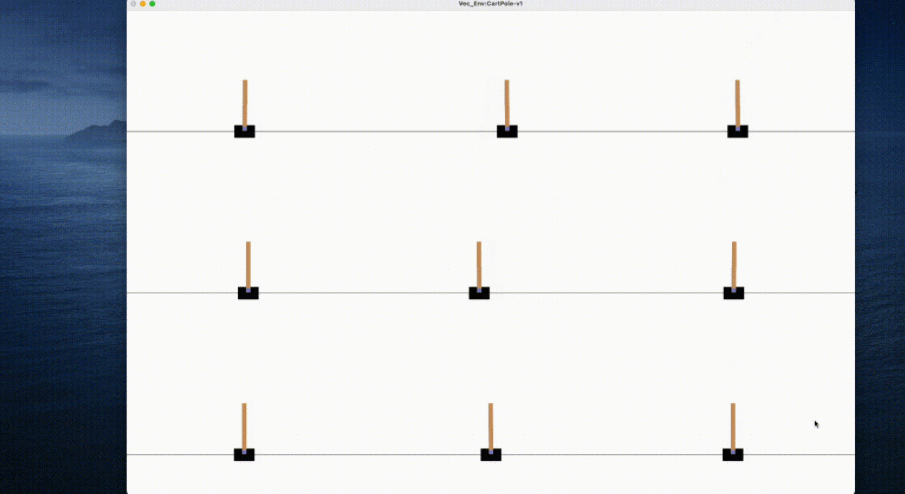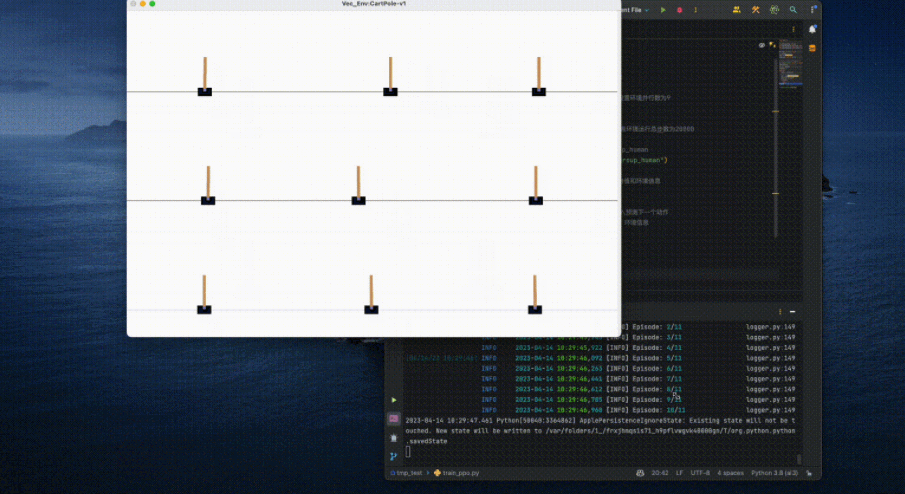
此外,对于多智能体、自然语言等任务的训练,OpenRL 也提供了同样简单易用的接口。例如,对于多智能体任务中的 MPE 环境,OpenRL 也只需要调用几行代码便可以完成训练:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train ():# 创建 MPE 环境,使用异步环境,即每个智能体独立运行env = make ("simple_spread",env_num=100,asynchrnotallow=True,)# 创建 神经网络,使用 GPU 进行训练net = Net (env, device="cuda")agent = Agent (net) # 初始化训练器# 开始训练agent.train (total_time_steps=5000000)# 保存训练完成的智能体agent.save ("./ppo_agent/")if __name__ == "__main__":train ()</code>下图展示了通过 OpenRL 训练前后智能体的表现:
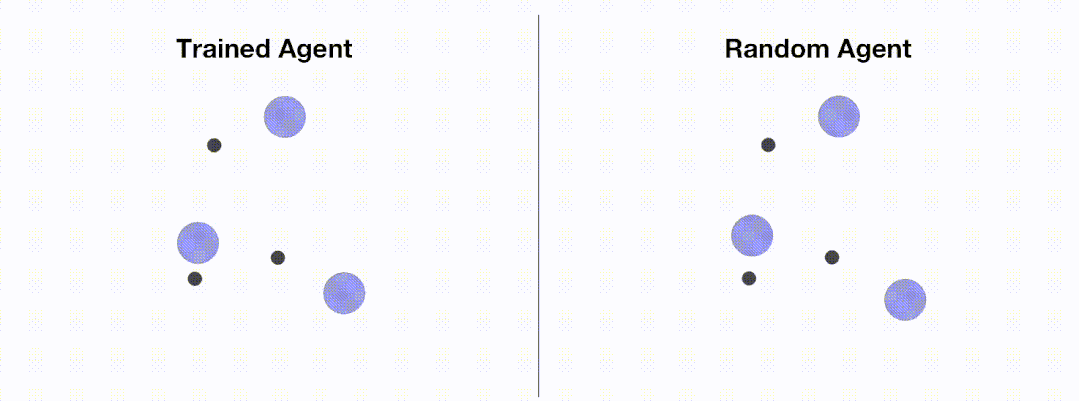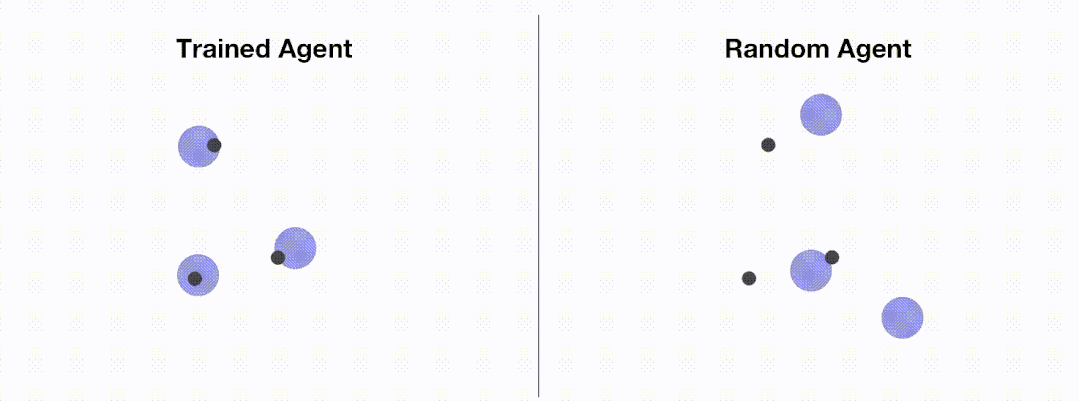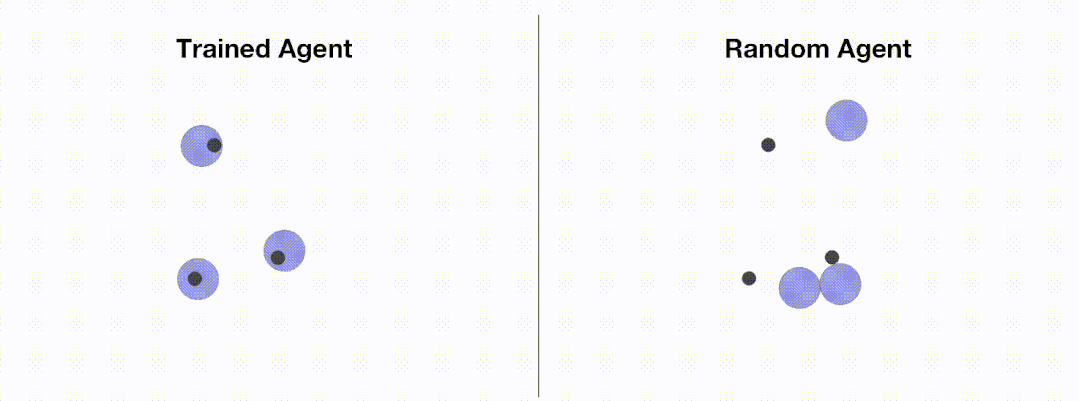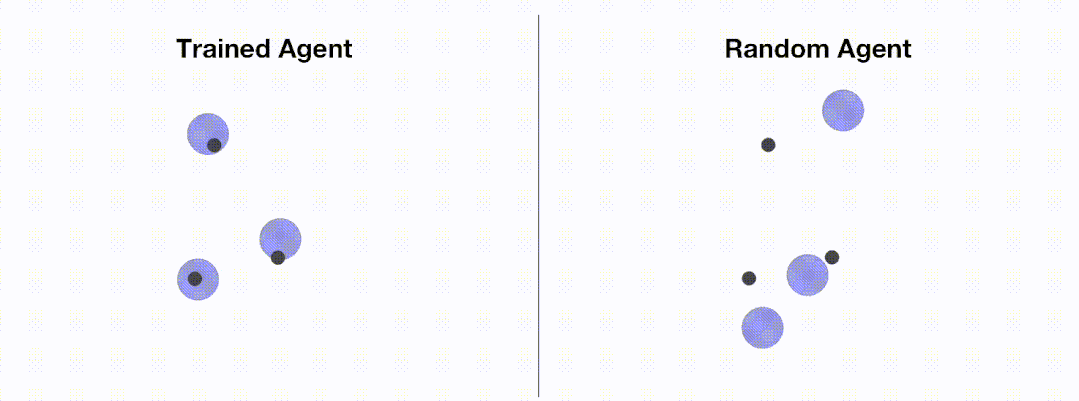
加载配置文件
此外,OpenRL 还同时支持从命令行和配置文件对训练参数进行修改。比如,用户可以通过执行 python train_ppo.py --lr 5e-4 来快速修改训练时候的学习率。
当配置参数非常多的时候,OpenRL 还支持用户编写自己的配置文件来修改训练参数。例如,用户可以自行创建以下配置文件 (mpe_ppo.yaml),并修改其中的参数:
<code># mpe_ppo.yamlseed: 0 # 设置 seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个 episode 的长度use_recurrent_policy: true # 设置是否使用 RNNuse_joint_action_loss: true # 设置是否使用 JRPO 算法use_valuenorm: true # 设置是否使用 value normalization</code>
最后,用户只需要在执行程序的时候指定该配置文件即可:
<code>python train_ppo.py --config mpe_ppo.yaml</code>
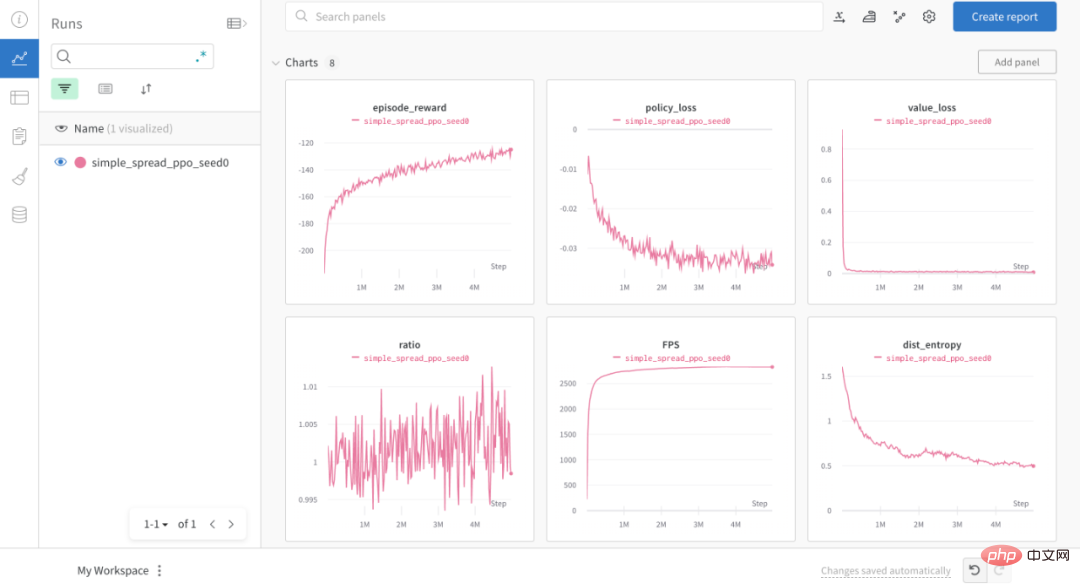
训练与测试可视化
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程:
OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为 "group_human",便可以同时对多个并行环境进行可视化:
<code>env = make ("simple_spread", env_num=9, render_mode="group_human")</code>此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画:
<code>from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper (env, "test_simple_spread.gif")</code>
智能体的保存和加载
OpenRL 提供 agent.save () 和 agent.load () 接口来保存和加载训练好的智能体,并通过 agent.act () 接口来获取测试时的智能体动作:
<code># test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成 gifdef test ():# 创建 MPE 环境env = make ( "simple_spread", env_num=4)# 使用 GIFWrapper,用于生成 gifenv = GIFWrapper (env, "test_simple_spread.gif")agent = Agent (Net (env)) # 创建 智能体# 保存智能体agent.save ("./ppo_agent/")# 加载智能体agent.load ('./ppo_agent/')# 开始测试obs, _ = env.reset ()while True:# 智能体根据 observation 预测下一个动作action, _ = agent.act (obs)obs, r, done, info = env.step (action)if done.any ():breakenv.close ()if __name__ == "__main__":test ()</code>执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):

训练自然语言对话任务
最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户加载自己的数据集 ,自定义训练模型,自定义奖励模型,自定义 wandb 信息输出以及一键开启混合精度训练等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)net = Net (env, cfg=cfg, device="cuda")agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
加载自定义数据集
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
<code># nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径seed: 0 # 设置 seed,保证每次实验结果一致lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 20 # 设置每个 episode 的长度use_recurrent_policy: true</code>上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称或者本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称或者本地路径。
自定义训练模型
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
<code># nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo 训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 128 # 设置每个 episode 的长度num_mini_batch: 20</code>然后在 train_ppo.py 中添加以下代码:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import (PolicyValueNetworkGPT as PolicyValueNetwork,)def train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)# 创建自定义神经网络model_dict = {"model": PolicyValueNetwork}net = Net (env, cfg=cfg, model_dict=model_dict)# 创建训练智能体agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
<code>model_dict = {"policy": CustomPolicyNetwork,"critic": CustomValueNetwork,}net = Net (env, model_dict=model_dict)</code>自定义奖励模型
通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
<code># nlp_ppo.yamlreward_class:id: NLPReward # 奖励模型名称args: {# 用于意图判断的模型的名称或路径"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,# 用于计算 KL 散度的预训练模型的名称或路径"ref_model": roberta-base, # 用于意图判断的 tokenizer 的名称或路径}</code>OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
<code># train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register ("CustomReward", CustomReward)</code>最后,用户只需要在配置文件中填写自定义的奖励模型即可:
<code>reward_class:id: "CustomReward" # 自定义奖励模型名称args: {} # 用户自定义奖励函数可能用到的参数</code>自定义训练过程信息输出
OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
<code># nlp_ppo.yamlvec_info_class:id: "NLPVecInfo" # 调用 NLPVecInfo 类以打印 NLP 任务中奖励函数的信息# 设置 wandb 信息wandb_entity: openrl # 这里用于指定 wandb 团队名称,请把 openrl 替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个 episode 上传一次 wandb 数据# 自行填写其他参数...</code>
修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
<code># train_ppo.pyagent.train (total_time_steps=100000, use_wandb=True)</code>
然后执行 python train_ppo.py –config nlp_ppo.yaml,稍后,便可以在 wandb 中看到如下的输出:
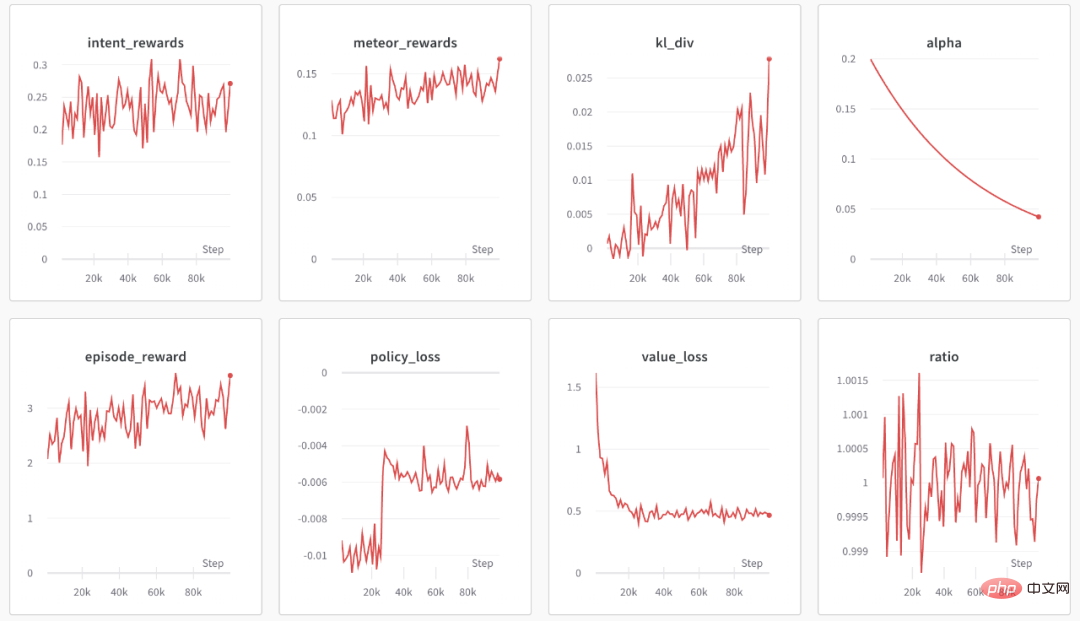
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
<code># train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register ("CustomVecInfo", CustomVecInfo)</code>最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
<code># nlp_ppo.yamlvec_info_class:id: "CustomVecInfo" # 调用自定义 CustomVecInfo 类以输出自定义信息</code>
使用混合精度训练加速
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
<code># nlp_ppo.yamluse_amp: true # 开启混合精度训练</code>
对比评测
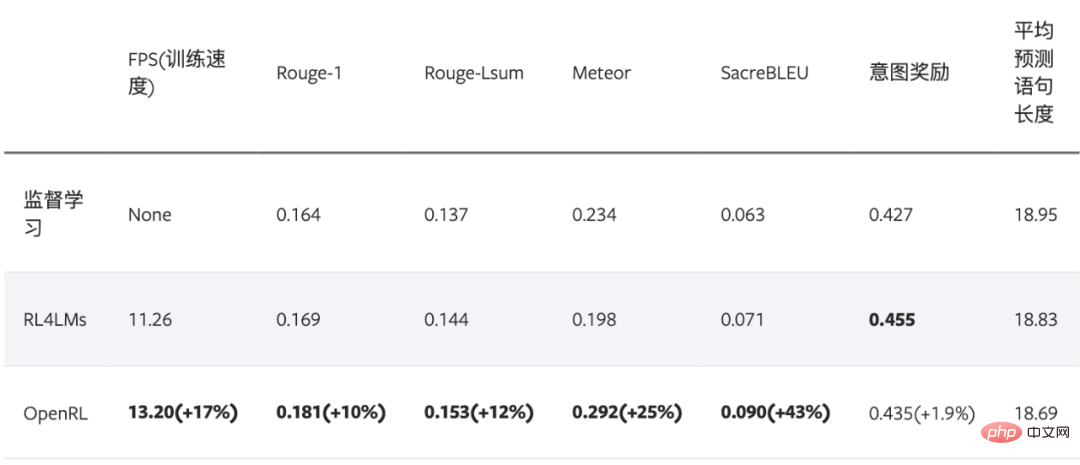
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
最后,对于训练好的智能体,用户可以方便地通过 agent.chat () 接口进行对话:
<code># chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat ():agent = Agent.load ("./ppo_agent", tokenizer="gpt2",)history = []print ("Welcome to OpenRL!")while True:input_text = input ("> User:")if input_text == "quit":breakelif input_text == "reset":history = []print ("Welcome to OpenRL!")continueresponse = agent.chat (input_text, history)print (f"> OpenRL Agent: {response}")history.append (input_text)history.append (response)if __name__ == "__main__":chat ()</code>执行 python chat.py ,便可以和训练好的智能体进行对话了:

总结
OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
- OpenRL 官方仓库:https://github.com/OpenRL-Lab/openrl/
- OpenRL 中文文档:https://openrl-docs.readthedocs.io/zh/latest/
致谢
OpenRL 框架的开发吸取了其他强化学习框架的优点:
- Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c-ppo-acktr-gail:https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
- MAPPO: https://github.com/marlbenchmark/on-policy
- Gymnasium: https://github.com/Farama-Foundation/Gymnasium
- DI-engine:https://github.com/opendilab/DI-engine/
- Tianshou: https://github.com/thu-ml/tianshou
- RL4LMs: https://github.com/allenai/RL4LMs
未来工作
目前,OpenRL 还处于持续开发和建设阶段,未来 OpenRL 将会开源更多功能:
- 支持智能体自博弈训练
- 加入离线强化学习、模范学习、逆强化学习算法
- 加入更多强化学习环境和算法
- 集成 Deepspeed 等加速框架
- 支持多机分布式训练
OpenRL Lab 团队
OpenRL框架是由OpenRL Lab团队开发,该团队是第四范式公司旗下的强化学习研究团队。第四范式长期致力于强化学习的研发和工业应用。为了促进强化学习的产学研一体化,第四范式成立了OpenRL Lab研究团队,目标是先进技术开源和人工智能前沿探索。成立不到一年,OpenRL Lab团队已经在AAMAS发表过三篇论文,参加谷歌足球游戏 11 vs 11比赛并获得第三的成绩。团队提出的TiZero智能体,实现了首个从零开始,通过课程学习、分布式强化学习、自博弈等技术完成谷歌足球全场游戏智能体的训练:
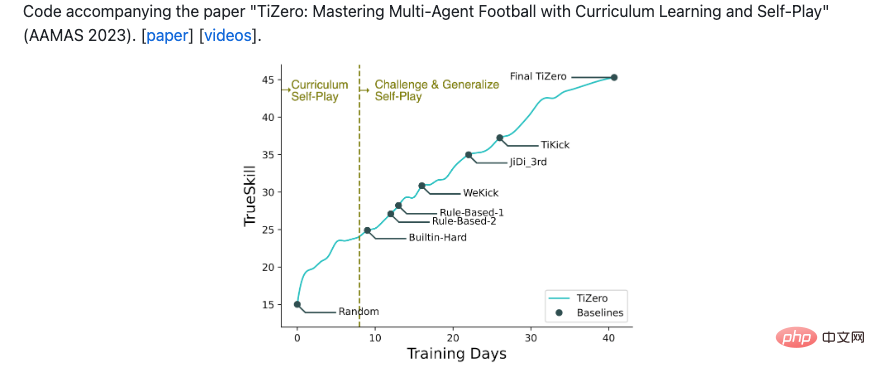
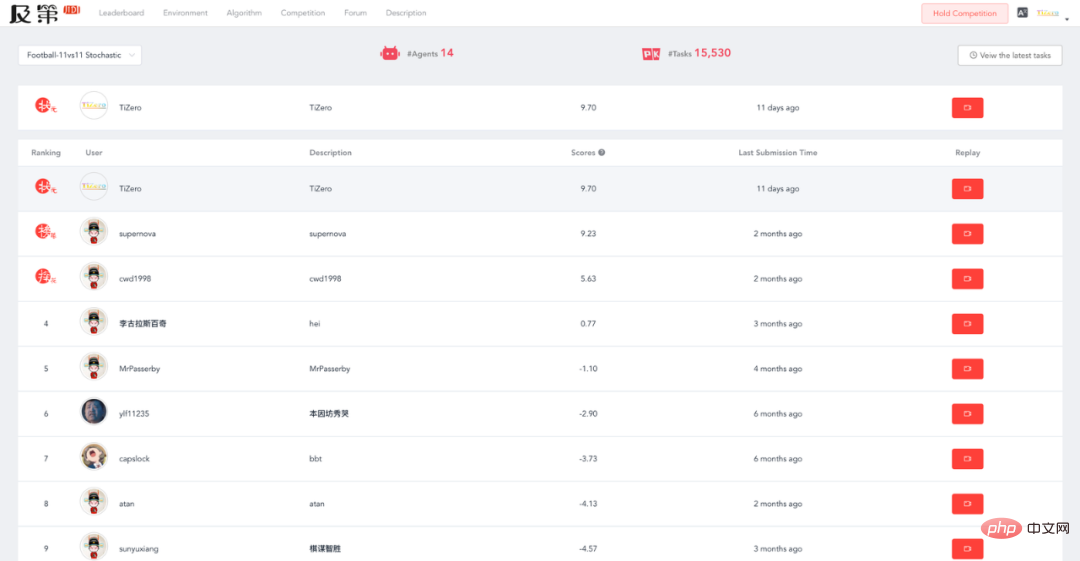
截止 2022 年 10 月 28 日,Tizero 在及第评测平台上排名第一:
以上是训练提速17%,第四范式开源强化学习研究框架,支持单、多智能体训练的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 四款值得推荐的AI辅助编程工具
Apr 22, 2024 pm 05:34 PM
四款值得推荐的AI辅助编程工具
Apr 22, 2024 pm 05:34 PM
这个AI辅助编程工具在这个AI迅速发展的阶段,挖掘出了一大批好用的AI辅助编程工具。AI辅助编程工具能够提高开发效率、改善代码质量、降低bug率,是现代软件开发过程中的重要助手。今天大姚给大家分享4款AI辅助编程工具(并且都支持C#语言),希望对大家有所帮助。https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot是一款AI编码助手,可帮助你更快、更省力地编写代码,从而将更多精力集中在问题解决和协作上。Git
 AI程序员哪家强?探索Devin、通义灵码和SWE-agent的潜力
Apr 07, 2024 am 09:10 AM
AI程序员哪家强?探索Devin、通义灵码和SWE-agent的潜力
Apr 07, 2024 am 09:10 AM
2022年3月3日,距世界首个AI程序员Devin诞生不足一个月,普林斯顿大学的NLP团队开发了一个开源AI程序员SWE-agent。它利用GPT-4模型在GitHub存储库中自动解决问题。SWE-agent在SWE-bench测试集上的表现与Devin相似,平均耗时93秒,解决了12.29%的问题。SWE-agent通过与专用终端交互,可以打开、搜索文件内容,使用自动语法检查、编辑特定行,以及编写和执行测试。(注:以上内容为原内容微调,但保留了原文中的关键信息,未超过指定字数限制。)SWE-A
 学习如何利用Go语言开发移动应用程序
Mar 28, 2024 pm 10:00 PM
学习如何利用Go语言开发移动应用程序
Mar 28, 2024 pm 10:00 PM
Go语言开发移动应用程序教程随着移动应用市场的不断蓬勃发展,越来越多的开发者开始探索如何利用Go语言开发移动应用程序。作为一种简洁高效的编程语言,Go语言在移动应用开发中也展现出了强大的潜力。本文将详细介绍如何利用Go语言开发移动应用程序,并附上具体的代码示例,帮助读者快速入门并开始开发自己的移动应用。一、准备工作在开始之前,我们需要准备好开发环境和工具。首
 五大热门Go语言库汇总:开发必备利器
Feb 22, 2024 pm 02:33 PM
五大热门Go语言库汇总:开发必备利器
Feb 22, 2024 pm 02:33 PM
五大热门Go语言库汇总:开发必备利器,需要具体代码示例Go语言自从诞生以来,受到了广泛的关注和应用。作为一门新兴的高效、简洁的编程语言,Go的快速发展离不开丰富的开源库的支持。本文将介绍五大热门的Go语言库,这些库在Go开发中扮演了至关重要的角色,为开发者提供了强大的功能和便捷的开发体验。同时,为了更好地理解这些库的用途和功能,我们会结合具体的代码示例进行讲
 Android开发最适合的Linux发行版是哪个?
Mar 14, 2024 pm 12:30 PM
Android开发最适合的Linux发行版是哪个?
Mar 14, 2024 pm 12:30 PM
Android开发是一项繁忙而又令人兴奋的工作,而选择一个适合的Linux发行版来进行开发则显得尤为重要。在众多的Linux发行版中,究竟哪一个最适合Android开发呢?本文将从几个方面来探讨这一问题,并给出具体的代码示例。首先,我们来看一下目前流行的几个Linux发行版:Ubuntu、Fedora、Debian、CentOS等,它们都有各自的优点和特点。
 Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言前端技术探秘:前端开发新视野
Mar 28, 2024 pm 01:06 PM
Go语言作为一种快速、高效的编程语言,在后端开发领域广受欢迎。然而,很少有人将Go语言与前端开发联系起来。事实上,使用Go语言进行前端开发不仅可以提高效率,还能为开发者带来全新的视野。本文将探讨使用Go语言进行前端开发的可能性,并提供具体的代码示例,帮助读者更好地了解这一领域。在传统的前端开发中,通常会使用JavaScript、HTML和CSS来构建用户界面
 了解VSCode:这款工具到底是用来干什么的?
Mar 25, 2024 pm 03:06 PM
了解VSCode:这款工具到底是用来干什么的?
Mar 25, 2024 pm 03:06 PM
《了解VSCode:这款工具到底是用来干什么的?》作为一个程序员,无论是初学者还是资深开发者,都离不开代码编辑工具的使用。在众多编辑工具中,VisualStudioCode(简称VSCode)作为一款开源、轻量级、强大的代码编辑器备受开发者欢迎。那么,VSCode到底是用来干什么的?本文将深入探讨VSCode的功能和用途,并提供具体的代码示例,以帮助读者
 全面指南:详解Java虚拟机安装过程
Jan 24, 2024 am 09:02 AM
全面指南:详解Java虚拟机安装过程
Jan 24, 2024 am 09:02 AM
Java开发必备:详细解读Java虚拟机安装步骤,需要具体代码示例随着计算机科学和技术的发展,Java语言已成为广泛使用的编程语言之一。它具有跨平台、面向对象等优点,逐渐成为开发人员的首选语言。在使用Java进行开发之前,首先需要安装Java虚拟机(JavaVirtualMachine,JVM)。本文将详细解读Java虚拟机的安装步骤,并提供具体的代码示
